I am looking for ways of speeding up training a language model on my computer and I came across a web site publishing results for benchmark tests for different GPUs. It shows that 1080ti card is as fast at training WordRNN as a Titan Pascal X and twice as fast as RTX 2070 that I currently use. Can anybody confirm that 1080ti is really this good for RNN as this chart says?
Hi @stas
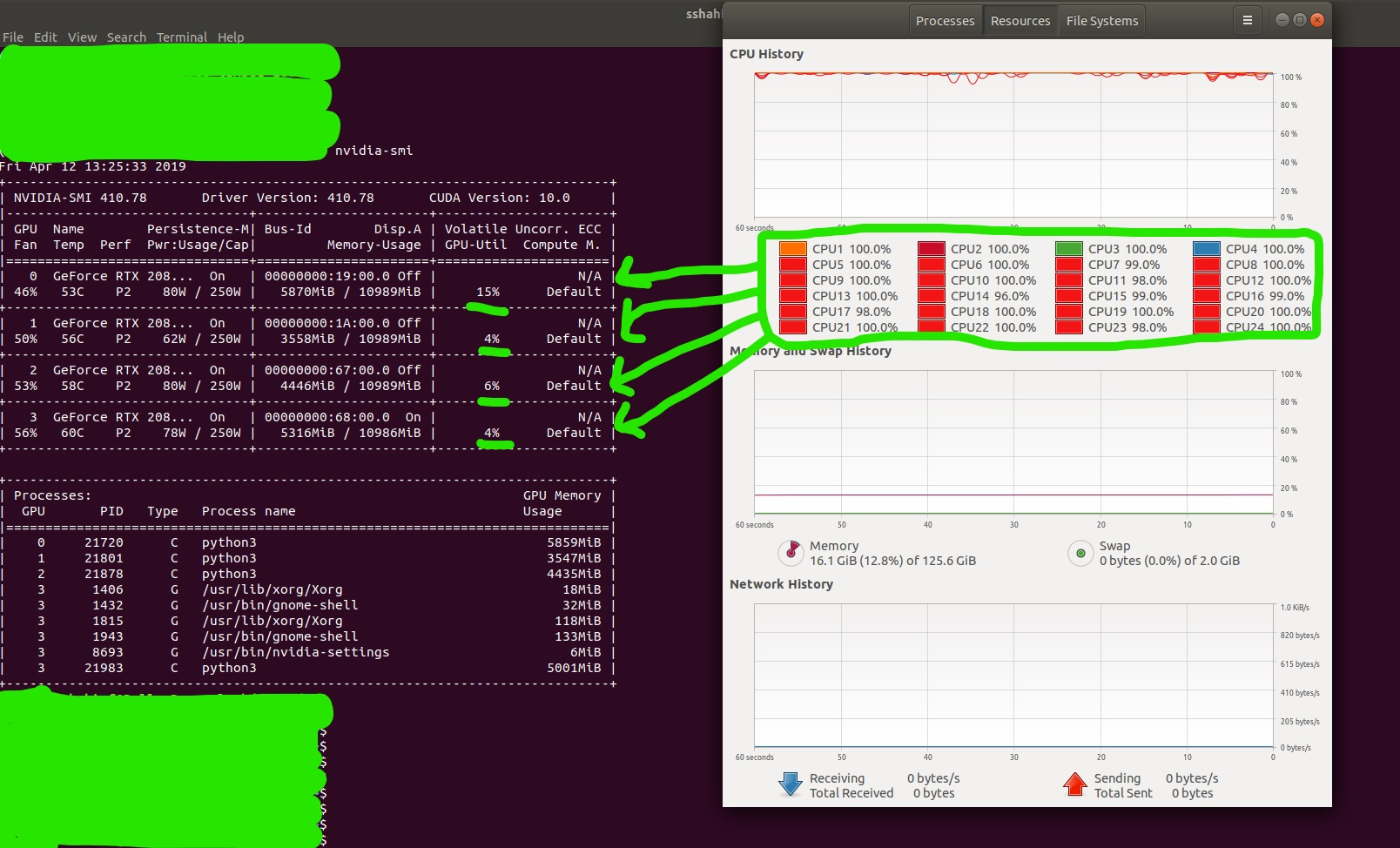
I am having the opposite issue, meaning My GPU s are not utilized fully and instead training is taking quite a lots of CPUs.
We have recently purchased a Lambda-Quad and now when I run 4 different DL training one on each GPU, GPU usage goes frequently from 0 to about 15% back and force while all 24 CPUs on the system is being used at 100% constantly, and training in general is very slow (see the image below), indicating lack of enough CPUs is a bottle neck on this. do you think it is normal?
Ideally we expect to utilize more of our GPUs and not so many CPUs.
=== Software ===
python : 3.7.1
fastai : 1.0.51
fastprogress : 0.1.21
torch : 1.0.0
nvidia driver : 410.78
torch cuda : 10.0.130 / is available
torch cudnn : 7401 / is enabled
=== Hardware ===
nvidia gpus : 4
torch devices : 4
- gpu0 : 10989MB | GeForce RTX 2080 Ti
- gpu1 : 10989MB | GeForce RTX 2080 Ti
- gpu2 : 10989MB | GeForce RTX 2080 Ti
- gpu3 : 10986MB | GeForce RTX 2080 Ti
=== Environment ===
platform : Linux-4.15.0-47-generic-x86_64-with-debian-buster-sid
distro : #50-Ubuntu SMP Wed Mar 13 10:44:52 UTC 2019
conda env : base
python : /home/.../anaconda3/bin/python
sys.path : /home/.../anaconda3/bin
/home/.../anaconda3/lib/python37.zip
/home/.../anaconda3/lib/python3.7
/home/.../anaconda3/lib/python3.7/lib-dynload
/home/.../anaconda3/lib/python3.7/site-packages
/home/.../anaconda3/lib/python3.7/site-packages/IPython/extensions
/home/.../.ipython
Tue Apr 16 12:51:46 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.78 Driver Version: 410.78 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... On | 00000000:19:00.0 Off | N/A |
| 54% 57C P2 99W / 250W | 6052MiB / 10989MiB | 16% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... On | 00000000:1A:00.0 Off | N/A |
| 29% 43C P8 4W / 250W | 11MiB / 10989MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce RTX 208... On | 00000000:67:00.0 Off | N/A |
| 53% 58C P2 79W / 250W | 3554MiB / 10989MiB | 9% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce RTX 208... On | 00000000:68:00.0 On | N/A |
| 33% 46C P8 26W / 250W | 318MiB / 10986MiB | 7% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 10046 C python 6041MiB |
| 2 9931 C python 3543MiB |
| 3 1409 G /usr/lib/xorg/Xorg 18MiB |
| 3 1437 G /usr/bin/gnome-shell 51MiB |
| 3 4183 G /usr/lib/xorg/Xorg 118MiB |
| 3 4313 G /usr/bin/gnome-shell 117MiB |
| 3 7498 G /usr/bin/nvidia-settings 6MiB |
+-----------------------------------------------------------------------------+
However, when I run the same code and data on a Windows Machine (specified below), the GPU memory is being taken constantly at about 60% more or less and the training is faster.
=== Software ===
python : 3.7.1
fastai : 1.0.51.dev0
fastprogress : 0.1.20
torch : 1.0.1
torch cuda : 10.0 / is available
torch cudnn : 7401 / is enabled
=== Hardware ===
torch devices : 1
- gpu0 : GeForce GTX 1080 with Max-Q Design
=== Environment ===
platform : Windows-10-10.0.16299-SP0
conda env : base
python : C:\ProgramData\Anaconda3\python.exe
sys.path : C:\Users\sshahinf\Desktop\Python_code
C:\ProgramData\Anaconda3\python37.zip
C:\ProgramData\Anaconda3\DLLs
C:\ProgramData\Anaconda3\lib
C:\ProgramData\Anaconda3
C:\ProgramData\Anaconda3\lib\site-packages
C:\ProgramData\Anaconda3\lib\site-packages\win32
C:\ProgramData\Anaconda3\lib\site-packages\win32\lib
C:\ProgramData\Anaconda3\lib\site-packages\Pythonwin
C:\ProgramData\Anaconda3\lib\site-packages\IPython\extensions
C:\Users\...\.ipython
no nvidia-smi is found
It’s hard to tell from just the environment, the only main difference I see is that you have an older pytorch on the linux machine, so it might be worth it to upgrade so you’re comparing closer environments.
Otherwise, it looks like those CPUs aren’t able to feed the GPU fast enough and perhaps you hit a CPU cache problem, where new data gets loaded all the time and the cache gets invalidated before the processed data gets consumed, and so you context switch all the time but not unloading the data fast enough? One experiment would be to go back to one GPU there first and see that you get a comparable results speed-wise with your windows machine. And then enable another GPU, and so forth. Not knowing what kind of loading / transforms you do - perhaps that PC besides a powerful array of GPUs needs a much more powerful CPU? Using 1-2 gpus will probably answer that question for you.
Task: train 5-folds CV model in one process with LRScheduler which saves model when accuracy improved and loads saved model if accuracy has not improved for some number of iterations.
Problem: OOM when loading next model.
Solution:
It was not enough just to move a model itself from gpu to cpu. Even deleting the model does not help. Cleaning inside fit/predict is required:
x to cpu
y to cpu
outputs to cpu
loss to cpu
del x, y, outputs, loss
gc.collect()
torch.cuda.empty_cache()
Now we can train multiple models within one process without the need to terminate it to clean GPU memory.
UPDT: unfortunately this cleaned only some part of GPU, leakage remains.
I can just guess, but It looked like being left in fit/predict these tensors prevent model to be completely removed from memory. As even moving model to cpu does not help and del model + gc.collect() + torch.cuda.empty_cache() does not always help either (same actions resulted in different outcomes).
And if that doesn’t help please share a minimal reproducible test case, with just one training where learn.destroy doesn’t release the circular references. Then it’d be possible to debug this.
In any case, don’t wait for the “next” thing to fail on OOM, instead, ensure that the first thing cleanly returns all the memory - i.e. use either nvidia-smi, or much better https://github.com/stas00/ipyexperiments/ to do the measuring for you.

{kind=link}