Here are the charts:
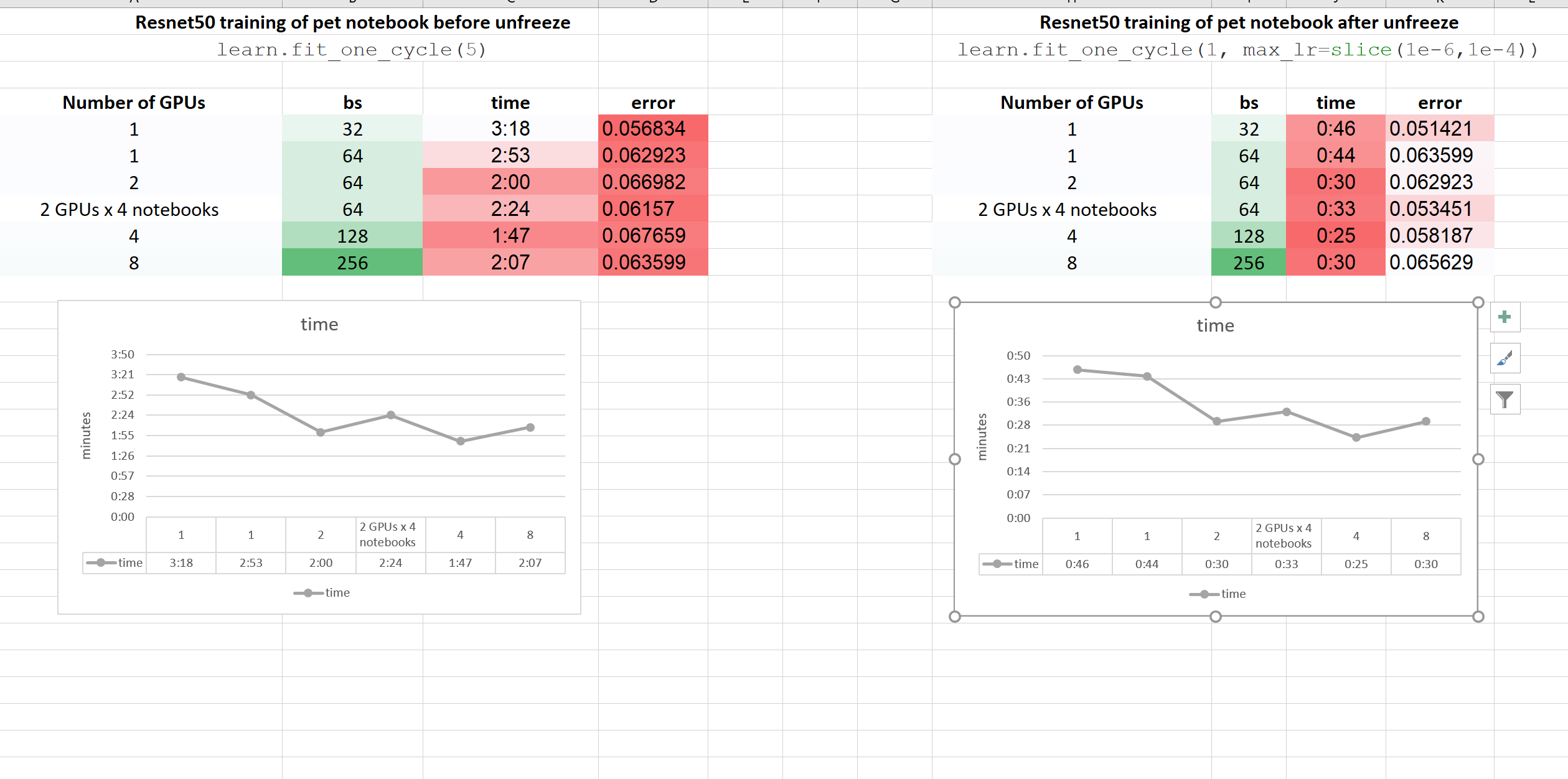
As you can see, running 4 or 8 GPUs to train one model is waste of GPUs. However training it on 2 GPUs give you around x1.5 more than 1 GPU.
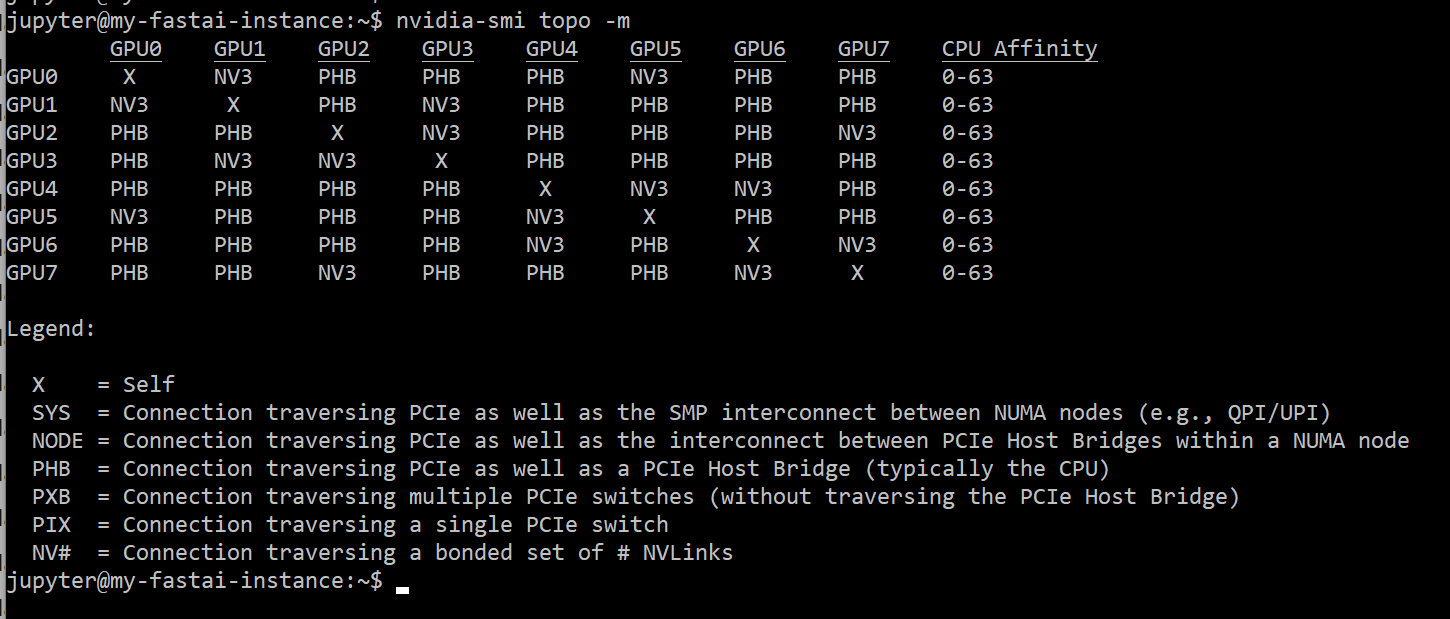
However running 4 models on 8 GPUs (each model on 2 parallel GPUs), will be fine. And this is because not all GPUs are connected together by NVlinks. PCI lanes seems not enough.
Here is the GCP V100 x 8 topology:
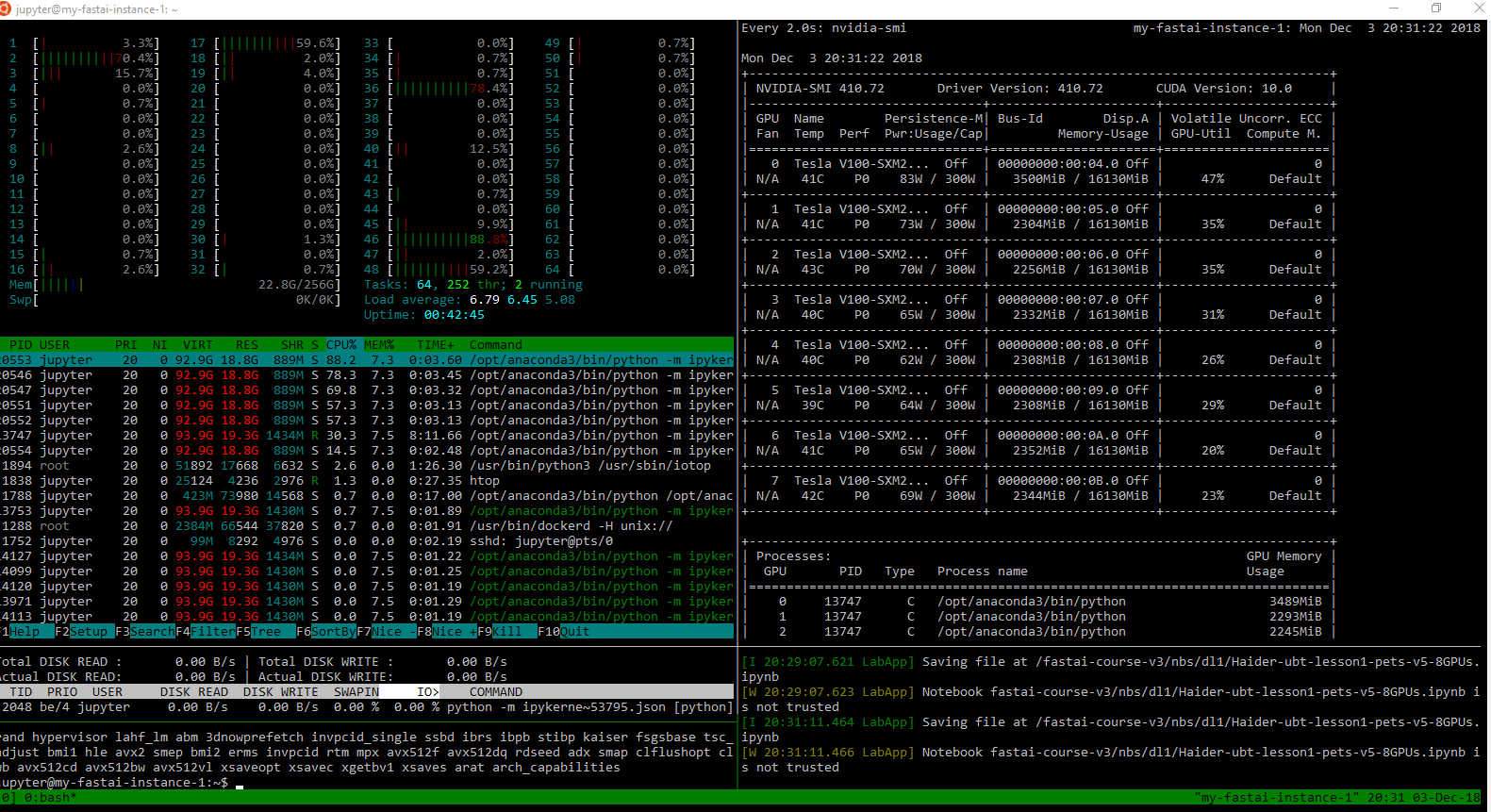
htop + nvidia-smi + iotop:
lscpu: