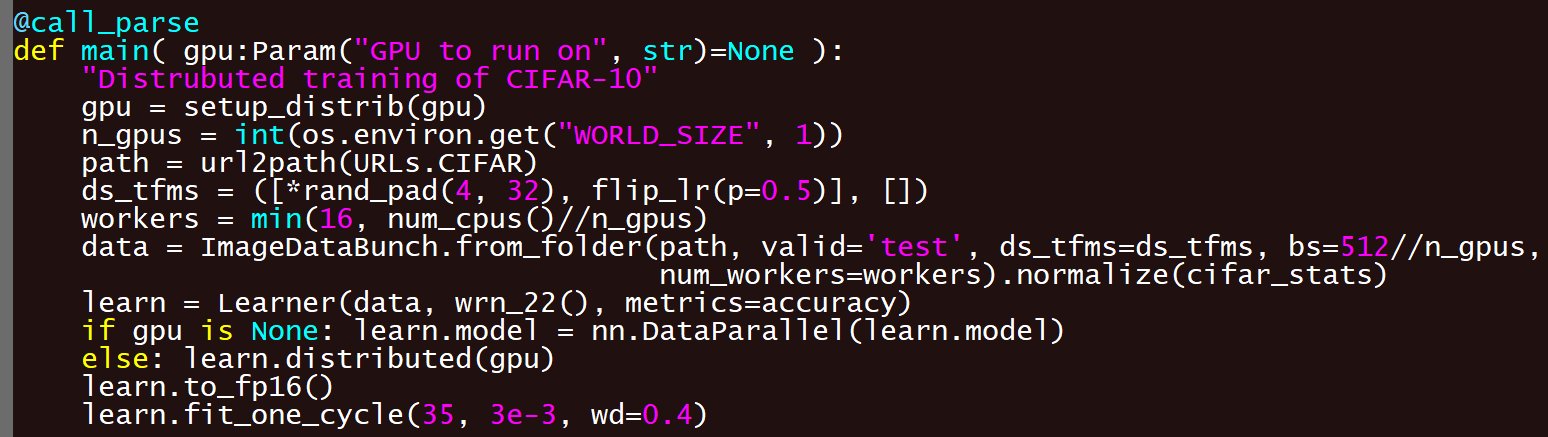
I was keep looking for hardware options with reasonable price budget in high end desktop range to connect 4 GPUs with 16x PCIe lanes each. Maybe there are server grade CPUs/MB that can do it, but the price is too high to justify.
There are these new AMD CPUs announced few months ago, that give you 64 lanes without PLX (PLX PCI switches can make inter GPU communication faster but the CPU <-> GPU link is still bottlenecked with the CPU PCIe lanes limit). So I think for 4 GPU/16x lanes each or 8 GPU/8x lanes each then AMD is your friend.
AMD Ryzen Threadripper 2990WX
32 cores/64 threads
4.2GHz boost/3.0GHz base
64MB L3 cache
250W TDP
64 PCIe Gen 3.0 lanes
Price: $1,799
Availability: Aug 13, 2018
AMD Ryzen Threadripper 2970WX
24 cores/48 threads
4.2GHz boost/3.0GHz base
64MB L3 cache
250W TDP
64 PCIe Gen 3.0 lanes
Price: $1,299
Availability: Oct 2018
AMD Ryzen Threadripper 2950X
16 cores/32 threads
4.4GHz boost/3.5GHz base
32MB L3 cache
180W TDP
64 PCIe Gen 3.0 lanes
Price: $899
Availability: Aug 31, 2018
AMD Ryzen Threadripper 2920X
12 cores/24 threads
4.3GHz boost/3.5GHz base
32MB L3 cache
180W TDP
64 PCIe Gen 3.0 lanes
Price: $649
Availability: Oct 2018
Source:
It seems intel could not (do not want?) make CPUs with 64 lanes.
For Nvidia DGX-2 with 16 GPUs they seem relying on the NVlinks between the V100s. They are using 2 Xeon processors (Dual Intel Xeon Platinum
8168, 2.7 GHz, 24-cores) each with 48 lanes (6 lanes/gpu?), but that is not a problem with NVlinks.
source:
DGX-1
2x Intel Xeon E5-2698 v3 (16 core, Haswell-EP) with 40 lanes each
8x NVIDIA Tesla P100 (3584 CUDA Cores) with NVlinks
= 10 lanes/gpu
But again there are NVlinks between the 8 P100s gpus
source:
https://www.anandtech.com/show/10229/nvidia-announces-dgx1-server
I think, only the new AMD processors can do 4 GPUs efficiently for us without server grade tesla gpus.
My question though, if we go for the cheapest AMD with 64 lanes. How is the performance and most importantly the compatibility with the DL frameworks of AMD CPUs. Like this one with $650:
AMD Ryzen Threadripper 2920X
12 cores/24 threads
4.3GHz boost/3.5GHz base
32MB L3 cache
180W TDP
64 PCIe Gen 3.0 lanes
Price: $649
Availability: Oct 2018
Saying that, I have recently purchased the newly announced corei9-9900k ($550) for building a system with 3 GPUs .
I just don’t feel comfortable to go for AMD cpus fearing of compatibility issues and lower performance for DL or other compute tasks that I am interested in (rendering, Ansys simulations…etc.)