If you run a ac power cable through a hole in the back of the box the second internal psu would be powered on just like you power on the main one vie your powerpoint/ups. Could use add2psu if dont want to use jumpers. For the messing about and extra room this takes, unless you have a really large case and spare psu lying around, easier and safer to use one.
Something im looking at right atm is to mount a psu on a bracket outside the case and use dc power cable extensions-will allow me to fit more fans in the case
My problem is that I have a Fujitsu M730 workstation. It is a very nice, sturdy workstation, with plenty of ecc ram and a 40-lanes Xeon e5 CPU.
On the other hand, the power supply and the mainboard are coupled with a 12V (non-ATX) proprietary connector, which makes it impossible to replace the PSU.
It wuould be a shame to trash such a reliable and powerful machine, so I’m interested in adding a second psu. Indeed the problem of bootstrapping both PSUs is solved with that add2psu contraption (thank you, I didn’t know it), but I wonder how much additional power consumption the second psu would add, particularly while the machine stays in idle… Has someone made experiments about that?
The watts on the PSU are the power the PSU is rated to on demand. Without load power use should be minimal - especially if you get a 80+ gold or higher efficiency. You should be able to find a good efficient one with a bit of research (I recall seeing some graphs but cant recall where). Out of curiosity which Xeon E5 did the machine come with?
Xeon e5-1650v2, six cores, Ivy Bridge-E generation. The main handicap is the power supply. Good quality, 80+ gold, the system consumes less than a mainstream quad-core, particularly in idle (it idles at ~40W). But it is 500W and has just a single 6-pin connector.
On the other hand, I had the occasion of purchasing an XFX 650W (also 80+ gold) with four 6+2 connectors, for just 65 euros. Without the burden of powering the system, I think it can easily cope with two titan-class GPU or three 1070.
My main concern is that the whole contraption will be incredibly untidy. One option would be rebuilding in a dual psu-case, which are extremely difficult to find though.
I have a coolermaster HAF 932 which supports 2x psu mount locations, havent seen any other cases that support 2 may have to get a full tower and build a bracket and just rivet in. An old machine i have has a xfx 650, only thing id note was that the output cables warent quite as long as newer psus but were still ok. Ive found dell component sizes can be non standard (mb and psu), may want to check the fujitsu ones will fit without too many mods to a new case
1 Like
Yes, indeed. The cables by fujitsu are pretty short… They do it on purpose, to prevent you from making custom mods…
I have found a dual psu case which is quite cheap: the Anidees AI8.
In case you are curious, I did it as per your advice. Two PSUs with add2psu, and a large case specifically engineered for supporting them. Also posting it here for someone else who seeks to build a multi-gpu rig with appropriate lanes and power.
The good thing is that all this contraption was not expensive (100 euros the case, 67 euros the second psu, 6 euros the add2psu).
The xeon-e5v2 workstation has been bought crap cheap from ebay.
The only expensive things were the GPUs (1080ti + 1070), for a total of almost 1200 euros. I’ll add an NVMe drive soon, and a little one slot video card to leave the two GPUs alone for DL.






2 Likes
Thats a great looking build, and probably couldnt do much better for terraflops per dollar.
Id be interested in gpu temps your getting, especially the 1080ti fe. (A blog on build specs could be useful for others looking for a relatively low cost high performance build if you have the time)
Something i noticed is that it takes a fair bit of time to plan the experiments to run and qc results to keep a couple of gpu’s busy 24/7 (i work full time in a non ml/dl job, so have to stay focussed).
My motherboard only allows me to use a specific slot for primary video, which i am using a pcie riser in so i cant have a simple video only gpu  ️.
️.
I bought an nvme last weekend 240gb are at a good cost with sufficient capacity for now for me. I havent noticed any difference over an ssd yet but havent done any benchmarks.
84C in FurMark Burn-In mode. Fan speed never exceeded 52%.
How true ![]() But I think we’ll improve as we get more experienced.
But I think we’ll improve as we get more experienced.
It would be interesting to build an external enclosure. However, you can upgrade grabbing used parts on ebay!
If you benchmark it, let me know. For example, a pair of epochs over a big dataset with precompute=false would be a good baseline.
I ran a few tests on NVME vs SSD, and put results in part 2 of my medium post. For day to day notebook use, probably wont notice any difference, for heavy read-write definitely will notice. None of the tests I ran in notebook showed much difference, but on unzipping multiple zipped folders on the ssd vs nvme, nvme was 2-3x faster. Interestingly, at my local computer shop Samsung 250GB nvme dives are slightly cheaper than 250GB ssd.
You are lucky. Here, they cost twice the price of a regular ssd!
i have 4 gpus and i want to run the model on 3 of them,what do i do then
,currently im doing model = torch.nn.DataParallel(model)
but that only runs on 1 gpu
Any tips?
I agree with klay123. At the top of every notebook page, after we import the other libraries, just type:
torch.cuda.set_device(n)
where n is 0, 1, 2, etc, from your set of GPUs.
Earlier in the thread, Jeremy found that running more than one GPU on the same model is no faster than running one GPU, as of today.
I’m using Vast.ai, and tested a bunch of combinations of batch-size and number of GPUs.
As mentioned earlier in this thread, the only way you’ll see a speedup using dataparallel is if you increase your batch size.
I ran the same job using different batch sizes, on either 1x, 2x or 4x GTX-1080-Ti GPU’s.
Using dataparallel and finding the optimal batch-size, I found a ~30% speedup for 2x vs 1x, and a ~40% speedup for 4x vs 1x.
Vast.ai’s prices are really cheap ( $0.15/hr for 1x, $0.30/hr for 2x, and $0.60/hr for 4x).
Hope this info is helpful.
5 Likes
also @matdmiller:
In version 1.0.28, I tried comparing speed improvements doing your parallelization approach and altering batch sizes. The way I changed batch sizes was passing bs parameter during data creation for tabular model:
data = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(list(range(n_split, n)))
.label_from_df(cols=dep_var, label_cls=FloatList, log=False)
.add_test(test, label=0)
.databunch(bs=1024))
I have two GPUs. The approach I used was this:
layer_groups_total = len(learn.layer_groups[0])
for i in range(layer_groups_total):
learn.layer_groups[0][i] = nn.DataParallel(learn.layer_groups[0][i], device_ids=[0, 1])
Then I timed training the model with
%%timeit
learn.fit_one_cycle(1, 1e-2)
Yet, the improvements in speed were barely, if at all, seen:
Using multiple GPUs, Batch size vs. run time:
- bs = 64: 5.91 s ± 571 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.39 s ± 101 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.35 s ± 89.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.85 s ± 39.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 60.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Using single GPU, Batch size vs. run time:
- bs = 64: 6.09 s ± 743 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.35 s ± 43.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.44 s ± 83.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.94 s ± 70.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Update:
I also tried parallelizing the entire model (instead of layer by layer approach above) with
learn.model = nn.DataParallel(learn.model)
However, during training with learn.fit_one_cycle(1, 1e-2) I get RuntimeError: CUDA error: out of memory at the same batch size (2048) that I successfully use for single-GPU computations. When I reduce my batch size by half (down to 1024), fitting works, but at twice the lower speed as before at the same batch size of 1024:
-
At bs = 1024
- two GPUs:
2.98 s ± 193 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) - single GPU:
1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- two GPUs:
-
At bs = 2048
- two GPUs:
RuntimeError: CUDA error: out of memory - single GPU:
1.66 s ± 71.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- two GPUs:
It looks to me that using two GPUs, then, is not beneficial, at least in my case.
Update 2
Here are more comprehensive results with and without using learn.model = nn.DataParallel(learn.model):
Using multiple GPUs, batch size vs. run time:
- bs = 64: 14.2 s ± 205 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 8.08 s ± 61.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 5.17 s ± 101 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 3.77 s ± 50.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 3.03 s ± 61.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 2048: CUDA error: out of memory
- bs = 4096: CUDA error: out of memory
Using single GPUs, batch size vs. run time:
- bs = 64: 6.09 s ± 743 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 128: 3.35 s ± 43.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 256: 2.44 s ± 83.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 512: 1.94 s ± 70.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 1024: 1.68 s ± 70.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 2048: 1.73 s ± 14.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- bs = 4096: CUDA error: out of memory
5 Likes
@aleksod Wow! Thank you for doing this! So impressive…
1 Like
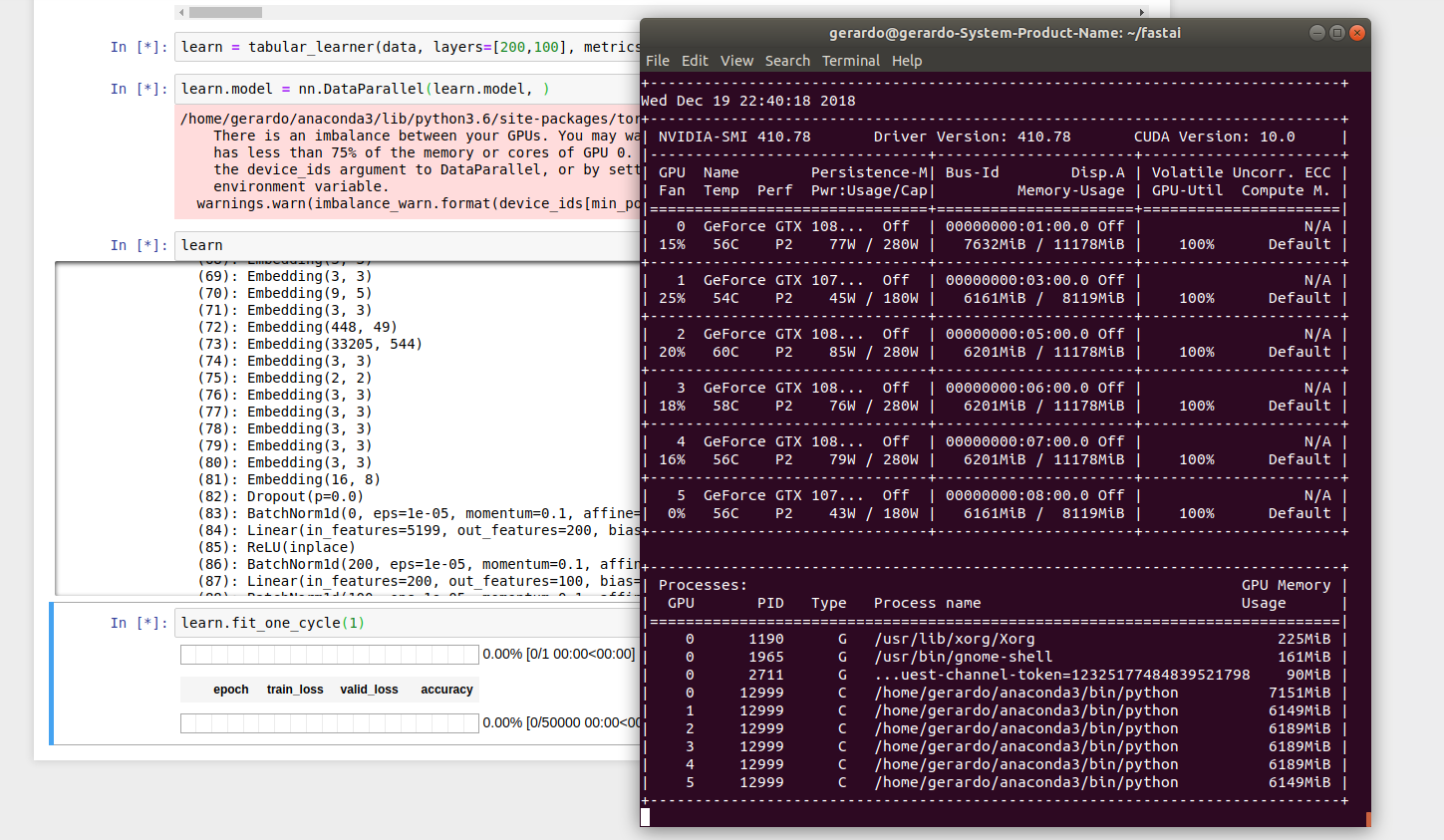
Did you time your training? What were the results of the parallelization? Faster or slower?
I think I spoke too soon.
The GPUs memory gets loaded and the GPUs goes to 100% but I never received a single calculation.
I left that running for 6 hours and not a single output.
I have 6 NVIDIA cards (4 1080tis and 2 1070tis)
I ran again only with the 1080tis and I will verify when I get home 
I thin pytorch has issues running more than 2 GPUs.
I will keep trying tonight.
1 Like
Can any one share TLDR please?
So currently multiple GPUs not good enough? I see good deals in vast.ai in TFlops compared to single GPUs.