[this has been moved from the dev chat to support a focused discussion]
TL:DR How can we do a lot of experimentation in a given jupyter notebook w/o needing to restart the kernel all the time? Solution: https://github.com/stas00/ipyexperiments
Post 1: I have been contemplating how we have a very inefficient way of dealing with ‘cuda: out of memory’ problems and also when we do experiments in the notebook and the GPU memory “leaks” with each experiment.
I’d like to explore two closely related scenarios:
-
dealing with ‘cuda: out of memory’ by being able to roll back to a processor state where we can change the parameters to consume less memory. We already save intermediate states of data, but often it’s cumbersome since it’s not enough to restart the kernel and load the data again, one needs to go and re-run some parts of the notebook, which is very inefficient and error-prone.
-
having an experiment framework, so that at the end of each experiment the GPU RAM is released.
So the theoretical idea is to have a block like ‘try/except’, but wrt objects, so that at the end of that block all objects that were created since the beginning of this block get freed and the consumed by this block GPU RAM gets automatically released to be used again.
So when I’d like to find out some parameters for better training outcome or for finding the limit of the card, I’d run:
data = ...
memory_block:
learn = ...
learn.lr_find()
learn.fit...
and I could go back and repeat it w/o needing to restart the kernel.
I guess implementation-wise it’d be some kind of fixture that will start recording all new objects created and then destroy them at the end of the block?
Perhaps just using a simple function will do the trick as the local variables should get destroyed upon its exit, so there is no need to re-invent the wheel - I am yet to try it - I’m not sure under which circumstances pytorch releases its GPU memory. Except it’d be going against the-action-per-cell convention we use, as the whole experiment will need to be moved into a single cell.
Your thoughts are welcome.
Post 2:
It somewhat works. i.e. some memory gets released, but not all.
Is it possible that fastai leaks some objects?
Currently I’m trying to figure out the parameters for lesson3-imdb.ipynb so that my 8GB card can do the lesson, since as is it’s running out of GPU RAM.
def block():
learn = language_model_learner(data_lm, bptt=70, drop_mult=0.3, pretrained_model=URLs.WT103)
learn.lr_find()
block()
torch.cuda.empty_cache()
Since cache has been emptied, in theory the GPU RAM should go back to be the same after running this block.
Before running this code I get: 485MiB used, after - 2097MiB. If I rerun this cell it goes up to 2669MiB, and 3rd 3219MiB, then 3765MiB and so forth.
Any insights on what might be going on? Some circular references that prevent the memory release?
If I add gc.collect() before emptying torch cache:
block()
gc.collect()
torch.cuda.empty_cache()
then I can re-run the block w/o incremental RAM leakage.
Reading more on gc, gc.garbage contains a list of objects which the collector found to be unreachable but could not be freed (uncollectable objects). objects with a __del__() method don’t end up in gc.garbage . So if I add print(gc.garbage):
block()
gc.collect()
torch.cuda.empty_cache()
print(gc.garbage)
I get:
AttributeError Traceback (most recent call last)
<ipython-input-25-f06f01607ed3> in <module>()
8 gc.collect()
9 torch.cuda.empty_cache()
---> 10 print(gc.garbage)
~/anaconda3/envs/pytorch-dev/lib/python3.6/site-packages/dataclasses.py in __repr__(self)
AttributeError: 'LanguageLearner' object has no attribute 'data'
So does this mean gc couldn’t free the LanguageLearner object? If I print object reference, indeed you can see that there is a reference cycle there:
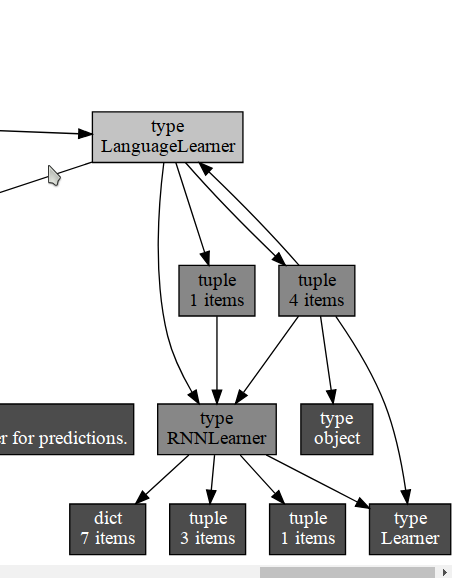
To get this graph I did:
! pip install objgraph xdot
import objgraph
learn = language_model_learner(data_lm, bptt=70, drop_mult=0.3, pretrained_model=URLs.WT103)
objgraph.show_refs([learn])
Plus, there are 920 objects that couldn’t be freed:
print(len(gc.garbage))
920
edit: I did a few experiments with pure pytorch:
import torch
def consume(n): torch.ones((n, n)).cuda()
n = 1
consume(n)
torch.cuda.empty_cache()
# always keeps 481MiB GPU RAM consumed
n = 5*2**13 # about 7GB
consume(n)
torch.cuda.empty_cache()
# back to 481MiB GPU RAM consumed
So it looks like it’s normal for pytorch to occupy and keep tied 0.5GB of GPU RAM to do even a tiniest thing of creating 1x tensor and loading it onto GPU.
However, it releases all the extra memory used by the process when I tried to load 7GB onto it.
But with fastai it doesn’t do that - the memory is not freed - which most likely means there is a leakage of objects that don’t get automatically freed. But if you look at the code that calls gc.collect() earlier most things do get reclaimed - so it seems that we get a conflict of python’s gc not knowing to run gc in time when the function returns and its variables needing to be released, and thus we get stuck with consumed GPU RAM, even though it can be freed up. But my suspicion is that while gc can magically release objects with circular references, fastai should do that on its own.