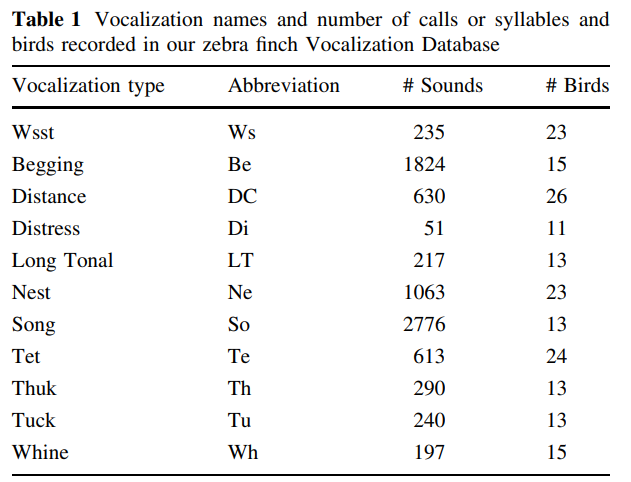
I’m working on adding another audio dataset to fastai2. It has 3405 zebra finch calls and songs collected from 45 zebra finches (18 chicks and 27 adults). Each vocalization has been assigned to one of 11 call types.
This is likely a much more challenging dataset than the one we worked on earlier.
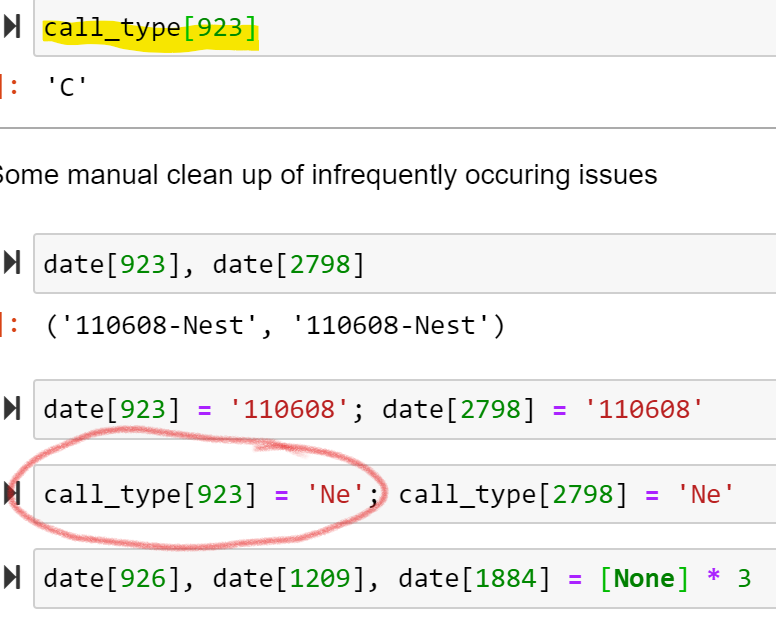
I am currently working on cleaning up the labeling. Calls were annotated manually (by multiple researchers typing in the file name). This has led to several inconsistencies.
I have fixed most of them but a major one remains - there should only be 11 distinct labels but there are 33! Different annotators adopted different conventions. What is more concerning, some of the labels are ambiguous.
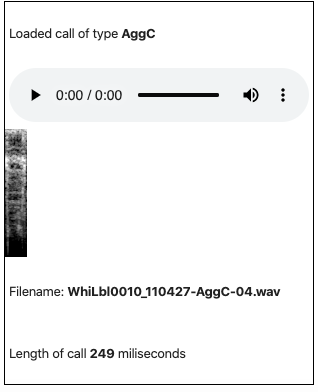
Here is a voila app hosted on [https://mybinder.org/] I created to play the recordings to help with relabeling. The source code can be found here.
Here is the original paper that analyzes the data.
Task #1
Out of the ambiguous labels ThuC, ThuckC, ThukC, TukC can you infer which map to Thuk and which to Tuck (these are correct label names)?
Could you please post your guesses below? This would be very helpful. If you do, ideally please work on the task before looking at the guesses by other people.
Task #2
Can you assign the call types in the dataset to one of the correct labels? You can submit your guesses using the following template.
type2labels = {
'Ag': ['example_label', 'example_label2'],
'Be': [],
'DC': [],
'Di': [],
'LT': [],
'Ne': [],
'So': [],
'Te': [],
'Th': [],
'Tu': [],
'Wh': []
}
Task #3
Can you add useful functionality to the voila app? For instance, maybe it would be helpful to see the spectrograms? Or maybe people using this application would feel more engaged with the task if they were greeted with an image of a zebra finch? How about including a set of zebra finch images and reloading it every x seconds?
Task #4 (tricky)
In processing of the data, there are 14 vocalizations labeled both as ‘chick’ and ‘adult’. Not knowing which class they belong to, I removed them. But can you somehow infer which is the correct label? Can you do so by listening to the calls? Or would some information from the paper be helpful?
Task #5 (advanced)
Can you run a clustering algorithm or one reducing dimensionality on this data? Is there a way of using this information, obtained in an unsupervised way, to reason about which examples may have been misclassified?
Task #6 (advanced)
With the initially corrected labels, can you train a model and see what calls it is least confident about? Could they potentially be misclassified in the dataset?
If you get any results on either of the tasks, please consider submitting a PR to the repo. Would be great if others could learn from your work 
The plan is to clean this dataset so that we can practice more advanced methods of classifying audio, similarly to what we are doing in this thread (this dataset should be much more challenging).
FAQ
1. Why this initiative?
Quite often threads would pop up where people are struggling with finding ways to practice the materials in the lecture. The intent behind this thread is to help in this regard. Working on something that is interesting and can be useful to others is in my experience a great way to learn. Also, this task models closely situations you will encounter in the wild.
2. Radek, is it true that you find voila and ipywidgets amazing?
Yes! But it hasn’t always been that way! Precisely, up unto a couple of days ago, I never thought I would resort to this way of creating applications. Strangely enough a situation manifested where I genuinely felt I could benefit in my work from hacking a quick application together. Luckily enough I watched lecture 3 and… voila 
3. Damn, this ipywidgets thing is confusing  . How do you make sense of it?
. How do you make sense of it?
It was super confusing to me as well! In fact, it still is. Luckily, I stumbled across the fabulous documentation for ipywidgets and read through the examples, did a couple of them along the way. I still can’t say I understand it well, but I now have some way of getting dangerous, even if through copying most of the code from the documentation and only making some minor adjustments here and there! That is precisely how we learn.