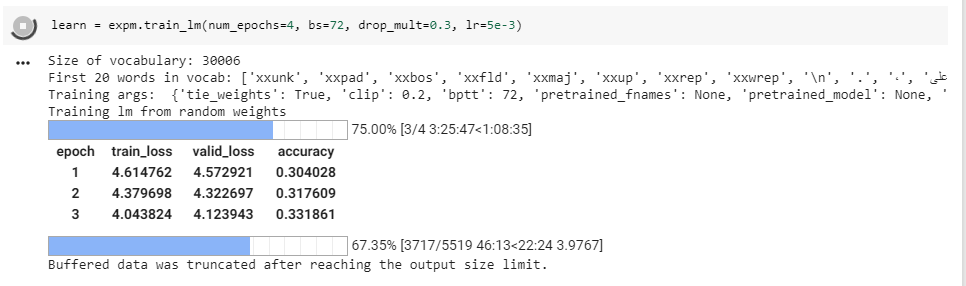
Here is a memory profiler that taps into each epoch, and can be fine-tuned to each separate stage.
import tracemalloc, threading, torch, time, pynvml
from fastai.utils.mem import *
from fastai.vision import *
if not torch.cuda.is_available(): raise Exception("pytorch is required")
def preload_pytorch():
torch.ones((1, 1)).cuda()
def gpu_mem_get_used_no_cache():
torch.cuda.empty_cache()
return gpu_mem_get().used
def gpu_mem_used_get_fast(gpu_handle):
info = pynvml.nvmlDeviceGetMemoryInfo(gpu_handle)
return int(info.used/2**20)
preload_pytorch()
pynvml.nvmlInit()
class PeakMemMetric(LearnerCallback):
_order=-20 # Needs to run before the recorder
def peak_monitor_start(self):
self.peak_monitoring = True
# start RAM tracing
tracemalloc.start()
# this thread samples RAM usage as long as the current epoch of the fit loop is running
peak_monitor_thread = threading.Thread(target=self.peak_monitor_func)
peak_monitor_thread.daemon = True
peak_monitor_thread.start()
def peak_monitor_stop(self):
tracemalloc.stop()
self.peak_monitoring = False
def peak_monitor_func(self):
self.gpu_mem_used_peak = -1
gpu_id = torch.cuda.current_device()
gpu_handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_id)
while True:
gpu_mem_used = gpu_mem_used_get_fast(gpu_handle)
self.gpu_mem_used_peak = max(gpu_mem_used, self.gpu_mem_used_peak)
if not self.peak_monitoring: break
time.sleep(0.001) # 1msec
def on_train_begin(self, **kwargs):
self.learn.recorder.add_metric_names(['cpu used', 'peak', 'gpu used', 'peak'])
def on_epoch_begin(self, **kwargs):
self.peak_monitor_start()
self.gpu_before = gpu_mem_get_used_no_cache()
def on_epoch_end(self, **kwargs):
cpu_current, cpu_peak = list(map(lambda x: int(x/2**20), tracemalloc.get_traced_memory()))
gpu_current = gpu_mem_get_used_no_cache() - self.gpu_before
gpu_peak = self.gpu_mem_used_peak - self.gpu_before
self.peak_monitor_stop()
# The numbers are deltas in MBs (beginning of the epoch and the end)
self.learn.recorder.add_metrics([cpu_current, cpu_peak, gpu_current, gpu_peak])
# against MNIST dataset
# assuming you already have data and model objects
learn = create_cnn(data, model, metrics=[accuracy], callback_fns=PeakMemMetric)
learn.fit_one_cycle(3, max_lr=1e-2)
gives:
Total time: 00:59
epoch train_loss valid_loss accuracy cpu used peak gpu used peak
1 0.325806 0.070334 0.978800 0 2 80 6220
2 0.093147 0.038905 0.987700 0 2 2 914
3 0.047818 0.027617 0.990600 0 2 0 912
The numbers are deltas in MBs (beginning of the epoch and the end)
Note the huge surge of GPU RAM required on the first epoch
The measurements may require more thinking, but it’s a good start.
@AbuFadl, perhaps this will be helpful for your OOM debugging.
Thanks to @sgugger for helping me figure out the custom metrics.