I can’t just “single GPU it” without doing other changes. I originally did a bs=64 with bs=bs in the IDB function. Leaving bs=64 will result in a CUDA out of memory error for a single GPU. Changing bs=32, or leaving it bs=64 but changing bs=bs//2 in the IDB function gives me that [1, 4096] type error. So, to get it to run on the single GPU, I have bs=48 and bs=bs in the IDB. It is just about done. Then I will halve the lrs in both single and dual GPU and post links. It may have to wait until morning for the official results.
For Dual GPUs:
Original Trial “Copy 1”: bs=64, error rate of 0.036760
Copy 4: dual GPU, bs=64, arbitrary halving of Copy 1 lrs gave me an error rate of 0.038802
For Single GPUs:
Copy 2: bs=48, error rate of 0.036079
Copy 5: bs=48, arbitrary halving of Copy 2 lrs gave me an error rate of 0.040163
Copy 5: bs=48, lr changed in fine tuning step based upon lr_plot gave an error rate of 0.035398
Good question! I was trying to replicate @ronaldokun results and in his one notebook link, he shows that size=320. However, I could have sworn that the official course nbs had that size value at one point or another, but I cannot find a source for that. So I guess I got lucky in the end.
Benchmarks: Training: resnet34
learn.fit_one_cycle(4): Total time: 01:47 (single gpu)
learn.fit_one_cycle(4): Total time: 01:56 (dual gpu)
after Unfreezing, fine-tuning, and learning rates
learn.fit_one_cycle(1): Total time: 00:27 (single gpu)
learn.fit_one_cycle(1): Total time: 00:27 (dual gpu)
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4)): Total time: 00:53 (single gpu)
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4)): Total time: 00:54 (dual gpu)
Training: resnet50
learn.fit_one_cycle(5): Total time: 03:11 (single gpu)
learn.fit_one_cycle(5): Total time: 03:16 (dual gpu)
after Unfreeze:
learn.fit_one_cycle(1, max_lr=slice(1e-6,1e-4)): Total time: 00:44 (single gpu)
learn.fit_one_cycle(1, max_lr=slice(1e-6,1e-4)): Total time: 00:41 (dual gpu)
As you can see in this example, running multiple gpus for resnet34 did not improve performance. It performed about the same as a single.
P.S. : I run the notebook “As-is”. For a single gpu, I change nothing. To test dual gpu, I simply added “learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])” before fitting.
To test dual gpu, I think to be fair, we should double the batch size. Otherwise as expected, there will not be any speed difference in comparison with 1 GPU run.
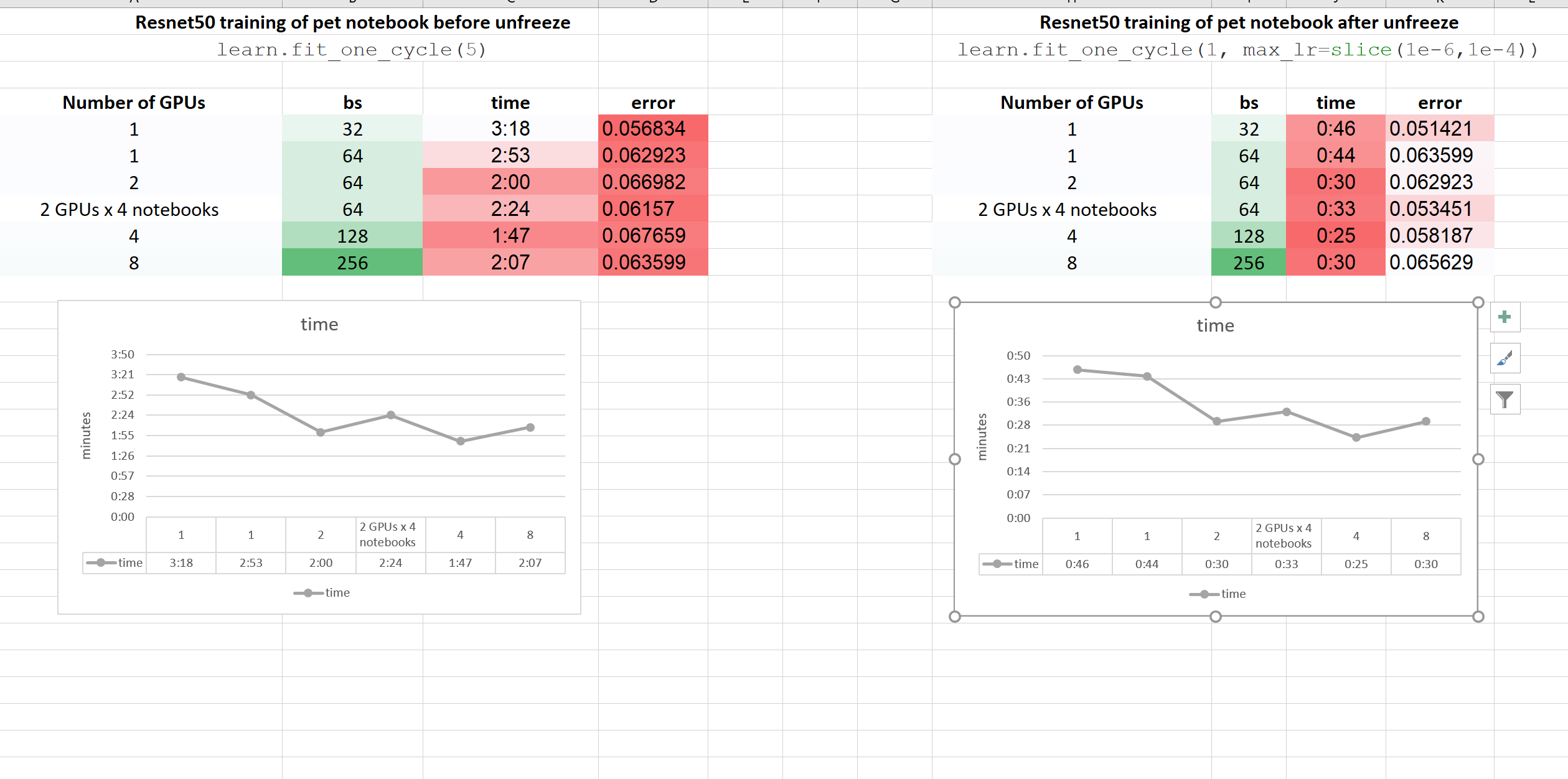
I have tested GCP instance with 8 GPUs to see the speedup that I can get by running this nb on 1, 2, 4, 8 GPUs.
I will try to make graphs for the accuracies and training time.
I have increased bs by the same ration of increasing GPU count in the test.
What I found in sum:
2 GPUs model is doing much better job in training time (almost twice the speed), with minimal decrease in accuracy.
4 GPUs model is doing as fast as 1 GPU or a little bit better (waste of GPUs)
8 GPUs model is doing as fast as 1 GPU or a little worse (waste of GPUs)
However, trying to run 4 duplicates of notebooks, each with 2 GPUs model, they have run almost the same speed each like the 2 GPUs scenario above when ran alone.
This was surprising!
I tried to max out other specs, so I will not suspect any other bottleneck.
Specs of the GCP instance:
V100 x8
256GB RAM
64 vCPU Xeon skylake
500GB SSD
Especially if we note that the V100 GPUs should be using 300GB/s NVlink2.0, so there should not have any degradation of speedup in running 4 or 8 GPUs in parallel.
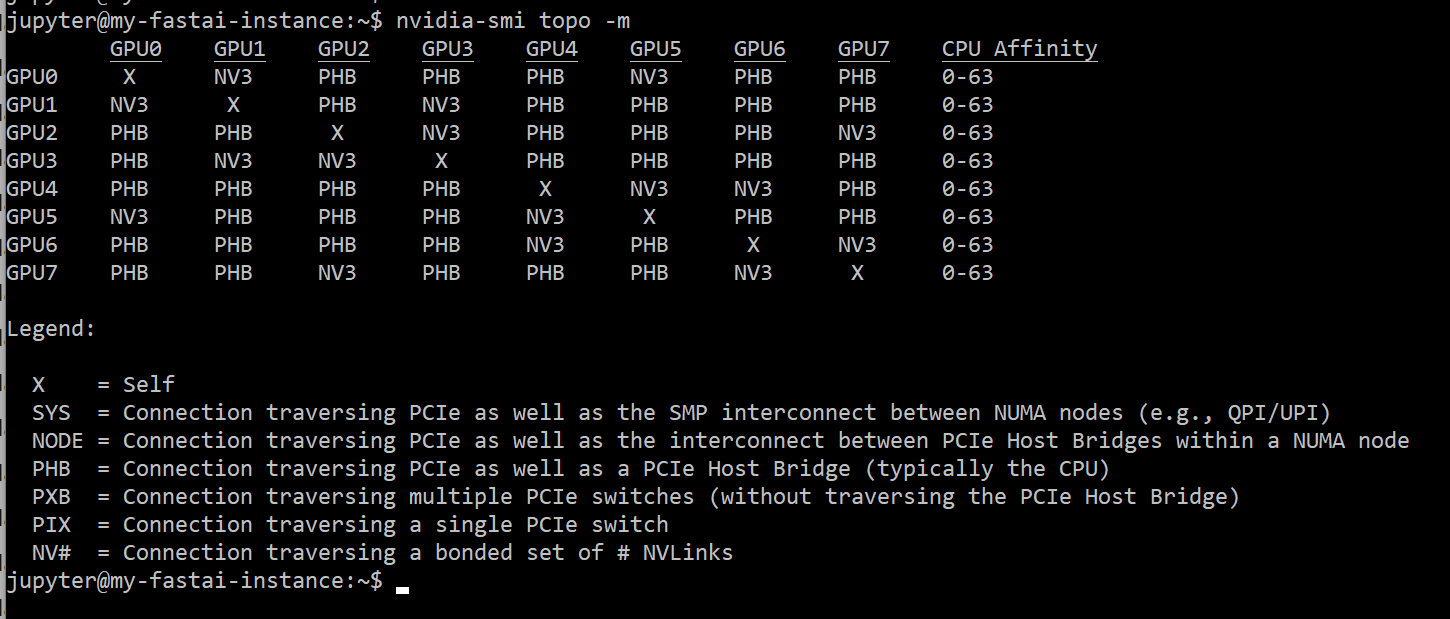
Digging deeper in the literature, I found that I can detect the topology of GPUs connected together using: nvidia-smi topo -m
which revealed that not all GPUs are connected together with NVLinks. Each V100 comes with 6 channels of NVLink v2.0 (each link = 50GB/s). The 6 links are used to connect only 2 adjacent GPUs (3 links each with 150GB/s). Unfortunately, I think the 6 NVLinks is kind of wasted in GCP. Two links between 2 GPUs (or even 1 link) would be enough for DL applications. (Maybe there are other applications that need higher NVLink connections.) Nvidia DGX 2 has used a better topology IMHO for DL.
The GPUs that are not connected through NVlink, if they have to p2p transfer data, they are using PLX PCIe switch, which is obviously not fast enough to scale training of large models on 4 or 8 GPUs.
In a later post I will share the graphs and snapshots of my mini study on running fastai models in parallel GPUs.
As you can see, running 4 or 8 GPUs to train one model is waste of GPUs. However training it on 2 GPUs give you around x1.5 more than 1 GPU.
However running 4 models on 8 GPUs (each model on 2 parallel GPUs), will be fine. And this is because not all GPUs are connected together by NVlinks. PCI lanes seems not enough.