The above worked for me to use 2 GPUs on my desktop for 2 separate processes(devices 0 and 1). -Thanks.
@hwasiti, when I am running
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
I get the following error
AttributeError: can’t set attribute
Can you please help?
Thanks in advance.
Can you share a snapshot of the code with the errors and few lines before this error? Where did you put this line exactly?
I have shared in my previous posts my github pet’s notebook. Can you try one of them and see whether it works for you?
Thanks again. Can you please send me the link to your notebook again?
screenshot of my code is attached.
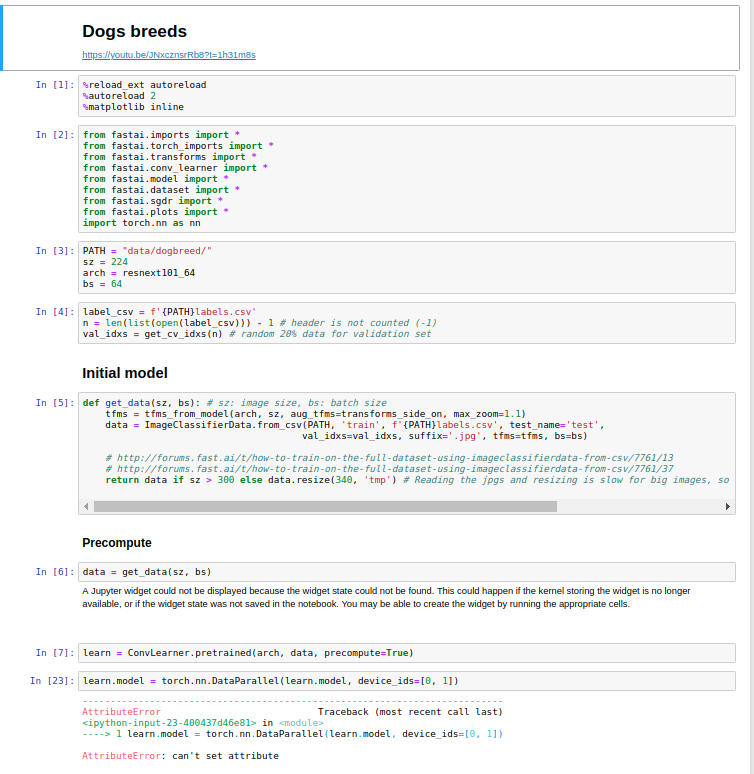
Look in cell number 32:
I have noticed that you have did this import:
import torch.nn as nn
Can you try this instead:
learn.model = nn.DataParallel(learn.model, device_ids=[0, 1])
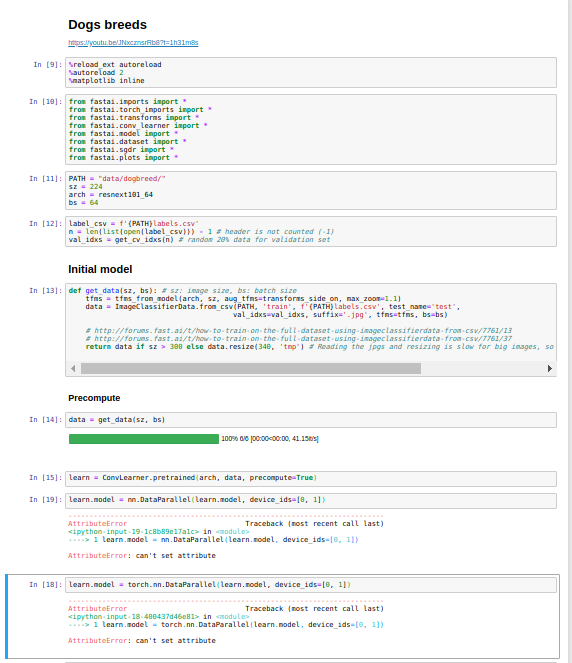
I am using fastai v1 and yours seems the older v0.7. I suspect that is the reason. Tried to check your code, but sorry to say I could not find anything wrong with your code. Maybe others with more knowledge can chime in for a solution.
Thanks, Haider. I updated fastai to v1.0.0 but still get the same error. Yes, will be waiting for other’s reply.
when I am running
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
or
learn.model = nn.DataParallel(learn.model, device_ids=[0, 1])
I get the following error
AttributeError: can’t set attribute
Imported packages:
from fastai.imports import *
from fastai.torch_imports import *
from fastai.transforms import *
from fastai.conv_learner import *
from fastai.model import *
from fastai.dataset import *
from fastai.sgdr import *
from fastai.plots import *
Can you please help?
Thanks in advance.
Can you share your code? I will try to run it on my machine and see.
‘ConvLearner’ is no longer used in fastai v1. What is your exact version of fastai?
Can you please also try my notebook, which I can confirm it works fine.
Run Cell 1 to 11.
Then jump to cell 30 and run from cell 30 to 34.
Please find my code from here
I am going to test yours.
I tried to run your code and it does not work on fastai v1.39
Please update your fastai to the latest version and try my code. Most likely then it will work
Your notebook seems from the older fastai and it is not compatible with fastai v1.39
conda install fastai -c fastai
1 Like
Hi Haider,
Thanks for your advice. Happy to let you know that after upgrading fastai to v1, coding is working fine.
1 Like
Running cifar example I seem to be stable at 68C (gpu: 1080) with driver 418.39. Note: computer near window in winter
Haider, I read the Horovod link you gave, and it does look very promising! The enhancements you would need to add to a framework like fastai are minimal and completely generic, that is, not specific to one model architecture. They have a basic implementation for PyTorch on that web page, and it is only about 40 lines of code. The changes are at the init(), the model distribution, the optimizer (you wrap your optimizer in theirs; that’s where the gradients are shared, I guess), and distributing the parameters initially once. Your specific hardware configuration (multi-node, or one-node, multi-GPU) is passed in the training command line as just one line of parameters. Seems too good to be true  . All of that gives you 90% linear scaling even with multi-node (I assume infiniband interconnects). Horovod could be built in to fastaiV2 and nobody would notice (I hope), in the best case scenario!. We could have state-of-art performance with commodity gamer hardware.
. All of that gives you 90% linear scaling even with multi-node (I assume infiniband interconnects). Horovod could be built in to fastaiV2 and nobody would notice (I hope), in the best case scenario!. We could have state-of-art performance with commodity gamer hardware.
1 Like
Hi @danaludwig
Recently, there was an exciting progress in multi-node distributed data parallel training in fastai…
If you search the forum you will find some examples…
Particularly, see this Cifar training example that Jeremy, Sylvain, Andrew and Brett managed to smash everybody in April 2018 in the DAWNBench Stanford competition …
More about it here…
This forum thread related…
I am very excited about this to be already integrated in fastai 
Fastai is peerless!
Hi @hwasiti,
After you have looked at Horovod, and you still think that our fast.ai group can get scalable multiple GPU training faster, then I will take your word for it! I have read Jeremy’s DAWNBench blog and I just wasn’t sure whether it was a one-time model-specific AWS solution or it was something we can all use. I hope he will get into it more in the current class!
My problem is NLP and building a big fat language model faster, and I didn’t know how well the DAWNBench experience would generalize to the other models I think your last URL
https://forums.fast.ai/t/distributeddataparallel-init-hanging/41218/3
ends on a very positive note where @kcturgutlu got his code to work and got linear scaling with # of GPU’s! My goal would be for a nice multiple GPU approach that handles 2-4 GPU’s on one node, and that doesn’t require a lot of detailed tweaking for each model.
I have read the blog post too… I think to win an international competition, one should use everything… Efficient distributed learning + the competition specific tweaks here and there… But I think that the distributed part of their solution is also so good that it contributed to their winning solution just as good as others or maybe better…
I haven’t tried distributed fastai yet, since my 2 pcs has 3+2 GPUs which is not encouraging for the efforts… If I had an opportunity to work on servers of 8 GPUs and more, I would think seriously on how to implement it… I think the 1st step for anybody interested, is to replicate the fastai example provided… Then if it worked tweak it into his own model pipeline… If worked, try to implement the Horovod method and compare… I would start with my research from the easiest path and go up…
Currently, I am using my multiple gpus with pytorch dataparallel, only to increase the possible model size and batch size. This is a little bit less efficient in training time, but it would give similar outcome… Or most of the time I just train (multiple models in parallel) one notebook on each gpu… Most of the time I need to tweak a lot of parameters and see which one is better, and this is speeding up my iterations… But I am still eager to try this distributed method on GCP nodes someday…
Has anyone tried using NVLink with 2 TITAN RTX cards? From the NVIDIA Technical Specs, the NVLink appears to allow the use of two cards as if they were one, suggesting no change in code, nor need for explicit parallelism.
TITAN RTX w/NVLINK
1 Connecting two TITAN RTX cards with NVLink to scale performance and memory capacity to 48 GB is only possible if your application supports NVLink technology. Please contact your application provider to confirm their support for NVLink. | 2 NVIDIA NVLink sold separately.
Not sure if NVLink is implemented in fastai and usable from Juptyer Notebook, i.e., not as a script. I found this blog suggesting that the 2nd card scales linearly, but using Caffe. NVLink Performance
If this has been answered elsewhere in the forums, I apologize in advance.
Have you found anything out about this? I have dual Titan RTXs with nvlink and I would love to be able to pool resources.
Sorry to interupt, but I need assistance about dual GPU.
I just buy a better GPU (GeForece GTX 1050Ti) 4 GB memory, before it I only have GeForce GT 730 2 GB memory.
The probelum is nvidia-smi not detect my 2nd GPU.
bram@Jarvis:~$ nvidia-smi
Sat May 2 16:24:26 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.59 Driver Version: 440.59 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... Off | 00000000:01:00.0 Off | N/A |
| 23% 42C P0 N/A / 80W | 110MiB / 4040MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2168 G /usr/lib/xorg/Xorg 85MiB |
| 0 2671 G cinnamon 22MiB |
+-----------------------------------------------------------------------------+
mean while in lspci | grep vga, the second GPU is detected.
bram@Jarvis:~$ lspci | grep VGA
00:02.0 VGA compatible controller: Intel Corporation Xeon E3-1200 v3/4th Gen Core Processor Integrated Graphics Controller (rev 06)
01:00.0 VGA compatible controller: NVIDIA Corporation GP107 [GeForce GTX 1050 Ti] (rev a1)
06:00.0 VGA compatible controller: NVIDIA Corporation GF108 [GeForce GT 730] (rev a1)
already try to googling, to make it detect by nvidia-smi, is using dual monitor. Is this ok? I mean if want to train with dual GPU, is this will give a problem or not. in my experience using Laptop, if nvidia-smi not detect the GPU, because we set Intel GPU to save the battery durtion, we can do anything to ‘control’ any module. all module said no GPU.
I see Mr. @prairieguy can manage 3 GPU to detect with nvidia-smi. How we can do that?
my environtment already set to:
export CUDA_VISIBLE_DEVICE="0,1"
cuda toolkit 10.1, cudnn 7.6.5, TensorRT 6
Linux Mint 19.3