谢谢分享,我目前也是运行视频上的notebook就在kaggle上,训练自己的模型就在gcp.目前b站上也有中英文字母的视频,如果翻墙不方便也可以在b站上看.
1 Like
Lesson 7 U-net story

做Image Segmentation的基本流程逻辑
Image Segmentation的难点在哪?
Image Segmentation的难点在哪?
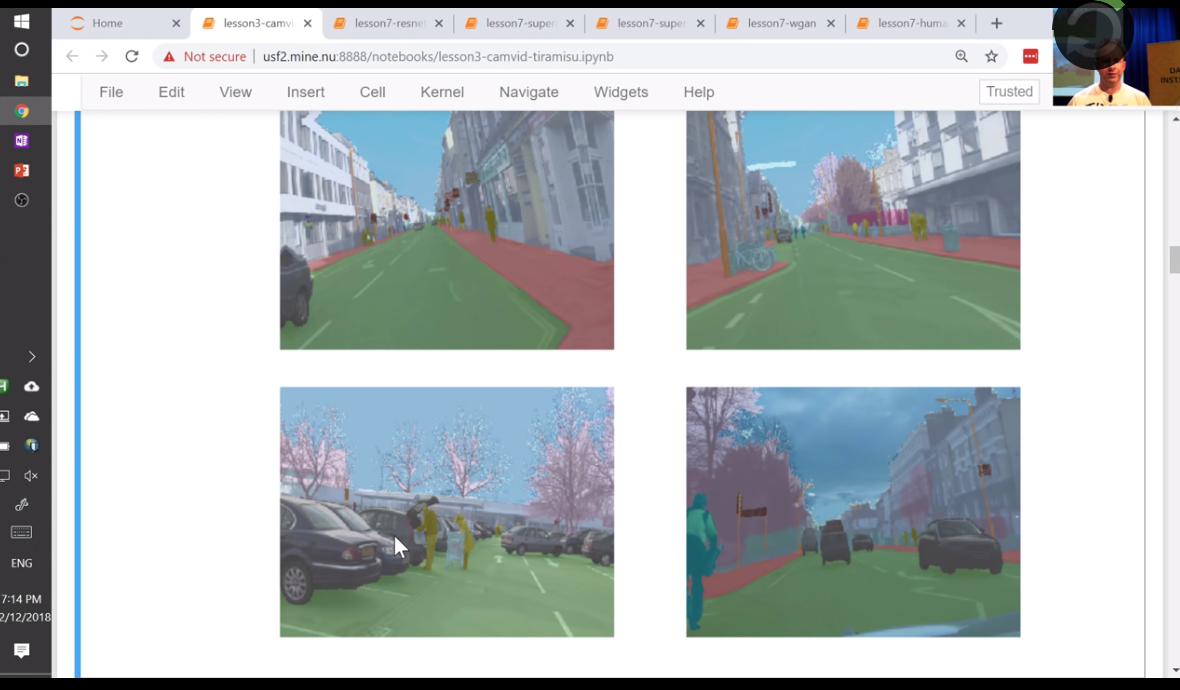
- 每个像素需要知道自己的物品归属,想象一下就知道难度很大
- 模型要判断一个像素是属于行人,而非自行车者,需要模型真的能理解区分两者
- 怎样的模型能做到这一步呢?
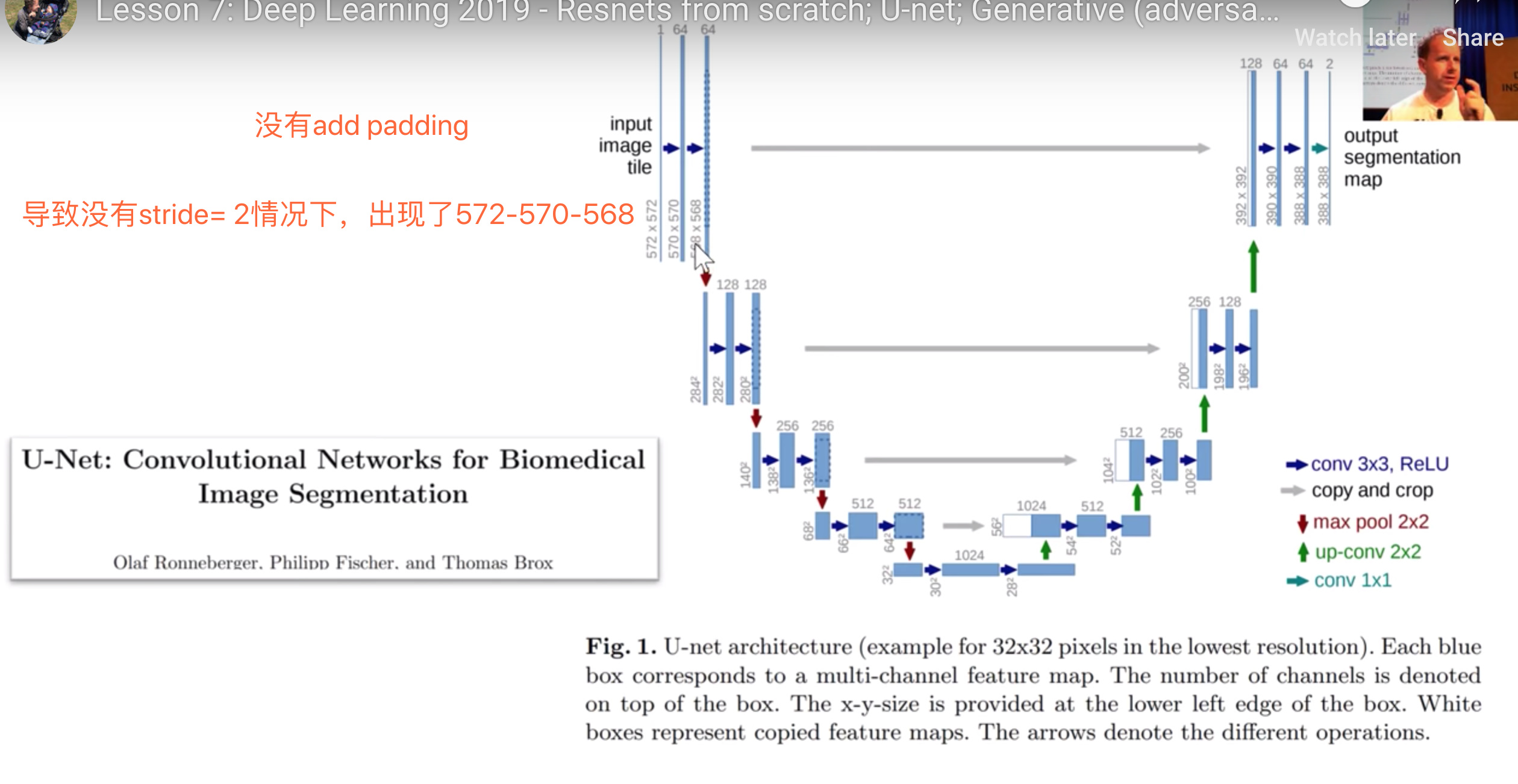
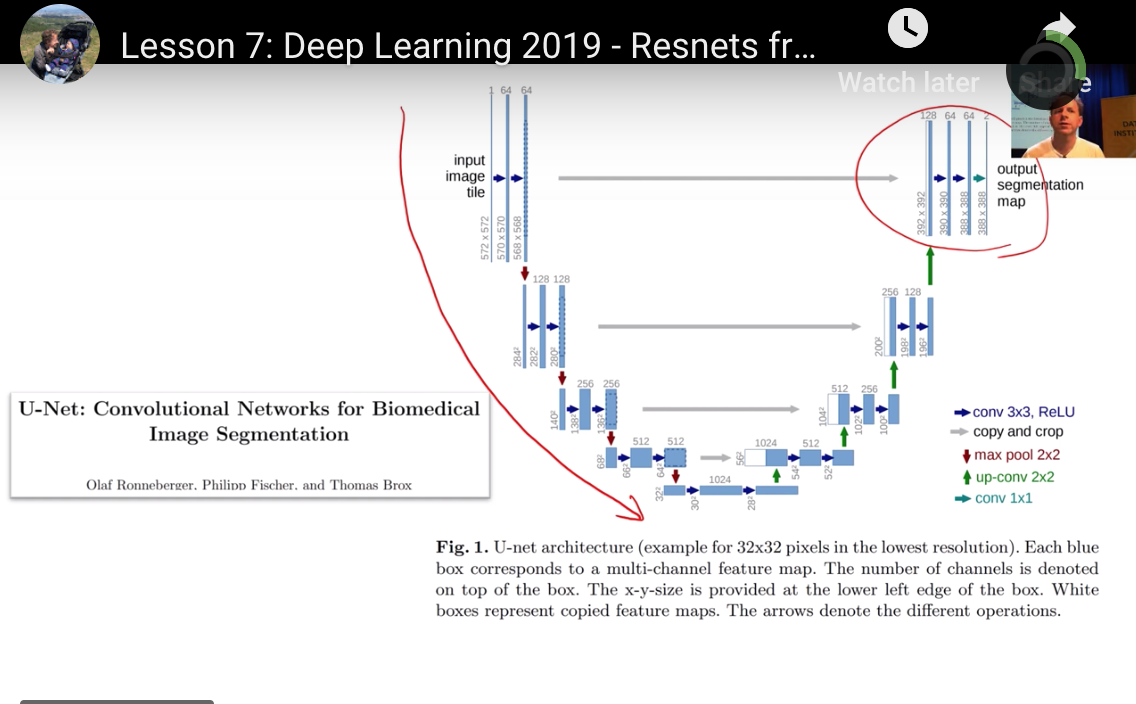
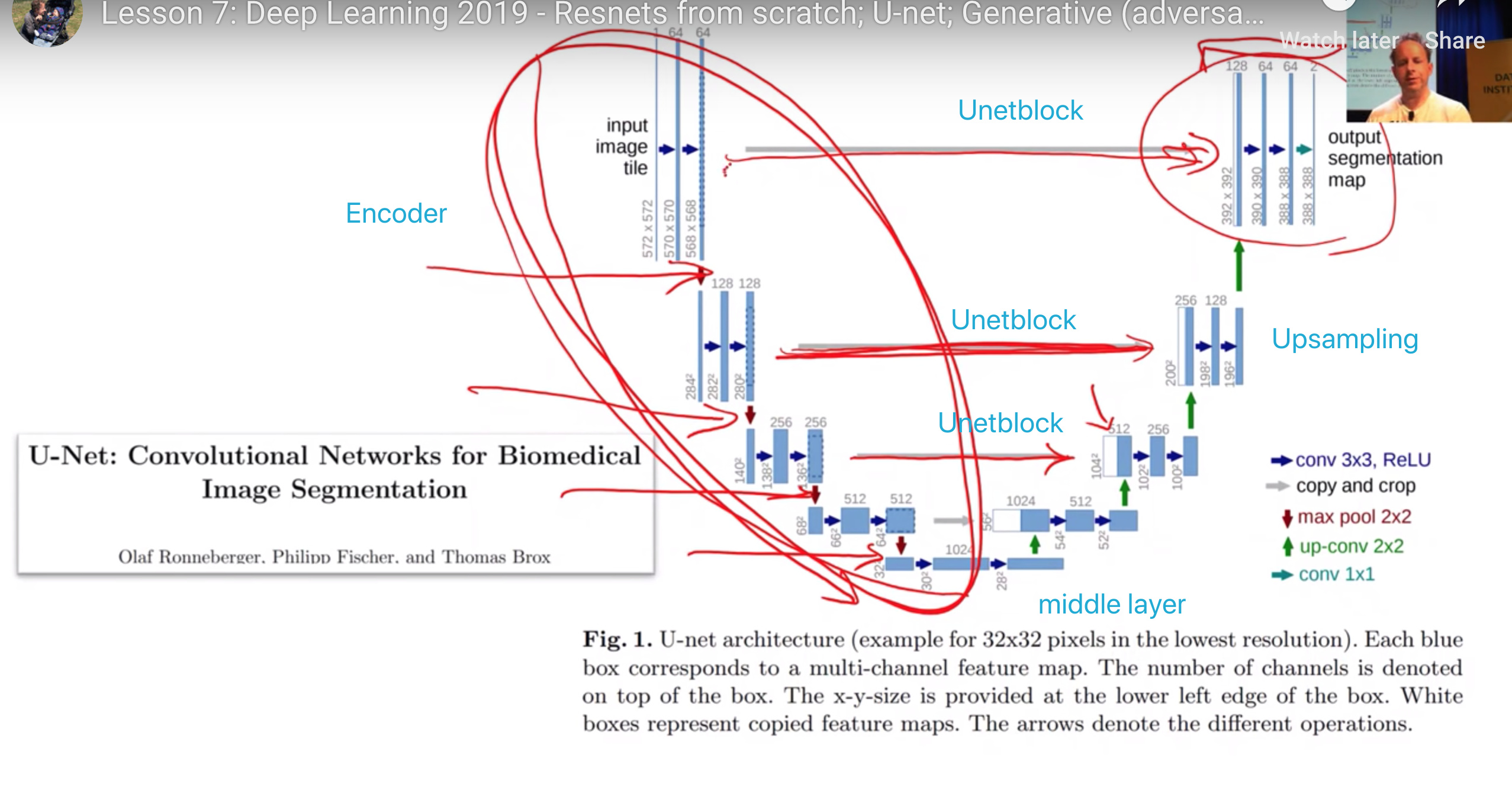
如何理解U-net的构成?
左侧第一个block情况
左侧第一个block情况
- 输入值是原图尺寸 572x572
- 同一个block的conv-layers生成的feature map不会缩小尺寸,但是没有add padding, 所以
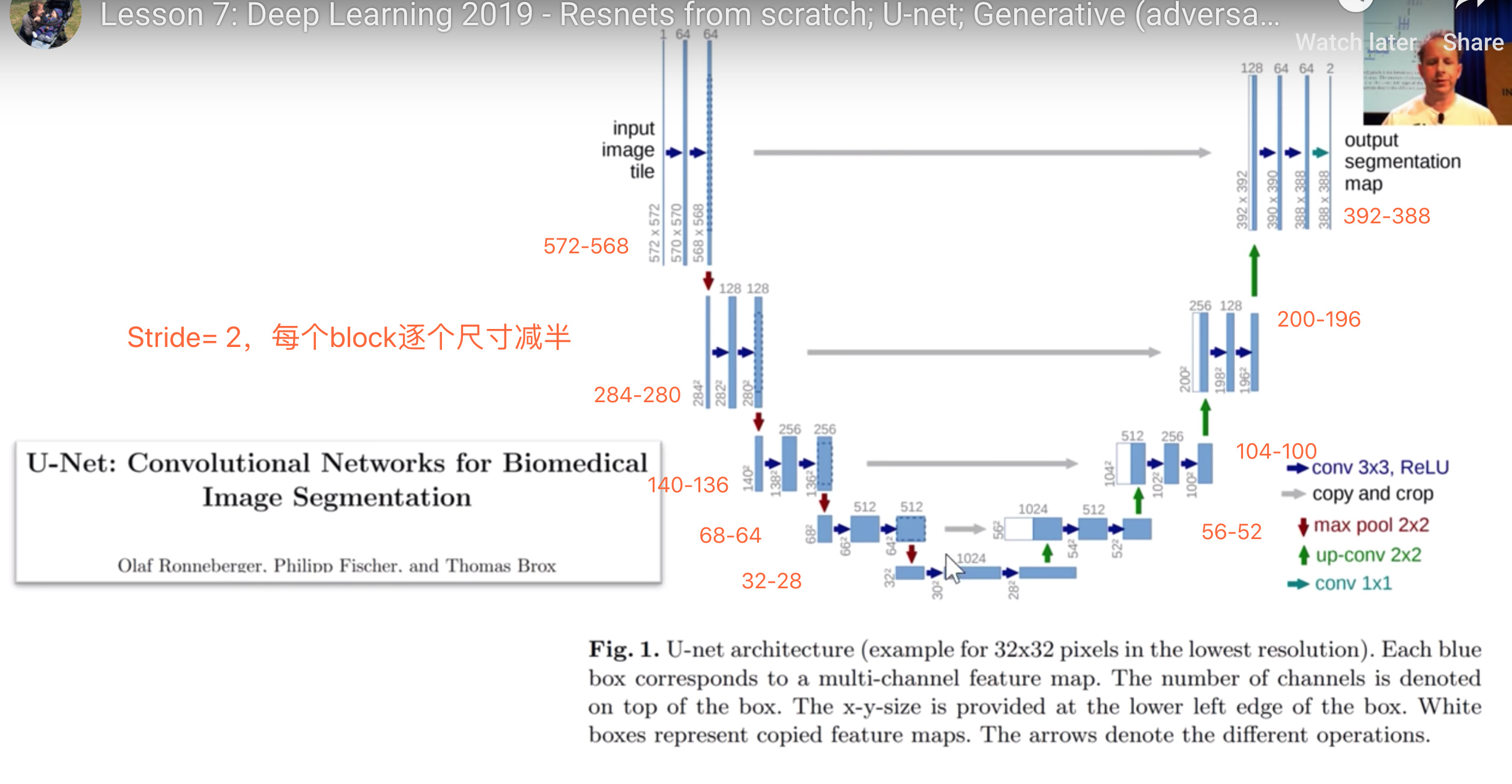
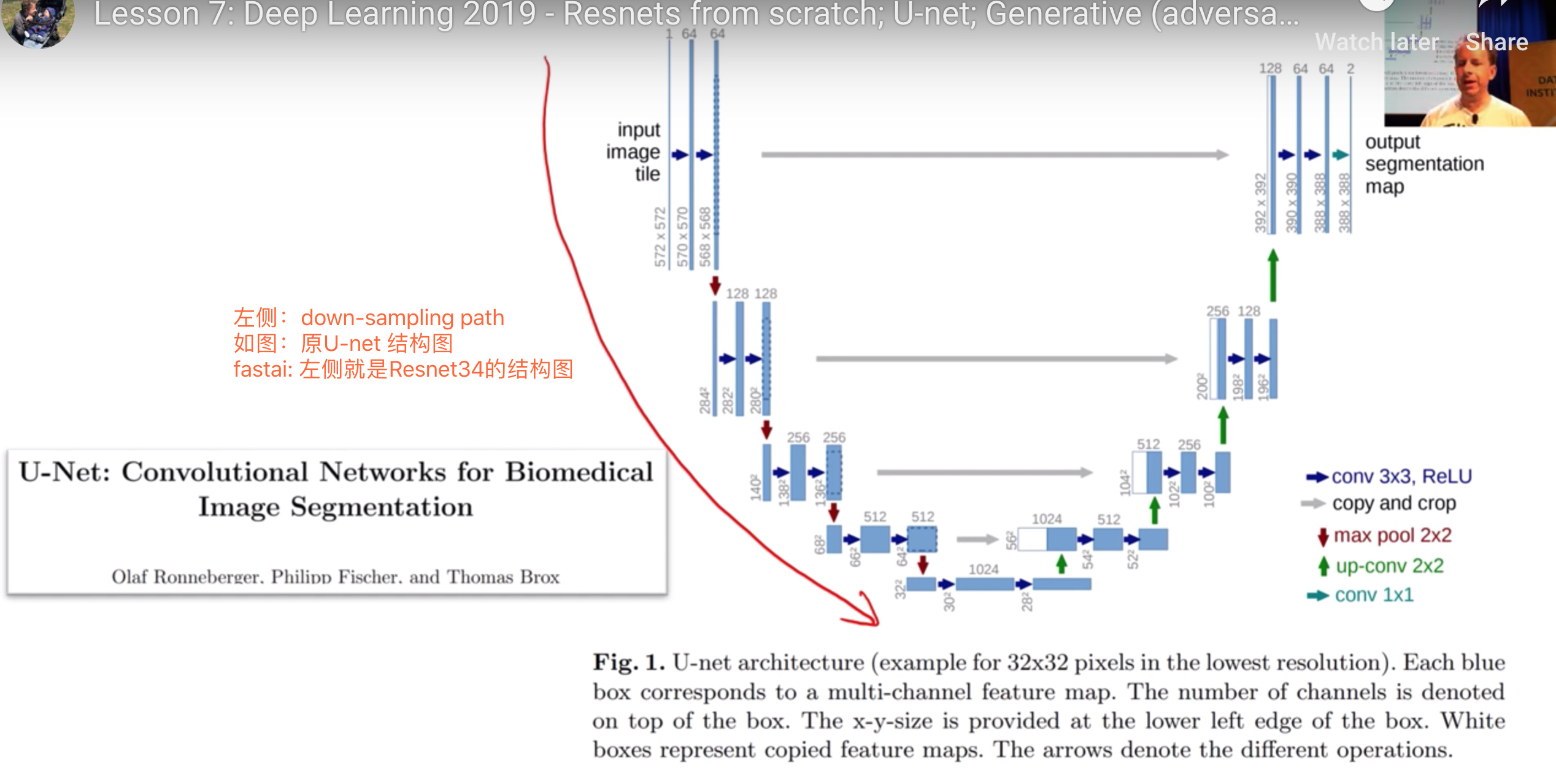
右侧blocks逐个翻倍尺寸,如何做到的呢
右侧blocks逐个翻倍尺寸,如何做到的呢?
- stride = 1/2,而不是 = 2
- 这个过程叫deconvolution or transpose-convolution

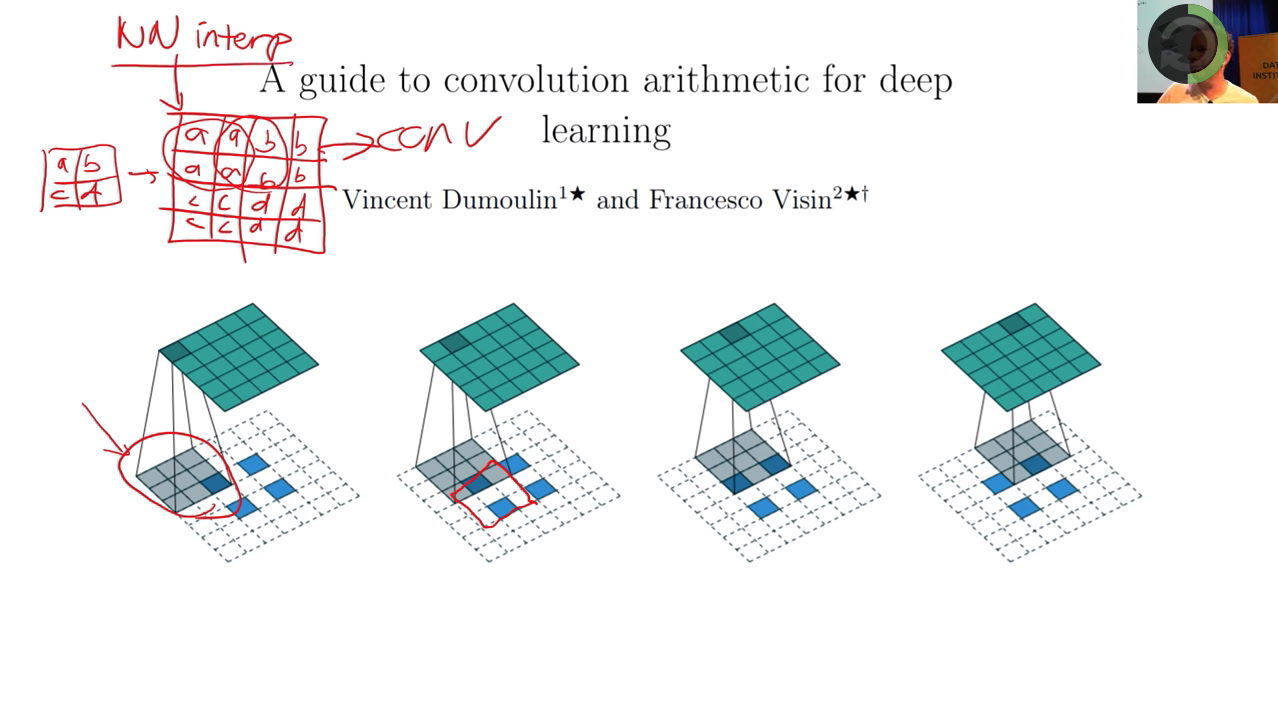

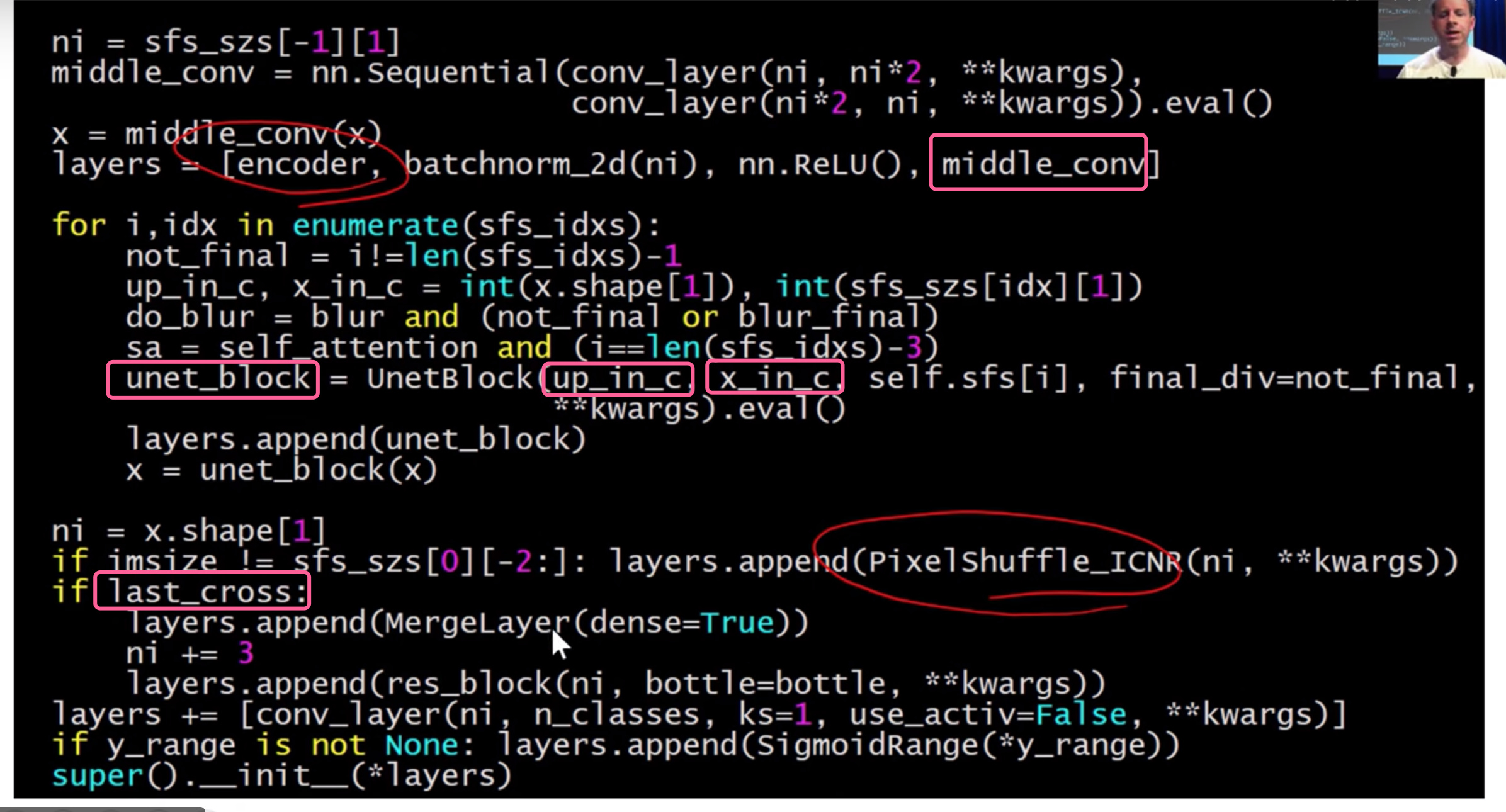
fastai 的deconvolution方法
fastai 的deconvolution方法
- part2 会教给大家的内容:
- pixel shuffle or subpixel convolution
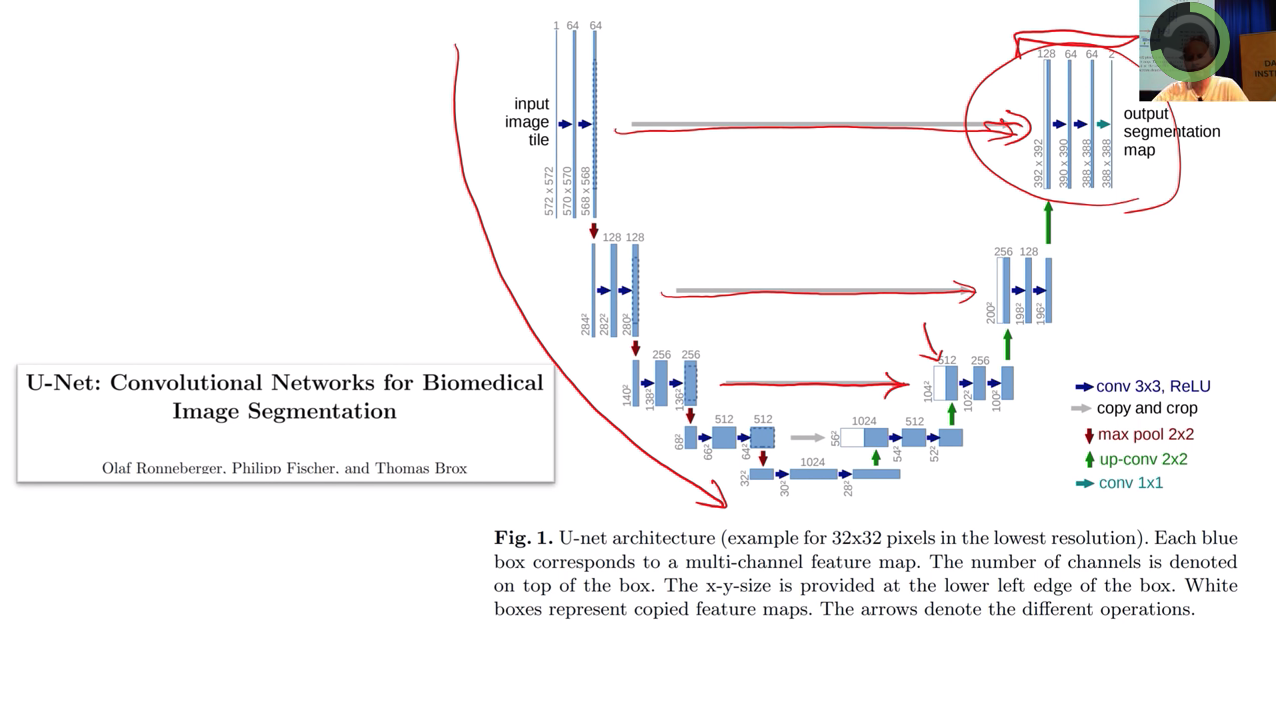
downsampling-convolutions + deconvolution + ? = U-net
downsampling-convolutions + deconvolution + ? = U-net
- 增加skip connection
- skip between the same level
- not add, but concat
- 一直做到将第一层的input image 和最后一层output feature maps的联系到一起的skip connection, 带给模型做segmentation的优势
Unet是如何被发现的
- 首先发表在了医学数据科学期刊里,不为深度学习社区所知
- Kaggle竞赛有人使用,开始被Jeremy关注到
- 后有人多次使用,进一步被先知先觉的人关注和研究
Pretrained GAN
image to image generation task 有哪些用途
image to image generation task 有哪些用途
- 低像素转高像素
- 黑白转彩色
- 缺失转完整
- 简单线条转名师作画
所需library
所需library
import fastai
from fastai.vision import *
from fastai.callbacks import *
from fastai.vision.gan import *
下载数据,准备文件夹路径
下载数据,准备文件夹路径
path = untar_data(URLs.PETS)
path_hr = path/'images'
path_lr = path/'crappy'
Crappified data
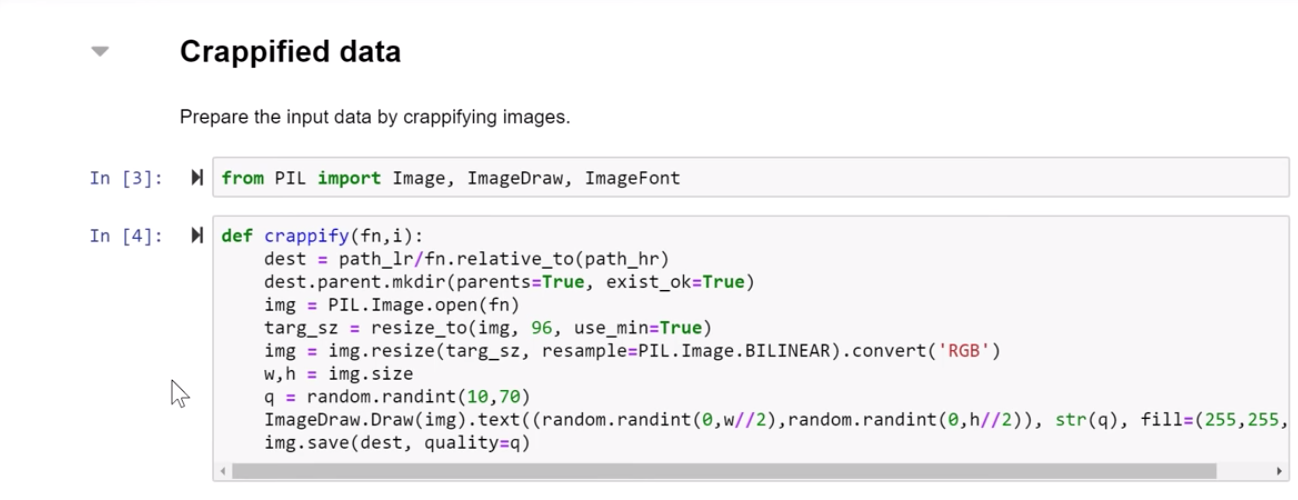
引入crappify函数
引入crappify函数
- 打开图片
- 缩小图片像素至 96x96 (低像素图片)
- 通过bilinear方式缩小图片,保留RGB
- 加入文字jpeg到图片中,文字清晰度随机在10-70间取值(很差,很清晰)
- 文字jpeg位置也是随机
这里是展示创造力的地方
- 从黑白到彩色
- 老照片换新照片
Prepare the input data by crappifying images.
from crappify import *
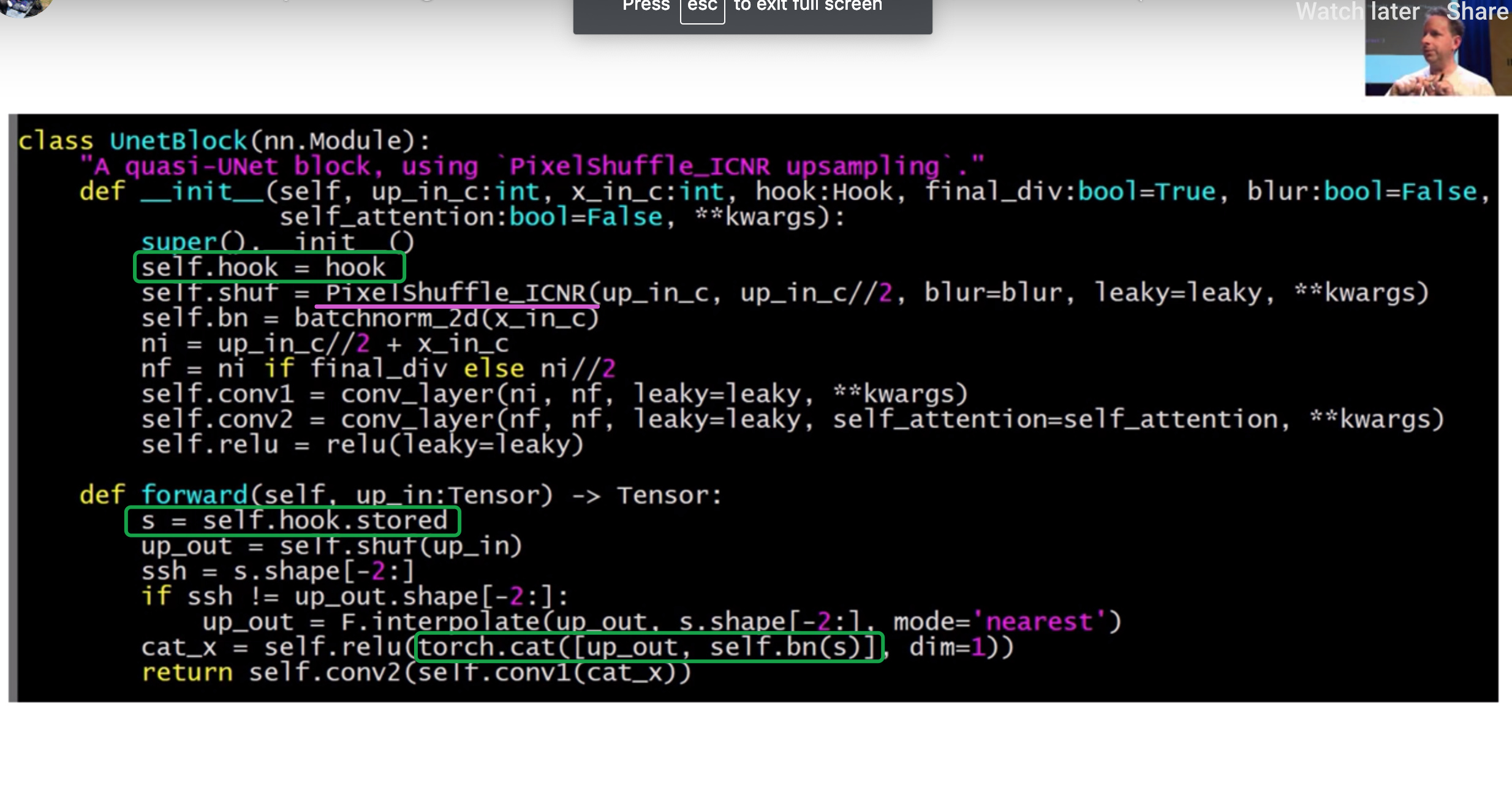
穿插问题: 为什么concat在2个conv-layer之前进行
穿插问题: 为什么concat在2个conv-layer之前进行
- 为了更多的interaction between downsampling and upsampling
穿插问题: downsampling 和 upsampling是如何能做到concat大小不变?
穿插问题: downsampling 和 upsampling是如何能做到concat大小不变?
- concat只限制在同一个block之中,进入下一个block时,新的concat将重头开始
如何加速crappify图片
如何加速crappify图片
Uncomment the first time you run this notebook.
#il = ImageList.from_folder(path_hr)
#parallel(crappifier(path_lr, path_hr), il.items)
For gradual resizing we can change the commented line here.
bs,size=32, 128
# bs,size = 24,160
#bs,size = 8,256
arch = models.resnet34
Pre-train generator
创建DataBunch
Now let’s pretrain the generator.
创建DataBunch
- 先在src中用crappy文件夹中图片,在分割成训练和验证集
- 在data中用原图来做标注图
- 再变形和转化为DataBunch
arch = models.resnet34
src = ImageImageList.from_folder(path_lr).random_split_by_pct(0.1, seed=42)
def get_data(bs,size):
data = (src.label_from_func(lambda x: path_hr/x.name)
.transform(get_transforms(max_zoom=2.), size=size, tfm_y=True)
.databunch(bs=bs).normalize(imagenet_stats, do_y=True))
data.c = 3
return data
data_gen = get_data(bs,size)
展示图片(crappy和原图)
展示图片(crappy和原图)
data_gen.show_batch(4)

wd = 1e-3
y_range = (-3.,3.)
loss_gen = MSELossFlat()
为什么要用pretrained models
为什么要用pretrained models
- 输入值:低像素,有杂质图片
- label:高像素,无杂质
- 目标:学会去除杂志,提升清晰度
- 所以需要模型本身就知道图片中的所有物品包括杂志
arch = models.resnet34
part 2将讲解的内容
part 2将讲解的内容
norm_type, self_attention, y_range?
def create_gen_learner():
return unet_learner(data_gen, arch, wd=wd, blur=True, norm_type=NormType.Weight,
self_attention=True, y_range=y_range, loss_func=loss_gen)
如何创建模型和训练
如何创建模型和训练
learn_gen = create_gen_learner()
learn_gen.fit_one_cycle(2, pct_start=0.8)
Total time: 01:35
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 0.061653 | 0.053493 |
| 2 | 0.051248 | 0.047272 |
如何做全模型训练
如何做全模型训练
learn_gen.unfreeze()
learn_gen.fit_one_cycle(3, slice(1e-6,1e-3))
Total time: 02:24
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 0.050429 | 0.046088 |
| 2 | 0.049056 | 0.043954 |
| 3 | 0.045437 | 0.043146 |
为什么提升像素不成功?
为什么提升像素不成功?
- MSE loss: 无法体现低像素图(消除了水印)与原图的差异
- 高清和纹路的差异,无法在MSE的差异中体现
- 我们需要更新的损失函数
- GAN是一种解决方案
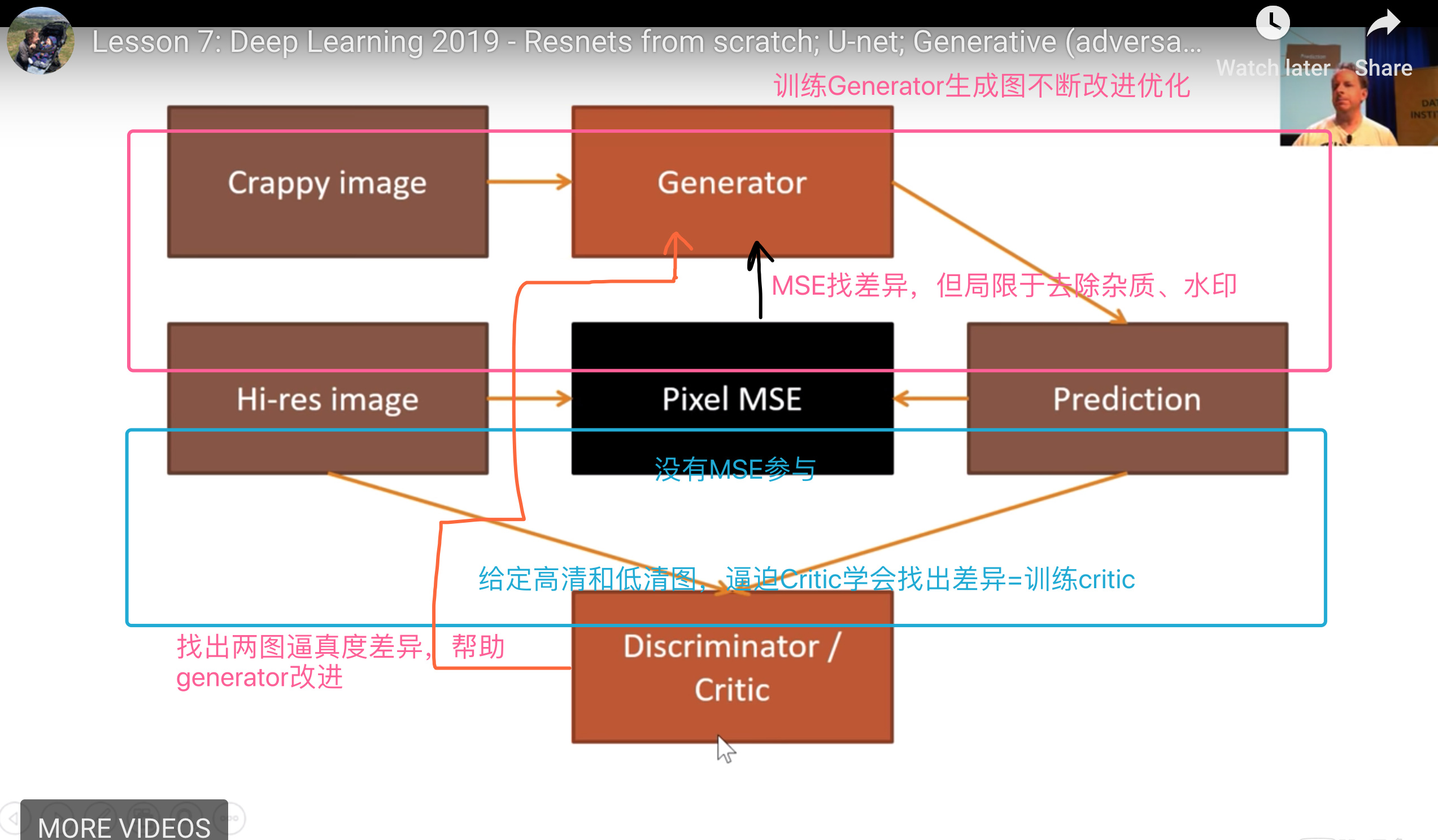
为什么GAN 训练很痛苦?
为什么GAN 训练很痛苦?
- 痛苦在起步,成功起步后就比较快了
- 为什么起步痛苦?
- 因为起步时生成器和分辨器都很无知,无法相互帮助促进
- 好比两个刚刚失明的人要帮助对方行走一样无助
fastai 版本的GAN如何解决这个问题?
fastai 版本的GAN如何解决这个问题?
- 提供预先训练好的生成器和辨别器,直接给出优秀的起步状态
- 这是fast.ai首创(极可能)
保存生成图到新文件夹
保存生成图到新文件夹
- 要训练critic (二元分类),需要原图和生成图对比
- 原图已有,生成图需要新生成
learn_gen.load('gen-pre2'); # 准备生成器模型
name_gen = 'image_gen'
path_gen = path/name_gen # 准备路径
# shutil.rmtree(path_gen)
path_gen.mkdir(exist_ok=True) # 创建文件夹
part2 会有更多自己写源代码的机会(如下)
def save_preds(dl):
i=0
names = dl.dataset.items # 提取文件路径
for b in dl: # 提取一个一个的批量
preds = learn_gen.pred_batch(batch=b, reconstruct=True) # 生成图
for o in preds:
o.save(path_gen/names[i].name) # 提成和保存到指定文件名
i += 1
save_preds(data_gen.fix_dl) # fix_dl ????
查看新生成文件夹中图片
PIL.Image.open(path_gen.ls()[0])

Train critic
如何释放空间,无需重启kernel?
如何释放空间,无需重启kernel?
learn_gen=None
gc.collect() # 能行,只是NVDIA msi 无法展示实际情况,因为Pytorch的设置
3755
Pretrain the critic on crappy vs not crappy.
如何生成critic DataBunch
如何生成critic DataBunch
def get_crit_data(classes, bs, size):
src = ImageList.from_folder(path, include=classes).random_split_by_pct(0.1, seed=42)
# path = PETS 总path, include=classes, subfolders 就是classes
ll = src.label_from_folder(classes=classes) # classes = subfolders (images, image_gen)
data = (ll.transform(get_transforms(max_zoom=2.), size=size)
.databunch(bs=bs).normalize(imagenet_stats))
data.c = 3
return data
data_crit = get_crit_data([name_gen, 'images'], bs=bs, size=size)
data_crit.show_batch(rows=3, ds_type=DatasetType.Train, imgsize=3) # 注意 imgsize=3

BCE loss + AdaptiveLoss ??
BCE loss + AdaptiveLoss ??
loss_critic = AdaptiveLoss(nn.BCEWithLogitsLoss())
如何创建critic模型Learner?
如何创建critic模型Learner?
- 模型框架需要spectral norm
- Resnet 内无此设置,未来可能会植入
- 目前采用gan_critic()模型框架, 内置了spectral norm
def create_critic_learner(data, metrics):
return Learner(data, gan_critic(), metrics=metrics, loss_func=loss_critic, wd=wd)
learn_critic = create_critic_learner(data_crit, accuracy_thresh_expand)
# accuracy_thresh_expand = 为GAN critic定制的accuracy
learn_critic.fit_one_cycle(6, 1e-3)
Total time: 09:40
| epoch | train_loss | valid_loss | accuracy_thresh_expand |
|---|---|---|---|
| 1 | 0.678256 | 0.687312 | 0.531083 |
| 2 | 0.434768 | 0.366180 | 0.851823 |
| 3 | 0.186435 | 0.128874 | 0.955214 |
| 4 | 0.120681 | 0.072901 | 0.980228 |
| 5 | 0.099568 | 0.107304 | 0.962564 |
| 6 | 0.071958 | 0.078094 | 0.976239 |
learn_critic.save('critic-pre2')
GAN
再度释放内容
Now we’ll combine those pretrained model in a GAN.
再度释放内容
learn_crit=None
learn_gen=None
gc.collect()
15794
创建databunch, critic和generator
创建databunch, critic和generator
data_crit = get_crit_data(['crappy', 'images'], bs=bs, size=size)
learn_crit = create_critic_learner(data_crit, metrics=None).load('critic-pre2')
learn_gen = create_gen_learner().load('gen-pre2')
fastai 如何简化GAN建模流程
fastai 如何简化GAN建模流程
To define a GAN Learner, we just have to specify the learner objects for the generator and the critic. The switcher is a callback that decides when to switch from discriminator to generator and vice versa. Here we do as many iterations of the discriminator as needed to get its loss back < 0.5 then one iteration of the generator.
The loss of the critic is given by learn_crit.loss_func. We take the average of this loss function on the batch of real predictions (target 1) and the batch of fake predicitions (target 0).
The loss of the generator is weighted sum (weights in weights_gen) of learn_crit.loss_func on the batch of fake (passed throught the critic to become predictions) with a target of 1, and the learn_gen.loss_func applied to the output (batch of fake) and the target (corresponding batch of superres images).
switcher = partial(AdaptiveGANSwitcher, critic_thresh=0.65)
learn = GANLearner.from_learners(learn_gen, learn_crit,
weights_gen=(1.,50.), # MSEpixel loss set 50x larger,
# critic loss set just 1 scale
show_img=False, switcher=switcher,
# set momentum to 0 in betas, 因为GAN不喜欢momentum
opt_func=partial(optim.Adam, betas=(0.,0.99)), wd=wd)
learn.callback_fns.append(partial(GANDiscriminativeLR, mult_lr=5.))
lr = 1e-4
learn.fit(40,lr)
Total time: 1:05:41
| epoch | train_loss | gen_loss | disc_loss |
|---|---|---|---|
| 1 | 2.071352 | 2.025429 | 4.047686 |
| 2 | 1.996251 | 1.850199 | 3.652173 |
| 3 | 2.001999 | 2.035176 | 3.612669 |
| 4 | 1.921844 | 1.931835 | 3.600355 |
| 5 | 1.987216 | 1.961323 | 3.606629 |
| 6 | 2.022372 | 2.102732 | 3.609494 |
| 7 | 1.900056 | 2.059208 | 3.581742 |
| 8 | 1.942305 | 1.965547 | 3.538015 |
| 9 | 1.954079 | 2.006257 | 3.593008 |
| 10 | 1.984677 | 1.771790 | 3.617556 |
| 11 | 2.040979 | 2.079904 | 3.575464 |
| 12 | 2.009052 | 1.739175 | 3.626755 |
| 13 | 2.014115 | 1.204614 | 3.582353 |
| 14 | 2.042148 | 1.747239 | 3.608723 |
| 15 | 2.113957 | 1.831483 | 3.684338 |
| 16 | 1.979398 | 1.923163 | 3.600483 |
| 17 | 1.996756 | 1.760739 | 3.635300 |
| 18 | 1.976695 | 1.982629 | 3.575843 |
| 19 | 2.088960 | 1.822936 | 3.617471 |
| 20 | 1.949941 | 1.996513 | 3.594223 |
| 21 | 2.079416 | 1.918284 | 3.588732 |
| 22 | 2.055047 | 1.869254 | 3.602390 |
| 23 | 1.860164 | 1.917518 | 3.557776 |
| 24 | 1.945440 | 2.033273 | 3.535242 |
| 25 | 2.026493 | 1.804196 | 3.558001 |
| 26 | 1.875208 | 1.797288 | 3.511697 |
| 27 | 1.972286 | 1.798044 | 3.570746 |
| 28 | 1.950635 | 1.951106 | 3.525849 |
| 29 | 2.013820 | 1.937439 | 3.592216 |
| 30 | 1.959477 | 1.959566 | 3.561970 |
| 31 | 2.012466 | 2.110288 | 3.539897 |
| 32 | 1.982466 | 1.905378 | 3.559940 |
| 33 | 1.957023 | 2.207354 | 3.540873 |
| 34 | 2.049188 | 1.942845 | 3.638360 |
| 35 | 1.913136 | 1.891638 | 3.581291 |
| 36 | 2.037127 | 1.808180 | 3.572567 |
| 37 | 2.006383 | 2.048738 | 3.553226 |
| 38 | 2.000312 | 1.657985 | 3.594805 |
| 39 | 1.973937 | 1.891186 | 3.533843 |
| 40 | 2.002513 | 1.853988 | 3.554688 |
learn.save('gan-1c')
learn.data=get_data(16,192)
learn.fit(10,lr/2)
Total time: 43:07
| epoch | train_loss | gen_loss | disc_loss |
|---|---|---|---|
| 1 | 2.578580 | 2.415008 | 4.716179 |
| 2 | 2.620808 | 2.487282 | 4.729377 |
| 3 | 2.596190 | 2.579693 | 4.796489 |
| 4 | 2.701113 | 2.522197 | 4.821410 |
| 5 | 2.545030 | 2.401921 | 4.710739 |
| 6 | 2.638539 | 2.548171 | 4.776103 |
| 7 | 2.551988 | 2.513859 | 4.644952 |
| 8 | 2.629724 | 2.490307 | 4.701890 |
| 9 | 2.552170 | 2.487726 | 4.728183 |
| 10 | 2.597136 | 2.478334 | 4.649708 |
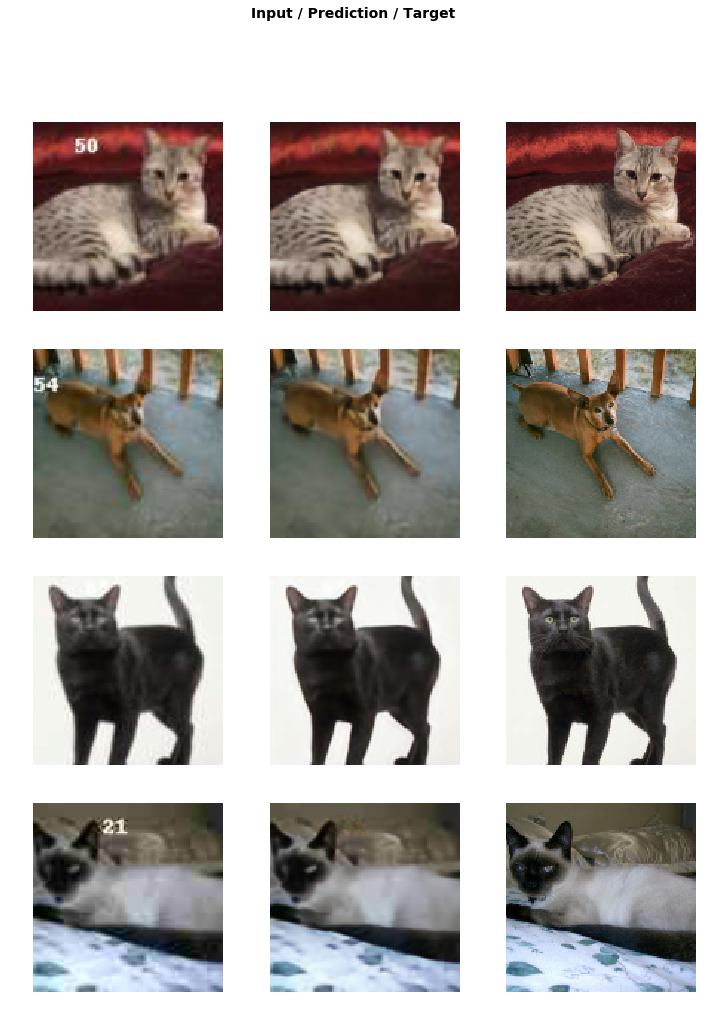
learn.show_results(rows=16)

learn.save('gan-1c')
Lesson 7 WGAN
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.vision import *
from fastai.vision.gan import *
下载数据(部分数据,源于Kaggle)
下载数据(部分数据,源于Kaggle)
LSun bedroom data
For this lesson, we’ll be using the bedrooms from the LSUN dataset. The full dataset is a bit too large so we’ll use a sample from kaggle.
path = untar_data(URLs.LSUN_BEDROOMS)
如何构建databunch
如何构建databunch
We then grab all the images in the folder with the data block API. We don’t create a validation set here for reasons we’ll explain later. It consists of random noise of size 100 by default (can be changed below) as inputs and the images of bedrooms as targets. That’s why we do tfm_y=True in the transforms, then apply the normalization to the ys and not the xs.
def get_data(bs, size):
return (GANItemList.from_folder(path, noise_sz=100) # noise as inputs, image as targets
.no_split()
.label_from_func(noop) # what is noop?
.transform(tfms=[[crop_pad(size=size, row_pct=(0,1), col_pct=(0,1))], []],
size=size,
tfm_y=True) # transform to y not x
.databunch(bs=bs)
.normalize(stats = [torch.tensor([0.5,0.5,0.5]), torch.tensor([0.5,0.5,0.5])],
do_x=False, do_y=True)) # normalize y not x
从小尺寸数据开始训练
从小尺寸数据开始训练
We’ll begin with a small side and use gradual resizing.
data = get_data(128, 64)
data.show_batch(rows=5)

Models
如何理解GAN 的工作原理
如何理解GAN 的工作原理
GAN stands for Generative Adversarial Nets and were invented by Ian Goodfellow. The concept is that we will train two models at the same time: a generator and a critic. The generator will try to make new images similar to the ones in our dataset, and the critic will try to classify real images from the ones the generator does. The generator returns images, the critic a single number (usually 0. for fake images and 1. for real ones).
We train them against each other in the sense that at each step (more or less), we:
- Freeze the generator and train the critic for one step by:
- getting one batch of true images (let’s call that
real) - generating one batch of fake images (let’s call that
fake) - have the critic evaluate each batch and compute a loss function from that; the important part is that it rewards positively the detection of real images and penalizes the fake ones
- update the weights of the critic with the gradients of this loss
- Freeze the critic and train the generator for one step by:
- generating one batch of fake images
- evaluate the critic on it
- return a loss that rewards posisitivly the critic thinking those are real images; the important part is that it rewards positively the detection of real images and penalizes the fake ones
- update the weights of the generator with the gradients of this loss
Here, we’ll use the Wassertein GAN.
We create a generator and a critic that we pass to gan_learner. The noise_size is the size of the random vector from which our generator creates images.
如何生成简单的generator and critic
如何生成简单的generator and critic
generator = basic_generator(in_size=64, n_channels=3, n_extra_layers=1)
critic = basic_critic (in_size=64, n_channels=3, n_extra_layers=1)
如何构建wgan learner
如何构建wgan learner
learn = GANLearner.wgan(data, generator, critic, switch_eval=False,
opt_func = partial(optim.Adam, betas = (0.,0.99)), wd=0.)
learn.fit(30,2e-4)
Total time: 1:54:23
| epoch | train_loss | gen_loss | disc_loss |
|---|---|---|---|
| 1 | -0.842719 | 0.542895 | -1.086206 |
| 2 | -0.799776 | 0.539448 | -1.067940 |
| 3 | -0.738768 | 0.538581 | -1.015152 |
| 4 | -0.718174 | 0.484403 | -0.943485 |
| 5 | -0.570070 | 0.428915 | -0.777247 |
| 6 | -0.545130 | 0.413026 | -0.749381 |
| 7 | -0.541453 | 0.389443 | -0.719322 |
| 8 | -0.469548 | 0.356602 | -0.642670 |
| 9 | -0.434924 | 0.329100 | -0.598782 |
| 10 | -0.416448 | 0.301526 | -0.558442 |
| 11 | -0.389224 | 0.292355 | -0.532662 |
| 12 | -0.361795 | 0.266539 | -0.494872 |
| 13 | -0.363674 | 0.245725 | -0.475951 |
| 14 | -0.318343 | 0.227446 | -0.432148 |
| 15 | -0.309221 | 0.203628 | -0.417945 |
| 16 | -0.300667 | 0.213194 | -0.401034 |
| 17 | -0.282622 | 0.187128 | -0.381643 |
| 18 | -0.283902 | 0.156653 | -0.374541 |
| 19 | -0.267852 | 0.159612 | -0.346919 |
| 20 | -0.257258 | 0.163018 | -0.344198 |
| 21 | -0.242090 | 0.159207 | -0.323443 |
| 22 | -0.255733 | 0.129341 | -0.322228 |
| 23 | -0.235854 | 0.143768 | -0.305106 |
| 24 | -0.220397 | 0.115682 | -0.289971 |
| 25 | -0.233782 | 0.135361 | -0.294088 |
| 26 | -0.202050 | 0.142435 | -0.279994 |
| 27 | -0.196104 | 0.119580 | -0.265333 |
| 28 | -0.204124 | 0.119595 | -0.266063 |
| 29 | -0.204096 | 0.131431 | -0.264097 |
| 30 | -0.183655 | 0.128817 | -0.254156 |


Lesson 7 superres and feature loss
perceptual loss paper
demo and brilliant outcome
Super resolution
所需library
所需library
import fastai
from fastai.vision import *
from fastai.callbacks import *
from fastai.utils.mem import *
from torchvision.models import vgg16_bn
下载数据,准备文件夹路径
下载数据,准备文件夹路径
path = untar_data(URLs.PETS)
path_hr = path/'images' # high
path_lr = path/'small-96' # low
path_mr = path/'small-256' # medium
从原图中生成Image List il
从原图中生成Image List il
il = ImageList.from_folder(path_hr)
设计crappify函数
设计crappify函数
def resize_one(fn, i, path, size):
dest = path/fn.relative_to(path_hr)
dest.parent.mkdir(parents=True, exist_ok=True)
img = PIL.Image.open(fn)
targ_sz = resize_to(img, size, use_min=True)
img = img.resize(targ_sz, resample=PIL.Image.BILINEAR).convert('RGB')
img.save(dest, quality=60)
生成low和medium两个文件夹图片(parallel)
生成low和medium两个文件夹图片(parallel)
# create smaller image sets the first time this nb is run
sets = [(path_lr, 96), (path_mr, 256)]
for p,size in sets:
if not p.exists():
print(f"resizing to {size} into {p}")
parallel(partial(resize_one, path=p, size=size), il.items)
构建src, 采用ImageImageList, 采用low images作为训练Xfeatures 图
构建src, 采用ImageImageList, 采用low images作为训练Xfeatures 图
bs,size=32,128
arch = models.resnet34
src = ImageImageList.from_folder(path_lr).random_split_by_pct(0.1, seed=42)
设置生成DataBunch函数,将high image 作为label, 只对y做变形和normalize
设置生成DataBunch函数,将high image 作为label, 只对y做变形和normalize
def get_data(bs,size):
data = (src.label_from_func(lambda x: path_hr/x.name)
.transform(get_transforms(max_zoom=2.), size=size, tfm_y=True)
.databunch(bs=bs).normalize(imagenet_stats, do_y=True))
data.c = 3
return data
data = get_data(bs,size)
data.show_batch(ds_type=DatasetType.Valid, rows=2, figsize=(9,9))

Feature loss
gram_matrix

gram_matrix
t = data.valid_ds[0][1].data
t = torch.stack([t,t])
def gram_matrix(x):
n,c,h,w = x.size()
x = x.view(n, c, -1)
return (x @ x.transpose(1,2))/(c*h*w)
gram_matrix(t)
tensor([[[0.0759, 0.0711, 0.0643],
[0.0711, 0.0672, 0.0614],
[0.0643, 0.0614, 0.0573]],
[[0.0759, 0.0711, 0.0643],
[0.0711, 0.0672, 0.0614],
[0.0643, 0.0614, 0.0573]]])
base loss L1
base loss L1
base_loss = F.l1_loss # MSE and L1 没有本质区别,但Jeremy喜欢L1
调用pretrained model vgg
调用pretrained model vgg
vgg_m = vgg16_bn(True).features.cuda().eval() # 提取中间层特征,不取heads
requires_grad(vgg_m, False) # 不更新中间层的参数值
获取所有中间层,在变化grid size之前的
获取所有中间层,在变化grid size之前的
blocks = [i-1 for i,o in enumerate(children(vgg_m)) if isinstance(o,nn.MaxPool2d)]
blocks, [vgg_m[i] for i in blocks]
([5, 12, 22, 32, 42],
[ReLU(inplace), ReLU(inplace), ReLU(inplace), ReLU(inplace), ReLU(inplace)])
设计Feature loss
设计Feature loss
class FeatureLoss(nn.Module):
def __init__(self, m_feat, layer_ids, layer_wgts):
super().__init__()
self.m_feat = m_feat
# get features of all the layers
self.loss_features = [self.m_feat[i] for i in layer_ids]
# 通过hooks来获取哪些layers的features
self.hooks = hook_outputs(self.loss_features, detach=False)
self.wgts = layer_wgts
self.metric_names = ['pixel',] + [f'feat_{i}' for i in range(len(layer_ids))
] + [f'gram_{i}' for i in range(len(layer_ids))]
def make_features(self, x, clone=False):
self.m_feat(x)
return [(o.clone() if clone else o) for o in self.hooks.stored]
def forward(self, input, target):
out_feat = self.make_features(target, clone=True)
in_feat = self.make_features(input)
self.feat_losses = [base_loss(input,target)] # 计算L1
# 计算每一个挑选出来中间层的L1
self.feat_losses += [base_loss(f_in, f_out)*w
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
self.feat_losses += [base_loss(gram_matrix(f_in), gram_matrix(f_out))*w**2 * 5e3
for f_in, f_out, w in zip(in_feat, out_feat, self.wgts)]
# 这个callbacks可以方便打印出每一个中间层的loss
self.metrics = dict(zip(self.metric_names, self.feat_losses))
return sum(self.feat_losses)
def __del__(self): self.hooks.remove()
feat_loss = FeatureLoss(vgg_m, blocks[2:5], [5,15,2])
Train
构建含有feature loss的Unet
构建含有feature loss的Unet
wd = 1e-3
learn = unet_learner(data, arch, wd=wd, loss_func=feat_loss, callback_fns=LossMetrics,
blur=True, norm_type=NormType.Weight)
gc.collect();
learn.lr_find()
learn.recorder.plot()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
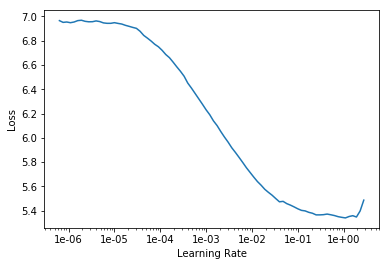
lr = 1e-3
封冻训练
封冻训练
def do_fit(save_name, lrs=slice(lr), pct_start=0.9):
learn.fit_one_cycle(10, lrs, pct_start=pct_start)
learn.save(save_name)
learn.show_results(rows=1, imgsize=5)
do_fit('1a', slice(lr*10))
Total time: 11:16
| epoch | train_loss | valid_loss | pixel | feat_0 | feat_1 | feat_2 | gram_0 | gram_1 | gram_2 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3.873667 | 3.759143 | 0.144560 | 0.229806 | 0.314573 | 0.226204 | 0.552578 | 1.201812 | 1.089610 |
| 2 | 3.756051 | 3.650393 | 0.145068 | 0.228509 | 0.308807 | 0.218000 | 0.534508 | 1.164112 | 1.051389 |
| 3 | 3.688726 | 3.628370 | 0.157359 | 0.226753 | 0.304955 | 0.215417 | 0.522482 | 1.157941 | 1.043464 |
| 4 | 3.628276 | 3.524132 | 0.145285 | 0.225455 | 0.300169 | 0.211110 | 0.497361 | 1.124274 | 1.020478 |
| 5 | 3.586930 | 3.422895 | 0.145161 | 0.224946 | 0.294471 | 0.205117 | 0.472445 | 1.089540 | 0.991215 |
| 6 | 3.528042 | 3.394804 | 0.142262 | 0.220709 | 0.289961 | 0.201980 | 0.478097 | 1.083557 | 0.978238 |
| 7 | 3.522416 | 3.361185 | 0.139654 | 0.220379 | 0.288046 | 0.200114 | 0.471151 | 1.069787 | 0.972054 |
| 8 | 3.469142 | 3.338554 | 0.142112 | 0.219271 | 0.287442 | 0.199255 | 0.462878 | 1.059909 | 0.967688 |
| 9 | 3.418641 | 3.318710 | 0.146493 | 0.219915 | 0.284979 | 0.197340 | 0.455503 | 1.055662 | 0.958817 |
| 10 | 3.356641 | 3.187186 | 0.135588 | 0.215685 | 0.277398 | 0.189562 | 0.432491 | 1.018626 | 0.917836 |

解冻训练
解冻训练
learn.unfreeze()
do_fit('1b', slice(1e-5,lr))
Total time: 11:39
| epoch | train_loss | valid_loss | pixel | feat_0 | feat_1 | feat_2 | gram_0 | gram_1 | gram_2 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3.303951 | 3.179916 | 0.135630 | 0.216009 | 0.277359 | 0.189097 | 0.430012 | 1.016279 | 0.915531 |
| 2 | 3.308164 | 3.174482 | 0.135740 | 0.215970 | 0.277178 | 0.188737 | 0.428630 | 1.015094 | 0.913132 |
| 3 | 3.294504 | 3.169184 | 0.135216 | 0.215401 | 0.276744 | 0.188395 | 0.428544 | 1.013393 | 0.911491 |
| 4 | 3.282376 | 3.160698 | 0.134830 | 0.215049 | 0.275767 | 0.187716 | 0.427314 | 1.010877 | 0.909144 |
| 5 | 3.301212 | 3.168623 | 0.135134 | 0.215388 | 0.276196 | 0.188382 | 0.427277 | 1.013294 | 0.912951 |
| 6 | 3.299340 | 3.159537 | 0.135039 | 0.214692 | 0.275285 | 0.187554 | 0.427840 | 1.011199 | 0.907929 |
| 7 | 3.291041 | 3.159207 | 0.134602 | 0.214618 | 0.275053 | 0.187660 | 0.428083 | 1.011112 | 0.908080 |
| 8 | 3.285271 | 3.147745 | 0.134923 | 0.214514 | 0.274702 | 0.187147 | 0.423032 | 1.007289 | 0.906138 |
| 9 | 3.279353 | 3.138624 | 0.136035 | 0.213191 | 0.273899 | 0.186854 | 0.420070 | 1.002823 | 0.905753 |
| 10 | 3.261495 | 3.124737 | 0.135016 | 0.213681 | 0.273402 | 0.185922 | 0.416460 | 0.999504 | 0.900752 |

选择更大数据图片尺寸,再训练
选择更大数据图片尺寸,再训练
data = get_data(12,size*2)
learn.data = data
learn.freeze()
gc.collect()
0
learn.load('1b');
do_fit('2a')
Total time: 43:44
| epoch | train_loss | valid_loss | pixel | feat_0 | feat_1 | feat_2 | gram_0 | gram_1 | gram_2 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.249253 | 2.214517 | 0.164514 | 0.260366 | 0.294164 | 0.155227 | 0.385168 | 0.579109 | 0.375967 |
| 2 | 2.205854 | 2.194439 | 0.165290 | 0.260485 | 0.293195 | 0.154746 | 0.374004 | 0.573164 | 0.373555 |
| 3 | 2.184805 | 2.165699 | 0.165945 | 0.260999 | 0.291515 | 0.153438 | 0.361207 | 0.562997 | 0.369598 |
| 4 | 2.145655 | 2.159977 | 0.167295 | 0.260605 | 0.290226 | 0.152415 | 0.359476 | 0.563301 | 0.366659 |
| 5 | 2.141847 | 2.134954 | 0.168590 | 0.260219 | 0.288206 | 0.151237 | 0.348900 | 0.554701 | 0.363101 |
| 6 | 2.145108 | 2.128984 | 0.164906 | 0.259023 | 0.286386 | 0.150245 | 0.352594 | 0.555004 | 0.360826 |
| 7 | 2.115003 | 2.125632 | 0.169696 | 0.259949 | 0.286435 | 0.150898 | 0.344849 | 0.552517 | 0.361287 |
| 8 | 2.109859 | 2.111335 | 0.166503 | 0.258512 | 0.283750 | 0.148191 | 0.347635 | 0.549907 | 0.356835 |
| 9 | 2.092685 | 2.097898 | 0.169842 | 0.259169 | 0.284757 | 0.148156 | 0.333462 | 0.546337 | 0.356175 |
| 10 | 2.061421 | 2.080940 | 0.167636 | 0.257998 | 0.282682 | 0.147471 | 0.330893 | 0.540319 | 0.353941 |

learn.unfreeze()
do_fit('2b', slice(1e-6,1e-4), pct_start=0.3)
Total time: 45:19
| epoch | train_loss | valid_loss | pixel | feat_0 | feat_1 | feat_2 | gram_0 | gram_1 | gram_2 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.061799 | 2.078714 | 0.167578 | 0.257674 | 0.282523 | 0.147208 | 0.330824 | 0.539797 | 0.353109 |
| 2 | 2.063589 | 2.077507 | 0.167022 | 0.257501 | 0.282275 | 0.146879 | 0.331494 | 0.539560 | 0.352776 |
| 3 | 2.057191 | 2.074605 | 0.167656 | 0.257041 | 0.282204 | 0.146925 | 0.330117 | 0.538417 | 0.352247 |
| 4 | 2.050781 | 2.073395 | 0.166610 | 0.256625 | 0.281680 | 0.146585 | 0.331580 | 0.538651 | 0.351665 |
| 5 | 2.054705 | 2.068747 | 0.167527 | 0.257295 | 0.281612 | 0.146392 | 0.327932 | 0.536814 | 0.351174 |
| 6 | 2.052745 | 2.067573 | 0.167166 | 0.256741 | 0.281354 | 0.146101 | 0.328510 | 0.537147 | 0.350554 |
| 7 | 2.051863 | 2.067076 | 0.167222 | 0.257276 | 0.281607 | 0.146188 | 0.327575 | 0.536701 | 0.350506 |
| 8 | 2.046788 | 2.064326 | 0.167110 | 0.257002 | 0.281313 | 0.146055 | 0.326947 | 0.535760 | 0.350139 |
| 9 | 2.054460 | 2.065581 | 0.167222 | 0.257077 | 0.281246 | 0.146016 | 0.327586 | 0.536377 | 0.350057 |
| 10 | 2.052605 | 2.064459 | 0.166879 | 0.256835 | 0.281252 | 0.146135 | 0.327505 | 0.535734 | 0.350118 |

验证模型的好坏,采用medium input image来提升像素,看效果
验证模型的好坏,采用medium input image来提升像素,看效果
Test
learn = None
gc.collect();
256/320*1024
819.2
256/320*1600
1280.0
free = gpu_mem_get_free_no_cache()
# the max size of the test image depends on the available GPU RAM
if free > 8000: size=(1280, 1600) # > 8GB RAM
else: size=( 820, 1024) # <= 8GB RAM
print(f"using size={size}, have {free}MB of GPU RAM free")
using size=(820, 1024), have 7552MB of RAM free
learn = unet_learner(data, arch, loss_func=F.l1_loss, blur=True, norm_type=NormType.Weight)
data_mr = (ImageImageList.from_folder(path_mr).random_split_by_pct(0.1, seed=42)
.label_from_func(lambda x: path_hr/x.name)
.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=1).normalize(imagenet_stats, do_y=True))
data_mr.c = 3
learn.load('2b');
learn.data = data_mr
fn = data_mr.valid_ds.x.items[0]; fn
PosixPath('/data1/jhoward/git/course-v3/nbs/dl1/data/oxford-iiit-pet/small-256/Siamese_178.jpg')
img = open_image(fn); img.shape
torch.Size([3, 256, 320])
p,img_hr,b = learn.predict(img)
show_image(img, figsize=(18,15), interpolation='nearest');

Image(img_hr).show(figsize=(18,15))
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

如何一步一步做pull request
为什么以及前提要求
This is a visual guide to do a pull request (PR) on fastai library document source files (ipybn), which will walk you through every step of pushing a PR.
I learnt to do PR from fastai PR guides and branch update, but more importantly I can’t get here without tons of help and support from @stas Stas Bekman on Documentation improvements. Many thanks to @stas ! This visual guide is one of my little contributions back to fast.ai community.
Before you start, you should first take a few minutes to learn the very basics of terminal and git. You can learn it from the terminal guide on fastai course site. Then you are free to move on.
Step 1 Get idea support from the forum
Step 1 Get idea support from the forum
When you have an idea on PR, please go to Documentation improvements to share your thought and get support.
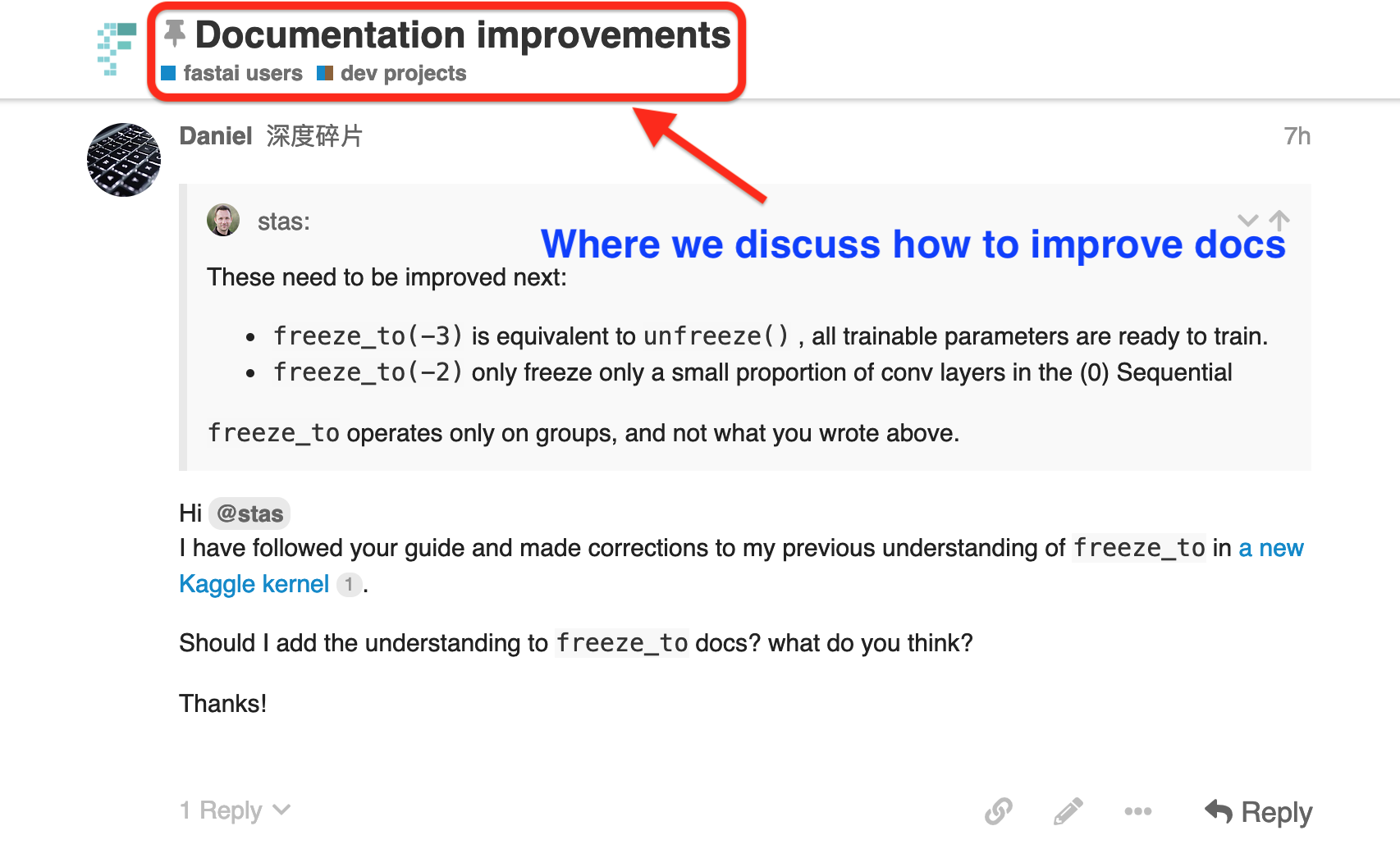
Step 2 Fork and download repo
Step 2 Fork and download repo
Click to fork the official repo as shown in the visual instruction below.
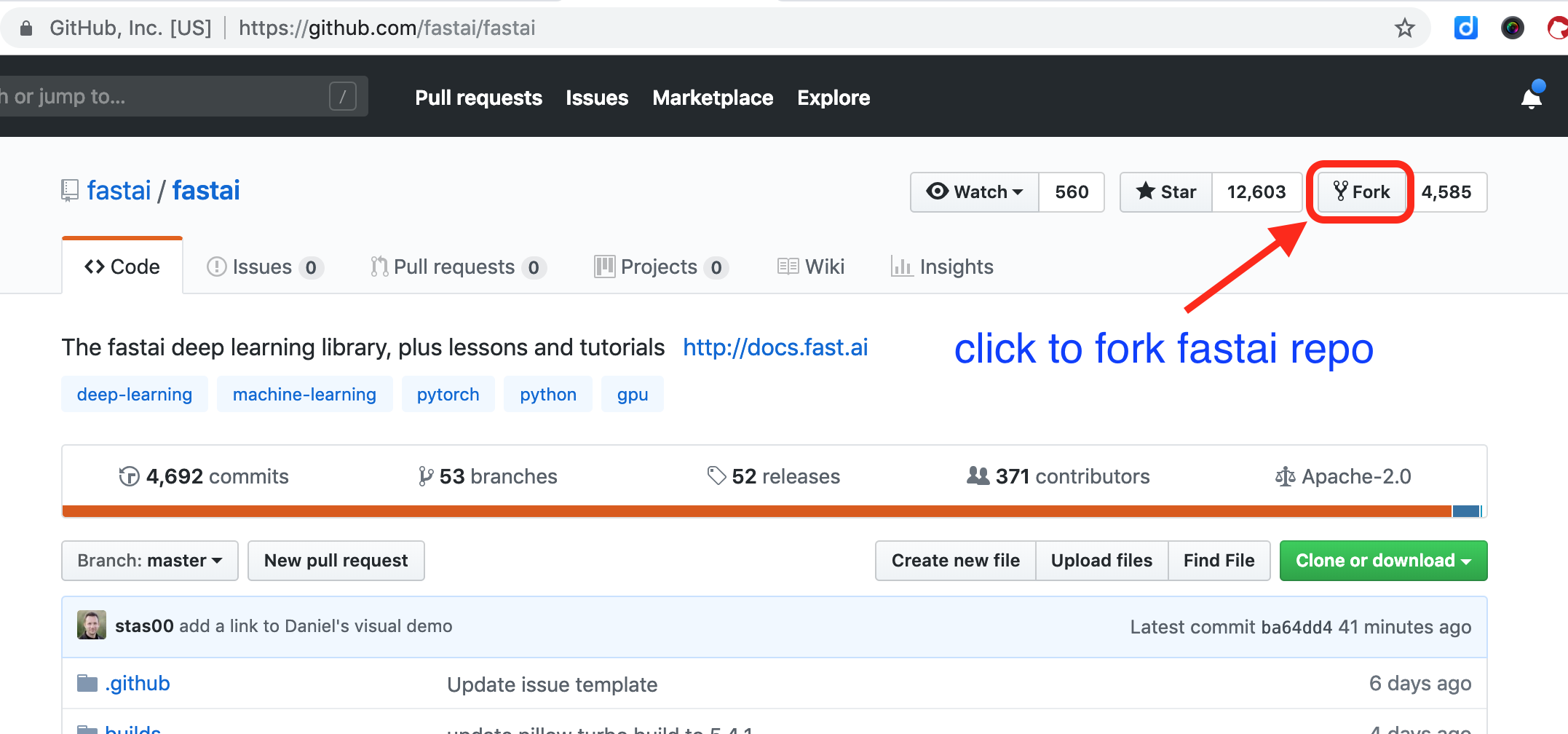
Then on your fork repo on github, copy the link.
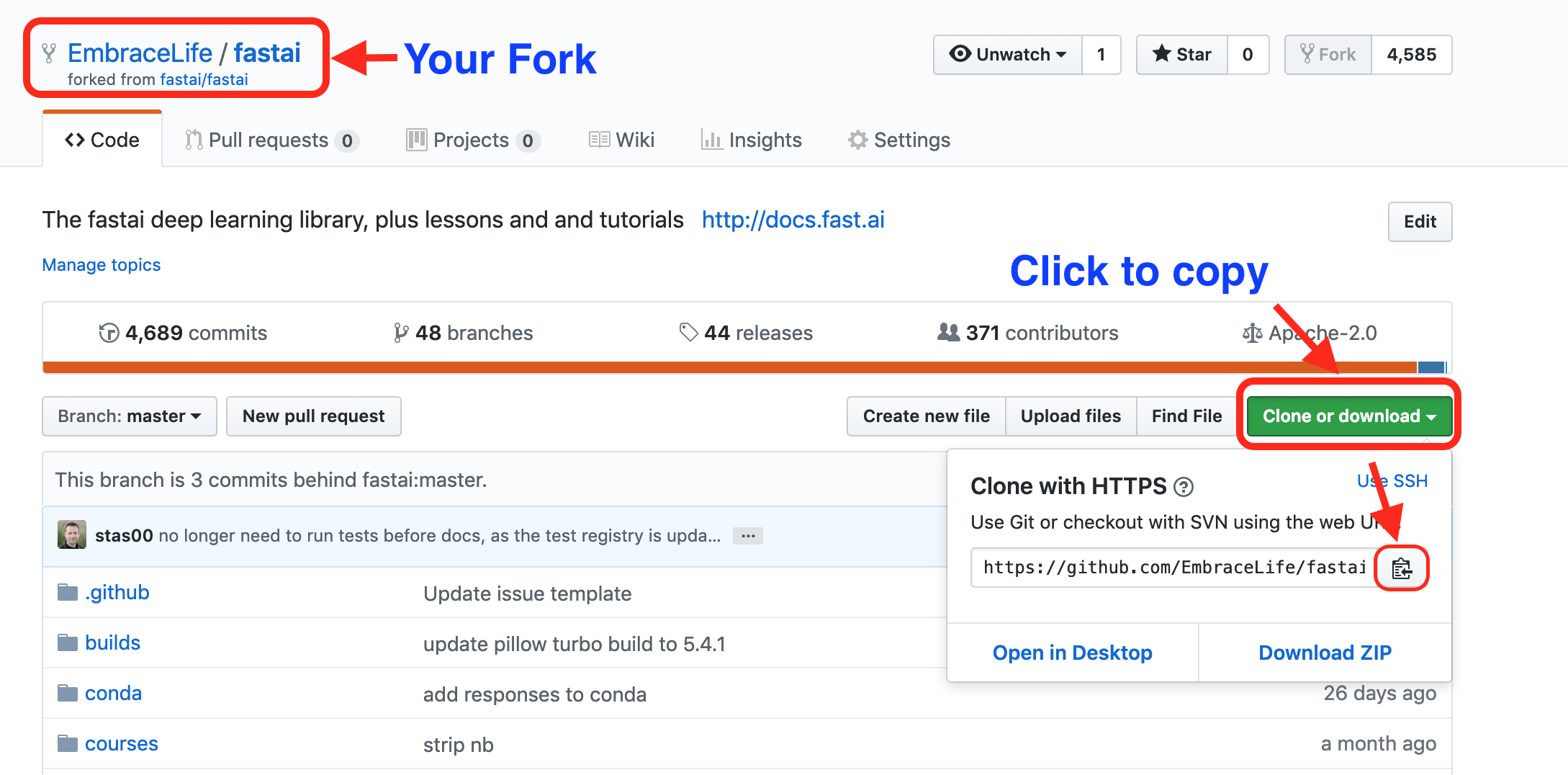
The last step to clone fastai repo to your local computer is to run the following code in your terminal.
cd your-fastai-fork-directory
git clone paste-your-copied-link-here
Step 3 Sync your fork and local repo with official repo
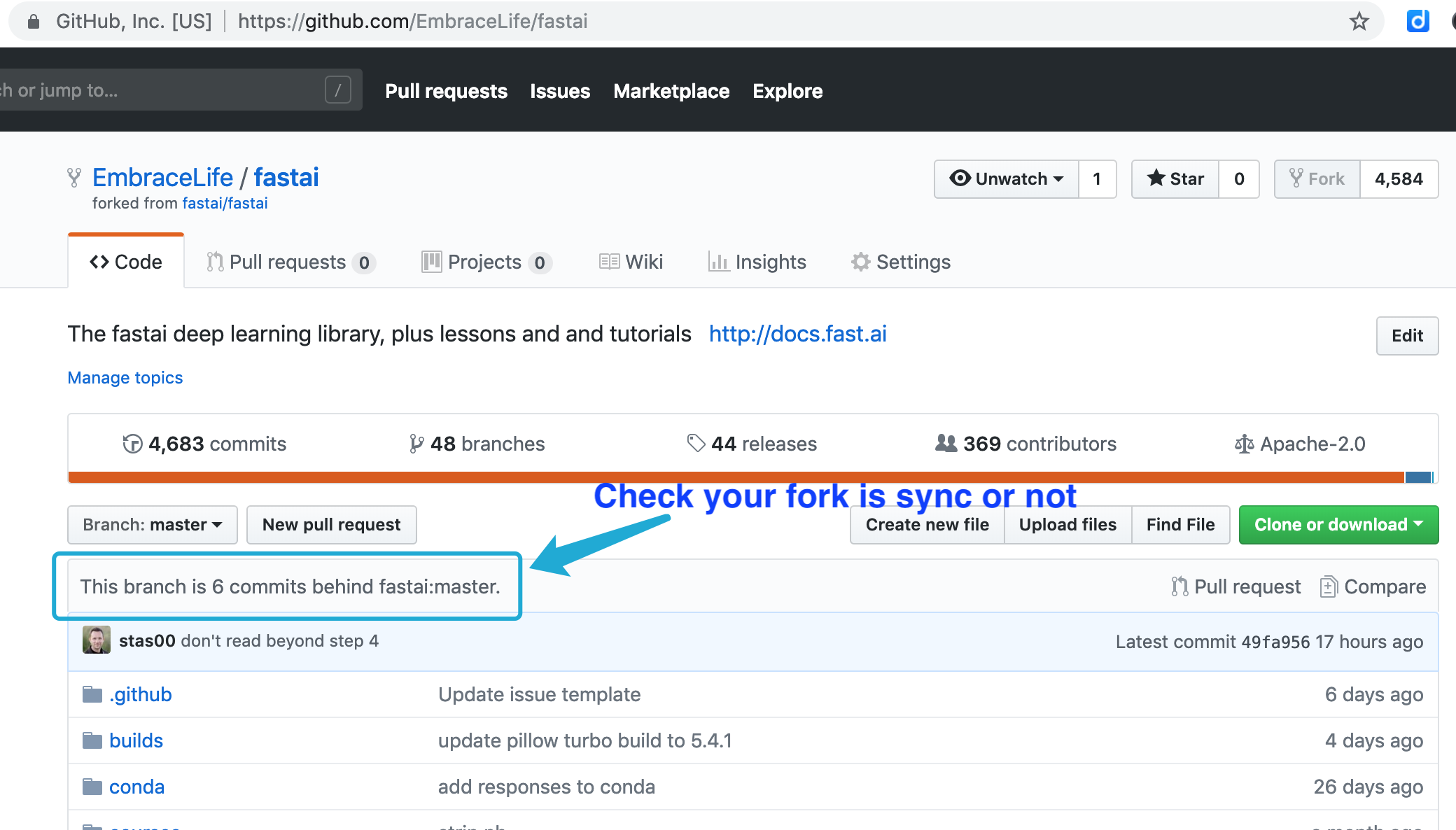
Step 3 Sync your fork and local repo with official repo
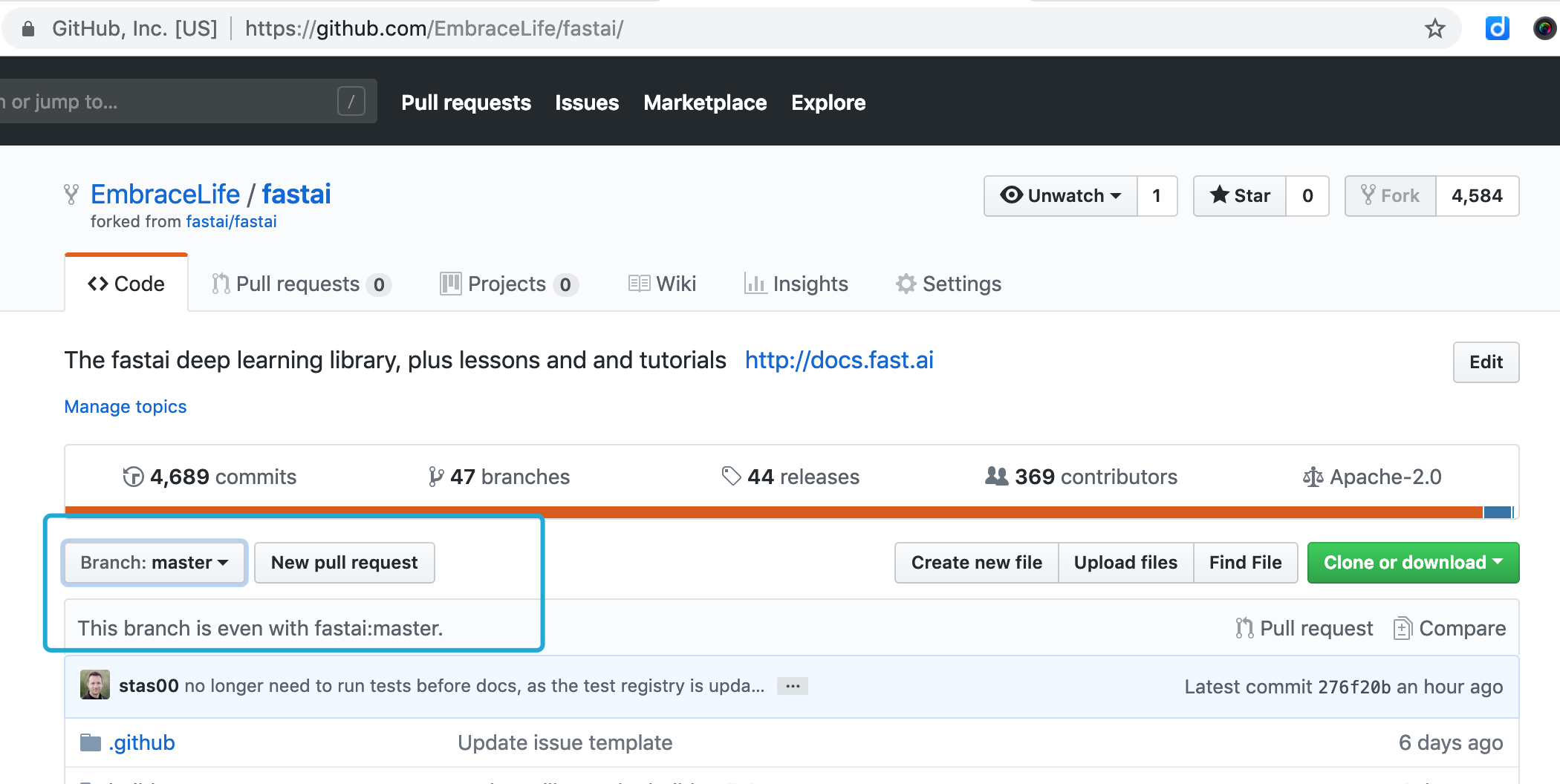
First, go to your fork on github to check whether it is updated. If not (seen image below), then you need to sync.
Then you can go to your terminal and step into your local repo directory (fastai-fork, in this visual example), and sync your local repo and official repo by following the steps in the image below.
You can sync your repo with official repo using the following codes:
cd my-cool-feature # your fastai fork clone directory
git fetch upstream
git checkout master
git merge --no-edit upstream/master
git push --set-upstream origin master
See my demo below
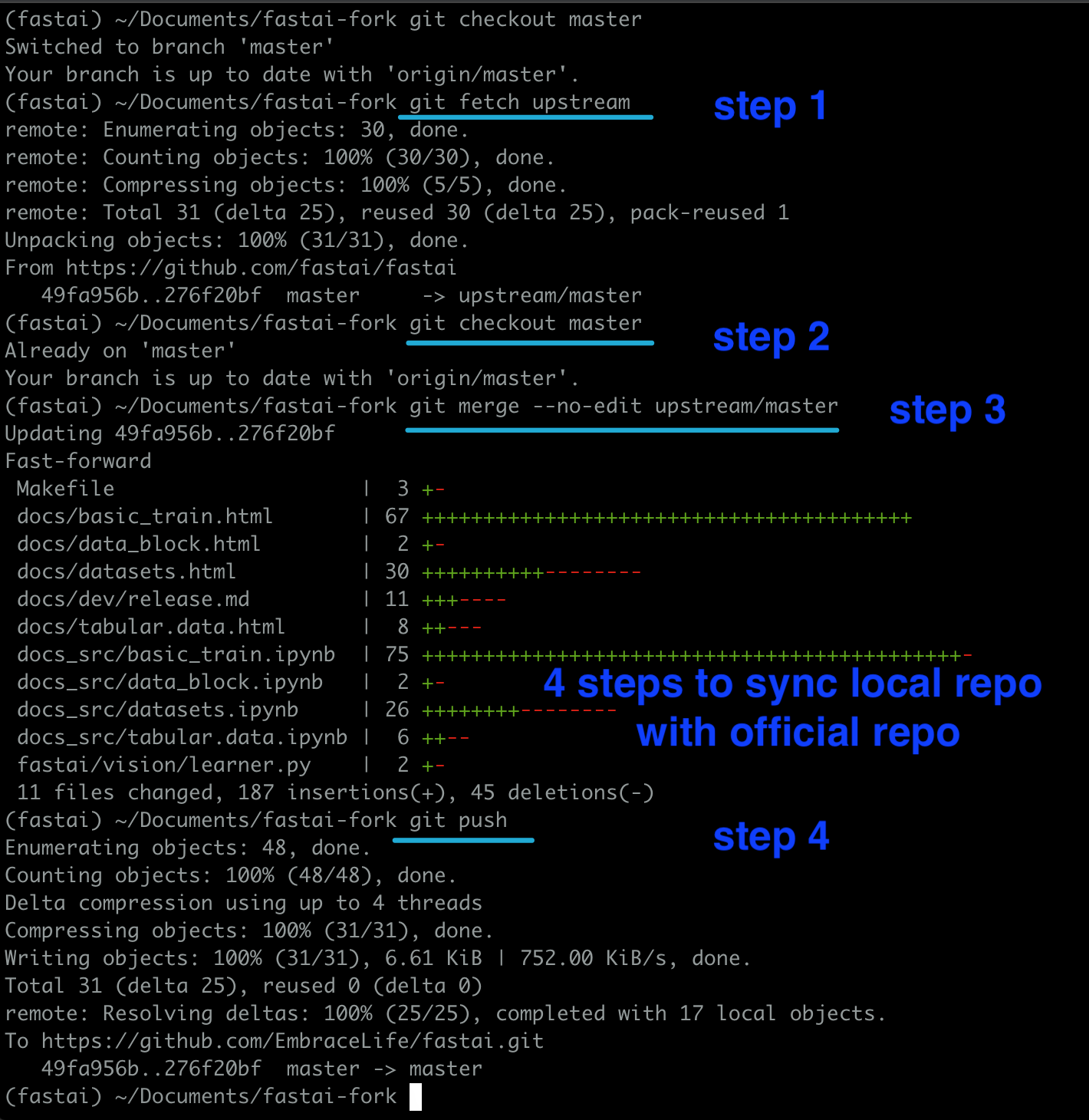
Then you can go to your fork to see whether the sync is a success or not.
Step 4 delete and create branches
Step 4 delete and create branches
If you have done PR before, you may want to delete your previous branch locally and on github. In this example, I have a branch called update-freeze-docsrc (see the blue box in the image below).
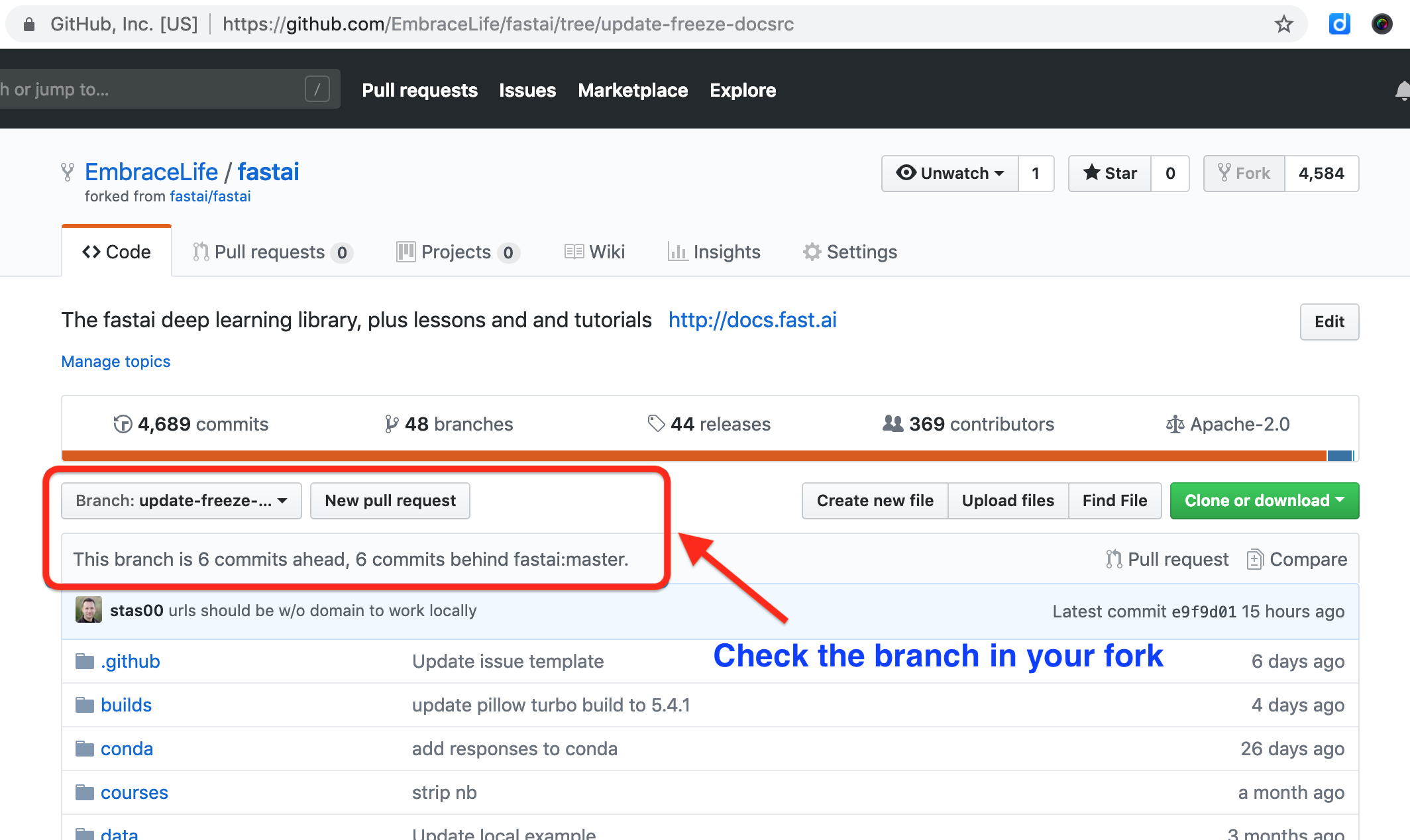
You can delete this branch locally and on github by following the first four steps in the image below.
git branch # to see which branch you are in
git checkout master # make sure to step out of the branch you want to delete
git branch -d branch-you-want-to-delete
git push origin --delete branch-you-want-to-delete
see my demo with ‘update-freeze-docsrc’ as the branch to be deleted.
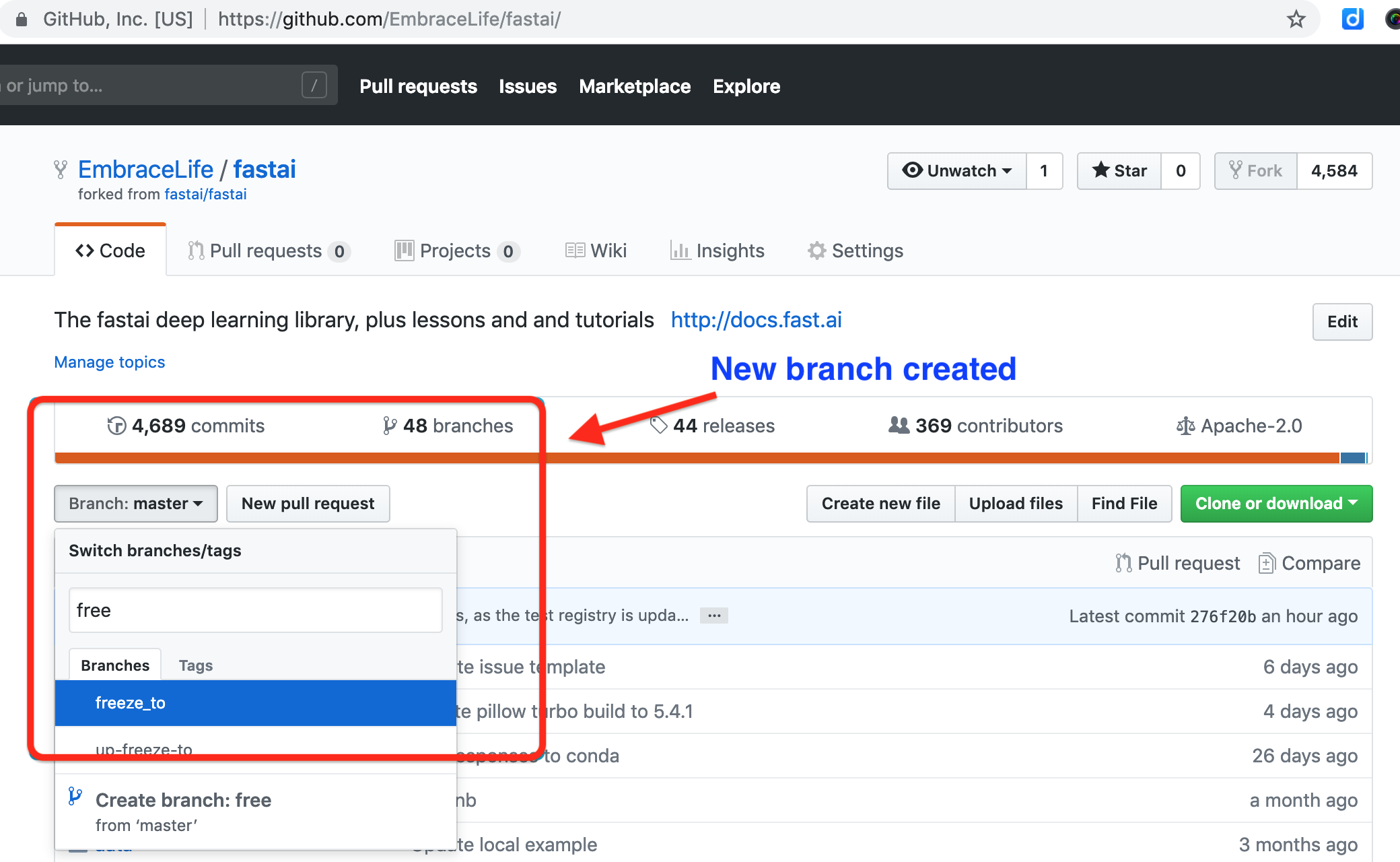
To create a new branch for your PR, you can run the following code in your terminal
git branch your-new-feature-branch
git checkout your-new-feature-branch
git merge origin/master
git push --set-upstream origin your-new-feature-branch
see my demo with ‘freeze_to’ as the branch to be created.
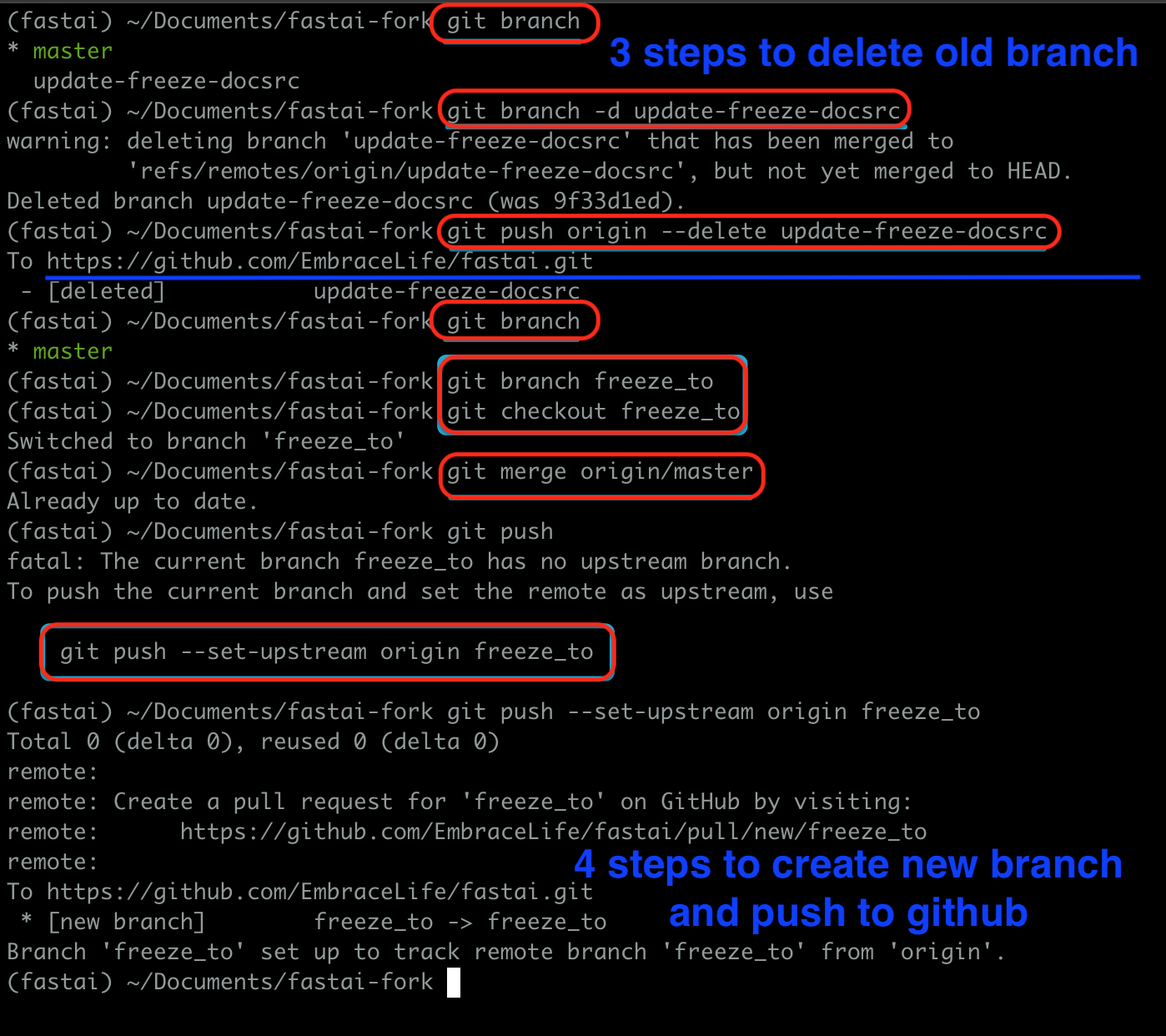
If you refresh the previous branch page on github, it won’t be found.
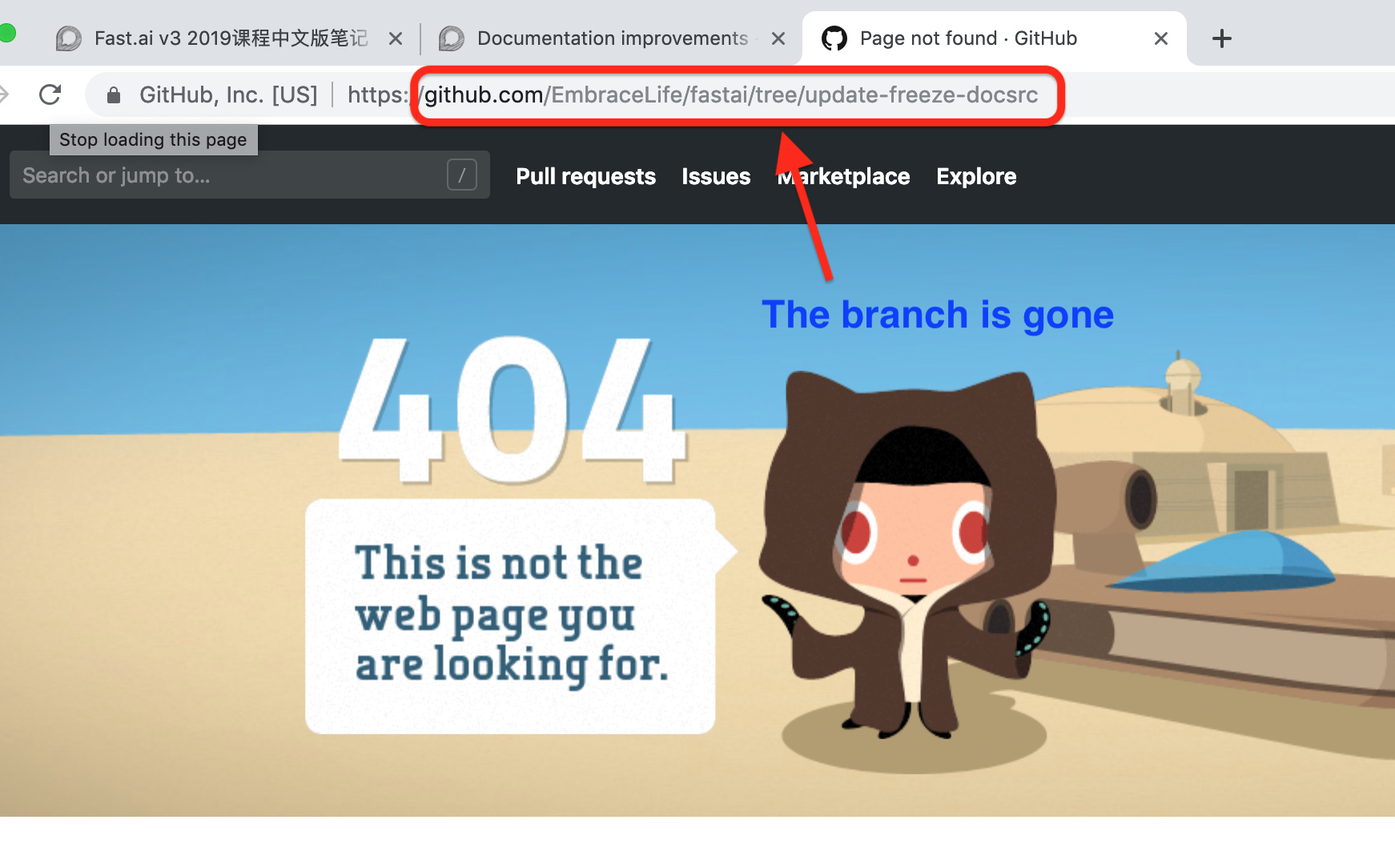
Also you will find a new branch created on your fork, see the box below.
Step 5 Make your edits
Step 5 Make your edits
You can make your edits of documentation and make it public with Kaggle kernels, so that people on Documentation improvement thread can see and give suggestions.
If you finally decided to make it a PR, then you can proceed to copy the changes onto the original ipynb file in your local repo.
Step 6 Push the changes
Step 6 Push the changes
You can check the changes you made to the original doc source ipynb by running the two lines of codes below.
git status
git diff the-file-you-edited
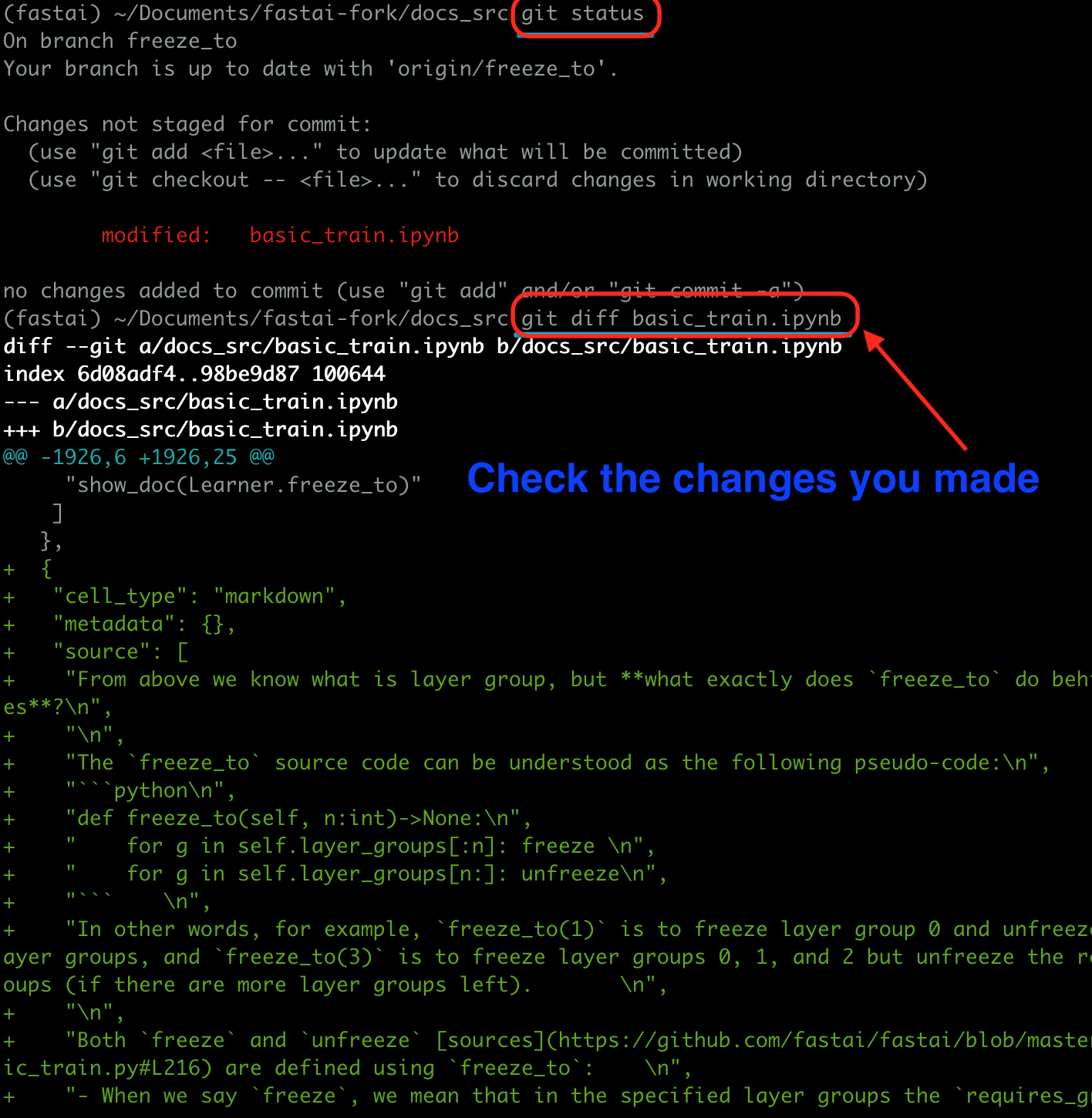
Then if the changes seem ok, you can run the following three lines of codes to push the changes to your fork.
git add .
git commit -a -m 'your message'
git push
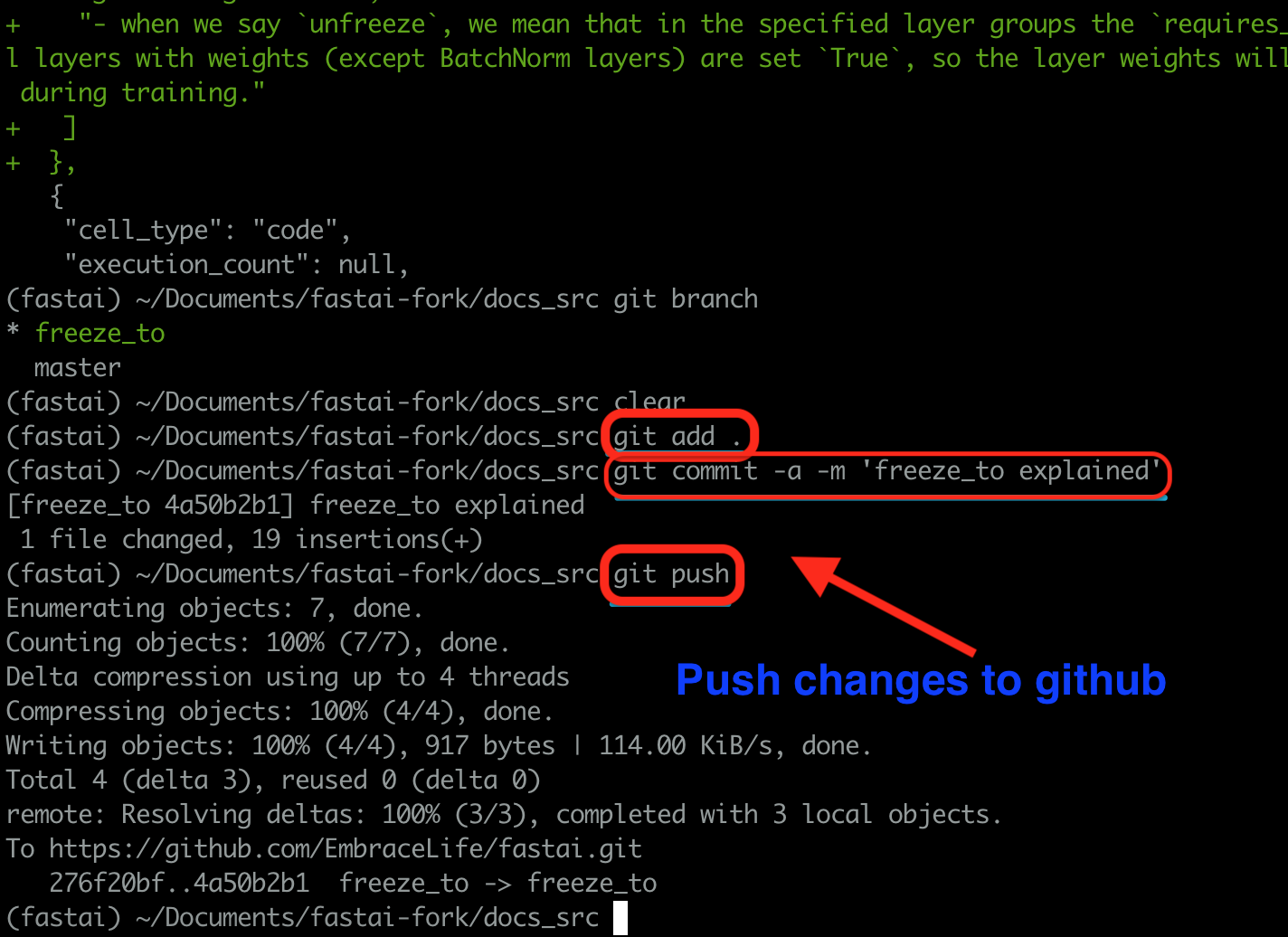
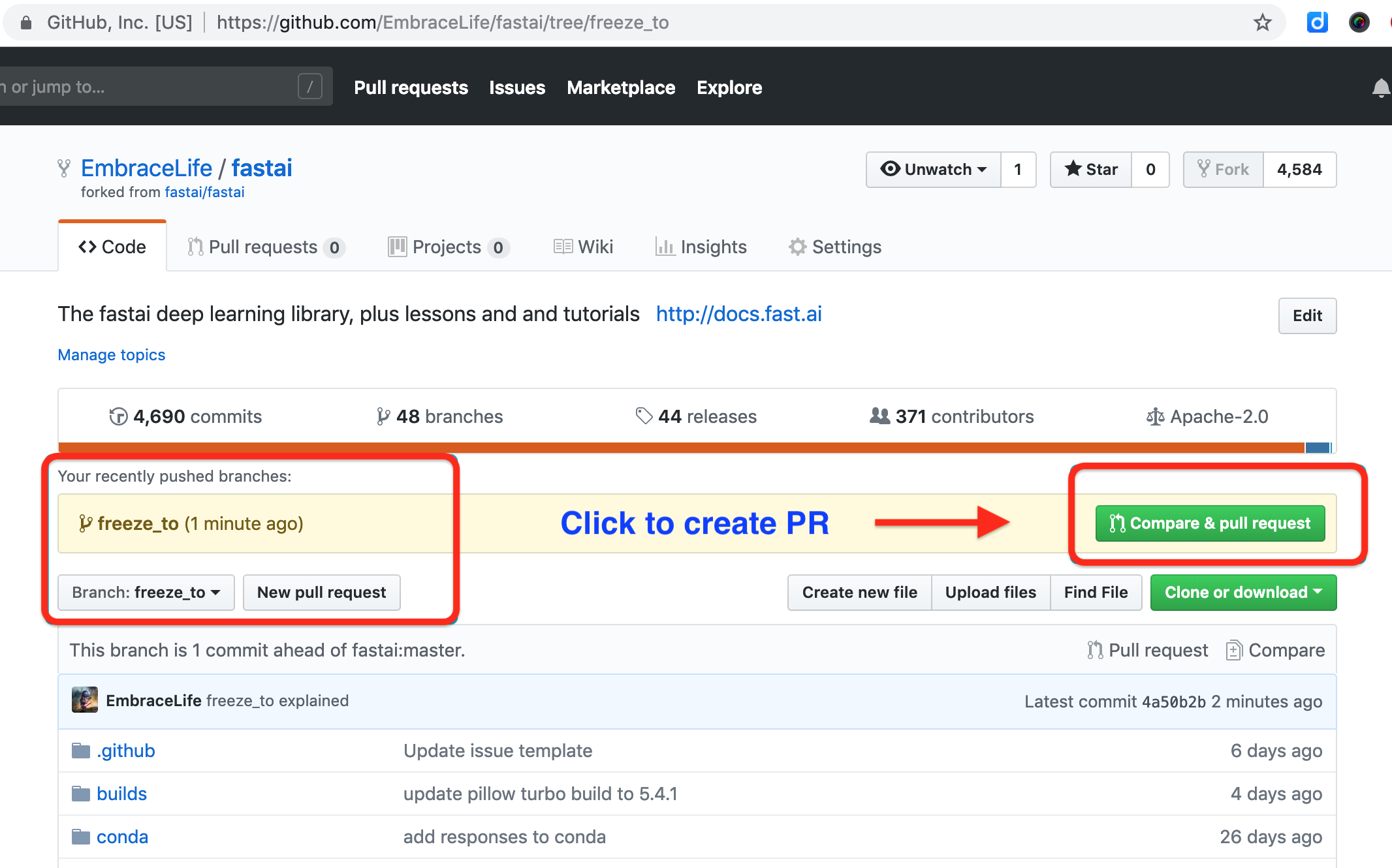
Step 7 Make a PR
Step 7 Make a PR
On your fork in github, you can see your push and click the blue box on the right to make a PR.
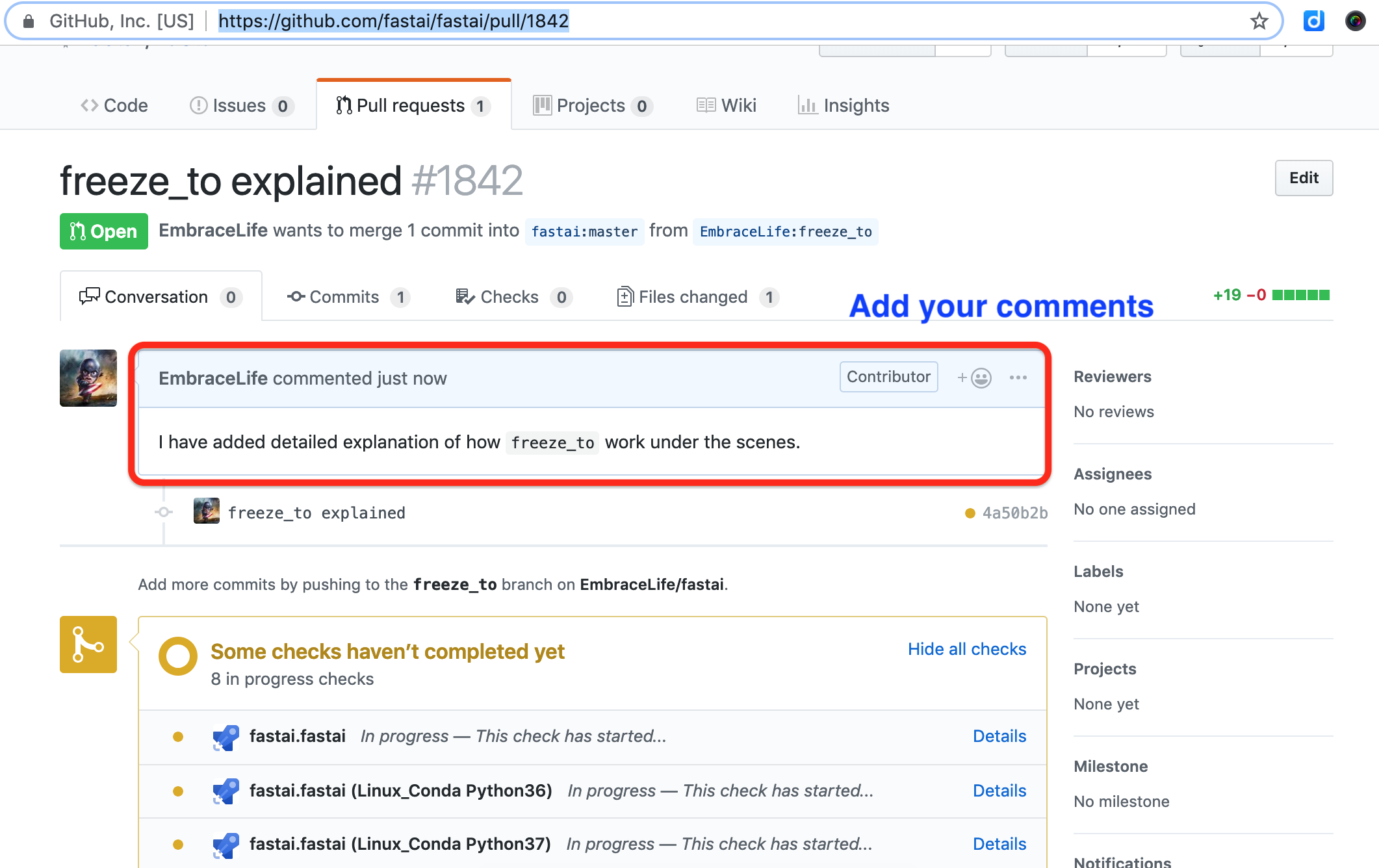
You can also add some notes to your PR.
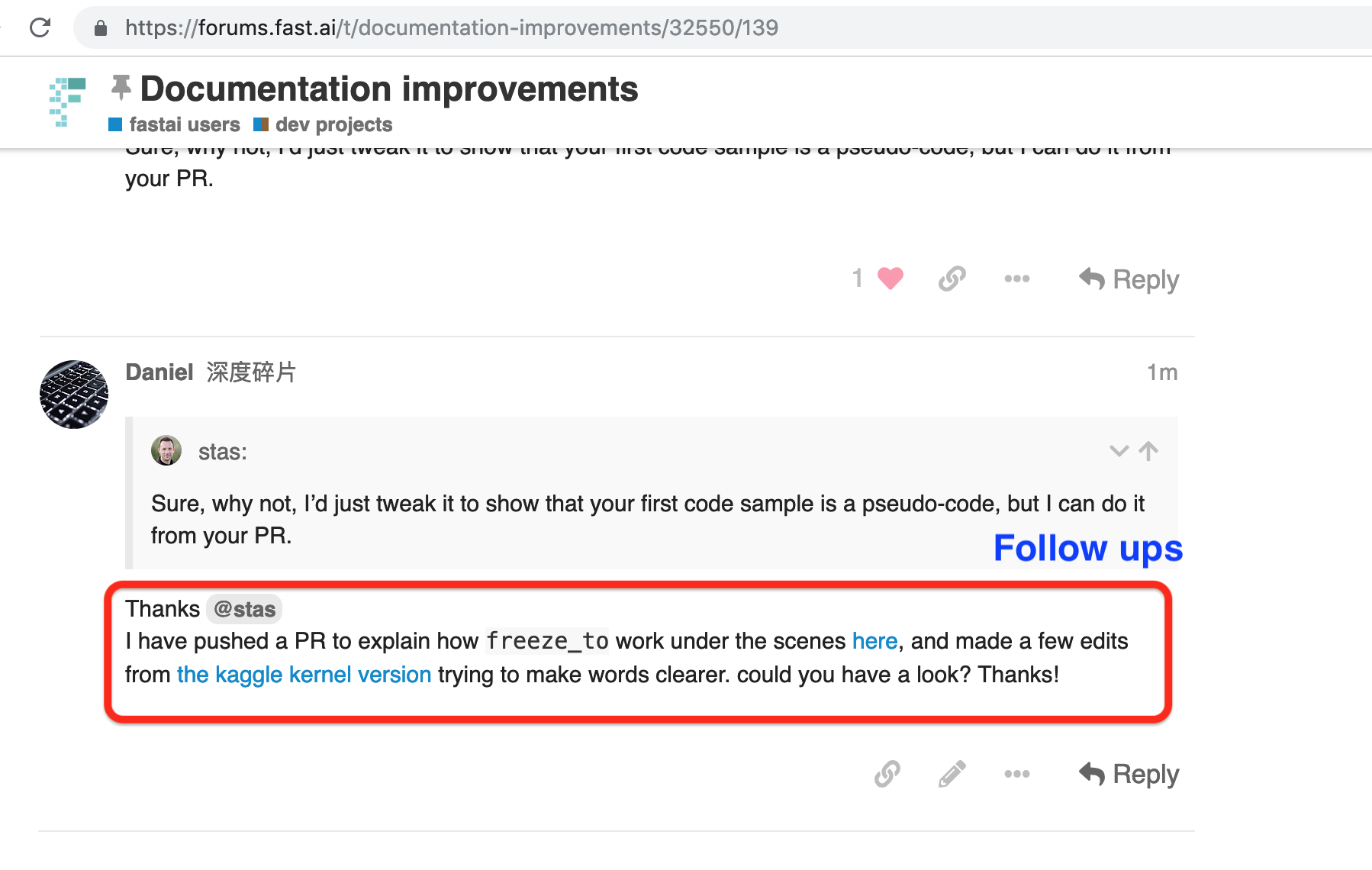
1 Like
freeze_to的工作原理
freeze_to的工作原理
The freeze_to source code can be understood as the following pseudo-code:
def freeze_to(self, n:int)->None:
for g in self.layer_groups[:n]: freeze
for g in self.layer_groups[n:]: unfreeze
In other words, for example, freeze_to(1) is to freeze layer group 0 and unfreeze the rest layer groups, and freeze_to(3) is to freeze layer groups 0, 1, and 2 but unfreeze the rest layer groups (if there are more layer groups left).
Both freeze and unfreeze sources are defined using freeze_to:
- When we say
freeze, we mean that in the specified layer groups therequires_gradof all layers with weights (except BatchNorm layers) are setFalse, so the layer weights won’t be updated during training. - when we say
unfreeze, we mean that in the specified layer groups therequires_gradof all layers with weights (except BatchNorm layers) are setTrue, so the layer weights will be updated during training.
You can experiment freeze_to, freeze and unfreeze with the following experiment.
所需library
所需library
import fastai.vision as fv
fv.__version__
'1.0.48'
数据地址
数据地址
path_test = fv.Path('/kaggle/input/test');
path_train = fv.Path('/kaggle/input/train'); path_train.ls()
[PosixPath('/kaggle/input/train/Fat Hen'),
PosixPath('/kaggle/input/train/Black-grass'),
PosixPath('/kaggle/input/train/Cleavers'),
PosixPath('/kaggle/input/train/Small-flowered Cranesbill'),
PosixPath('/kaggle/input/train/Sugar beet'),
PosixPath('/kaggle/input/train/Common Chickweed'),
PosixPath('/kaggle/input/train/Maize'),
PosixPath('/kaggle/input/train/Loose Silky-bent'),
PosixPath('/kaggle/input/train/Common wheat'),
PosixPath('/kaggle/input/train/Scentless Mayweed'),
PosixPath('/kaggle/input/train/Shepherds Purse'),
PosixPath('/kaggle/input/train/Charlock')]
创建DataBunch
创建DataBunch
fv.np.random.seed(1)
### 创建DataBunch
data = fv.ImageDataBunch.from_folder(path_train,
test=path_test,
ds_tfms=fv.get_transforms(),
valid_pct=0.25,
size=128,
bs=32,
num_workers=0)
data.normalize(fv.imagenet_stats)
data
ImageDataBunch;
Train: LabelList (3563 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Fat Hen,Fat Hen,Fat Hen,Fat Hen,Fat Hen
Path: /kaggle/input/train;
Valid: LabelList (1187 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: CategoryList
Sugar beet,Loose Silky-bent,Loose Silky-bent,Sugar beet,Charlock
Path: /kaggle/input/train;
Test: LabelList (794 items)
x: ImageList
Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128),Image (3, 128, 128)
y: EmptyLabelList
,,,,
Path: /kaggle/input/train
构建模型
构建模型
learn = fv.cnn_learner(data,
fv.models.resnet18,
metrics=fv.error_rate,
model_dir="/kaggle/working/")
Downloading: "https://download.pytorch.org/models/resnet18-5c106cde.pth" to /tmp/.torch/models/resnet18-5c106cde.pth
100%|██████████| 46827520/46827520 [00:00<00:00, 57425711.60it/s]
learn.save('start')
!ls .
__notebook__.ipynb __output__.json start.pth
freeze_to 源代码
freeze_to 源代码
learn.freeze_to??
Signature: learn.freeze_to(n:int) -> None
Source:
def freeze_to(self, n:int)->None:
"Freeze layers up to layer group `n`."
for g in self.layer_groups[:n]:
for l in g:
if not self.train_bn or not isinstance(l, bn_types): requires_grad(l, False)
for g in self.layer_groups[n:]: requires_grad(g, True)
self.create_opt(defaults.lr)
File: /opt/conda/lib/python3.6/site-packages/fastai/basic_train.py
Type: method
探查Resnet18 的layer groups和BN与其他含参数层的数量
探查Resnet18 的layer groups和BN与其他含参数层的数量
print('there are ', len(learn.layer_groups), 'layer_groups in this leaner object')
there are 3 layer_groups in this leaner object
for g in learn.layer_groups[:]: # 打开所有layer groups
print(len(g), 'layers')
# 找出所有含weights的layers
num_trainables = fv.np.array([hasattr(l, 'weight') for l in g]).sum()
print(num_trainables, 'layers with weights')
# 找出所有BN layers
num_bn = fv.np.array([isinstance(l, fv.bn_types) for l in g]).sum()
print(num_bn, "BN layers Not be frozen")
print(num_trainables - num_bn, 'layers which can be frozen')
print('')
print(g)
26 layers
20 layers with weights
10 BN layers Not be frozen
10 layers which can be frozen
Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(5): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace)
(7): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(8): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace)
(12): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(15): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace)
(17): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(18): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(20): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(21): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(22): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(23): ReLU(inplace)
(24): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(25): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
24 layers
20 layers with weights
10 BN layers Not be frozen
10 layers which can be frozen
Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(8): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(11): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(13): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): ReLU(inplace)
(15): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(17): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(18): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(20): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(21): ReLU(inplace)
(22): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(23): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
10 layers
4 layers with weights
2 BN layers Not be frozen
2 layers which can be frozen
Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): AdaptiveMaxPool2d(output_size=1)
(2): Flatten()
(3): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): Dropout(p=0.25)
(5): Linear(in_features=1024, out_features=512, bias=True)
(6): ReLU(inplace)
(7): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): Dropout(p=0.5)
(9): Linear(in_features=512, out_features=12, bias=True)
)
learn.summary()
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [1, 64, 64, 64] 9,408 False
______________________________________________________________________
BatchNorm2d [1, 64, 64, 64] 128 True
______________________________________________________________________
ReLU [1, 64, 64, 64] 0 False
______________________________________________________________________
MaxPool2d [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 73,728 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 8,192 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 294,912 False
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 False
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 32,768 False
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 False
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 False
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 1,179,648 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 131,072 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
AdaptiveAvgPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
AdaptiveMaxPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
Flatten [1, 1024] 0 False
______________________________________________________________________
BatchNorm1d [1, 1024] 2,048 True
______________________________________________________________________
Dropout [1, 1024] 0 False
______________________________________________________________________
Linear [1, 512] 524,800 True
______________________________________________________________________
ReLU [1, 512] 0 False
______________________________________________________________________
BatchNorm1d [1, 512] 1,024 True
______________________________________________________________________
Dropout [1, 512] 0 False
______________________________________________________________________
Linear [1, 12] 6,156 True
______________________________________________________________________
Total params: 11,710,540
Total trainable params: 543,628
Total non-trainable params: 11,166,912
查看某一个layer
查看某一个layer
l = learn.layer_groups[0][0]; l
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
learn.train_bn
True
BN classes
BN classes
print(fv.bn_types)
isinstance(l, fv.bn_types)
(<class 'torch.nn.modules.batchnorm.BatchNorm1d'>, <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, <class 'torch.nn.modules.batchnorm.BatchNorm3d'>)
False
requires_grad如何使用
requires_grad如何使用
fv.requires_grad?
Signature: fv.requires_grad(m:torch.nn.modules.module.Module, b:Union[bool, NoneType]=None) -> Union[bool, NoneType]
Docstring: If `b` is not set return `requires_grad` of first param, else set `requires_grad` on all params as `b`
File: /opt/conda/lib/python3.6/site-packages/fastai/torch_core.py
Type: function
fv.requires_grad(l, False)
freeze_to(0) == unfreeze()
freeze_to(0) == unfreeze()
learn.freeze_to(0) # freeze layer group before group 0
learn.summary()
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [1, 64, 64, 64] 9,408 True
______________________________________________________________________
BatchNorm2d [1, 64, 64, 64] 128 True
______________________________________________________________________
ReLU [1, 64, 64, 64] 0 False
______________________________________________________________________
MaxPool2d [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 True
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 True
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 True
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 True
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 73,728 True
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 True
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 8,192 True
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 True
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 True
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 294,912 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 32,768 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 1,179,648 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 131,072 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
AdaptiveAvgPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
AdaptiveMaxPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
Flatten [1, 1024] 0 False
______________________________________________________________________
BatchNorm1d [1, 1024] 2,048 True
______________________________________________________________________
Dropout [1, 1024] 0 False
______________________________________________________________________
Linear [1, 512] 524,800 True
______________________________________________________________________
ReLU [1, 512] 0 False
______________________________________________________________________
BatchNorm1d [1, 512] 1,024 True
______________________________________________________________________
Dropout [1, 512] 0 False
______________________________________________________________________
Linear [1, 12] 6,156 True
______________________________________________________________________
Total params: 11,710,540
Total trainable params: 11,710,540
Total non-trainable params: 0
learn.freeze_to(1) # freeze layer group before group 1
learn.summary()
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [1, 64, 64, 64] 9,408 False
______________________________________________________________________
BatchNorm2d [1, 64, 64, 64] 128 True
______________________________________________________________________
ReLU [1, 64, 64, 64] 0 False
______________________________________________________________________
MaxPool2d [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
ReLU [1, 64, 32, 32] 0 False
______________________________________________________________________
Conv2d [1, 64, 32, 32] 36,864 False
______________________________________________________________________
BatchNorm2d [1, 64, 32, 32] 128 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 73,728 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 8,192 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
ReLU [1, 128, 16, 16] 0 False
______________________________________________________________________
Conv2d [1, 128, 16, 16] 147,456 False
______________________________________________________________________
BatchNorm2d [1, 128, 16, 16] 256 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 294,912 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 32,768 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
ReLU [1, 256, 8, 8] 0 False
______________________________________________________________________
Conv2d [1, 256, 8, 8] 589,824 True
______________________________________________________________________
BatchNorm2d [1, 256, 8, 8] 512 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 1,179,648 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 131,072 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
ReLU [1, 512, 4, 4] 0 False
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 True
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
AdaptiveAvgPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
AdaptiveMaxPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
Flatten [1, 1024] 0 False
______________________________________________________________________
BatchNorm1d [1, 1024] 2,048 True
______________________________________________________________________
Dropout [1, 1024] 0 False
______________________________________________________________________
Linear [1, 512] 524,800 True
______________________________________________________________________
ReLU [1, 512] 0 False
______________________________________________________________________
BatchNorm1d [1, 512] 1,024 True
______________________________________________________________________
Dropout [1, 512] 0 False
______________________________________________________________________
Linear [1, 12] 6,156 True
______________________________________________________________________
Total params: 11,710,540
Total trainable params: 11,029,388
Total non-trainable params: 681,152
freeze的源代码
freeze的源代码
learn.freeze??
Signature: learn.freeze() -> None
Source:
def freeze(self)->None:
"Freeze up to last layer group."
assert(len(self.layer_groups)>1)
self.freeze_to(-1)
self.create_opt(defaults.lr) # also create an optimizer for learner
File: /opt/conda/lib/python3.6/site-packages/fastai/basic_train.py
Type: method
len(learn.layer_groups)
3
assert的用法
assert的用法
assert(len([1,2])>1)
# assert(len([2])>1)
unfreeze的源代码
unfreeze的源代码
learn.create_opt?
learn.unfreeze??
Signature: learn.unfreeze()
Source:
def unfreeze(self):
"Unfreeze entire model."
self.freeze_to(0)
self.create_opt(defaults.lr) # then create an optimizer for learner
File: /opt/conda/lib/python3.6/site-packages/fastai/basic_train.py
Type: method
Lesson 6: pets revisited
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.vision import *
一个Cell打印多项内容
一个Cell打印多项内容
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
批量设置, 过大会超出Kaggle GPU Disk 容量
批量设置, 过大会超出Kaggle GPU Disk 容量
bs = 8
提供数据,模型,图片文件地址
提供数据,模型,图片文件地址
# path = untar_data(URLs.PETS)/'images' # 从云端下载数据集,图片全部在一个文件夹中
path = Path('/kaggle/input/'); path.ls()
path_data = path/'the-oxfordiiit-pet-dataset'/'images'/'images'; path_data.ls()[:5]
path_model12 = path/'v3lesson6models'; path_model12.ls()
path_model3 = path/'v3lesson6modelsmore'; path_model3.ls()
path_img = path/'catdogtogether'; path_img.ls()
[PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset'),
PosixPath('/kaggle/input/v3lesson6modelsmore'),
PosixPath('/kaggle/input/catdogtogether'),
PosixPath('/kaggle/input/v3lesson6models')]
[PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset/images/images/shiba_inu_123.jpg'),
PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset/images/images/wheaten_terrier_114.jpg'),
PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset/images/images/staffordshire_bull_terrier_111.jpg'),
PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset/images/images/english_cocker_spaniel_20.jpg'),
PosixPath('/kaggle/input/the-oxfordiiit-pet-dataset/images/images/yorkshire_terrier_170.jpg')]
[PosixPath('/kaggle/input/v3lesson6models/3_1e-2_0.8.pth'),
PosixPath('/kaggle/input/v3lesson6models/2_1e-6_1e-3_0.8.pth')]
[PosixPath('/kaggle/input/v3lesson6modelsmore/2_1e-6_1e-4.pth')]
[PosixPath('/kaggle/input/catdogtogether/catdogTogether.png')]
图片变形设计
图片变形设计
# 图片变形设计
tfms = get_transforms(max_rotate=20, # 以后逐一尝试
max_zoom=1.3,
max_lighting=0.4,
max_warp=0.4,
p_affine=1.,
p_lighting=1.)
将图片夹转化成ImageList
将图片夹转化成ImageList
# 将图片夹转化成ImageList
src = ImageList.from_folder(path_data).split_by_rand_pct(0.2, seed=2) # 无需单独做np.random.seed(2)
src
# src.train[0:2] # 查看训练集中图片
# src.valid[0] # 直接看图
# src.train.__class__ # fastai.vision.data.ImageList
# src.__class__ # fastai.data_block.ItemLists
ItemLists;
Train: ImageList (5912 items)
Image (3, 306, 221),Image (3, 375, 500),Image (3, 376, 500),Image (3, 500, 333),Image (3, 500, 429)
Path: /kaggle/input/the-oxfordiiit-pet-dataset/images/images;
Valid: ImageList (1477 items)
Image (3, 455, 500),Image (3, 334, 500),Image (3, 375, 500),Image (3, 201, 250),Image (3, 500, 334)
Path: /kaggle/input/the-oxfordiiit-pet-dataset/images/images;
Test: None
ImageList (2 items)
Image (3, 306, 221),Image (3, 375, 500)
Path: /kaggle/input/the-oxfordiiit-pet-dataset/images/images
%20Lesson%206_%20pets%E4%B8%AD%E6%96%87%E7%89%88/output_15_2.jpeg?raw=true)
fastai.vision.data.ImageList
fastai.data_block.ItemLists
refactor DataBunch
refactor DataBunch
# 快捷生成DataBunch
def get_data(size, bs, padding_mode='reflection'): # 提供图片尺寸,批量和 padding模式
return (src.label_from_re(r'([^/]+)_\d+.jpg$') # 从图片名称中提取label标注
.transform(tfms, size=size, padding_mode=padding_mode) # 对图片做变形
.databunch(bs=bs).normalize(imagenet_stats))
data = get_data(224, bs, 'zeros') # 图片统一成224的尺寸
# data.train_ds.__class__ # fastai.data_block.LabelList 所以可以像list一样提取数据
# data.train_ds[0]
# data.train_ds[0][0] # 提取图片,且已经变形,Image class
# data.train_ds[0][1] # 提取label, Category class
# data.train_ds[0][1].__class__
# data.train_ds[0][0].__class__
fastai.data_block.LabelList
(Image (3, 224, 224), Category shiba_inu)
%20Lesson%206_%20pets%E4%B8%AD%E6%96%87%E7%89%88/output_18_2.jpeg?raw=true)
Category shiba_inu
fastai.core.Category
fastai.vision.image.Image
对同一张图作画,随机出现不同的变形
对同一张图作画,随机出现不同的变形
def _plot(i,j,ax):
x,y = data.train_ds[3] # x 是图片, y是 label
x.show(ax, y=y) # ax 是plot_multi提供的某一个subplot的位置来画图
plot_multi(_plot, 3, 3, figsize=(8,8)) # (3,3) 3行3列, 整体上8高8宽

对比padding='zero' vs 'reflection'的区别
对比padding=‘zero’ vs 'reflection’的区别
data = get_data(224,bs) # padding mode = reflection 效果更加,无边框黑区
plot_multi(_plot, 3, 3, figsize=(8,8))

如何释放内存
如何释放内存
gc.collect() # 释放GPU内存,但是数据无从查看???
如何创建模型并给最后一层加BN
如何创建模型并给最后一层加BN
learn = cnn_learner(data,
models.resnet34,
metrics=error_rate,
bn_final=True, # bn_final=True, 最后一层加入BatchNorm
model_dir='/kaggle/working') # 确保模型可被写入,且方便下载
29353
Downloading: "https://download.pytorch.org/models/resnet34-333f7ec4.pth" to /tmp/.torch/models/resnet34-333f7ec4.pth
100%|██████████| 87306240/87306240 [00:02<00:00, 35064929.22it/s]
learn.summary()
展示何为final BN
展示何为final BN
learn.summary() # bn_final=True
# Total params: 21,831,599
# Total trainable params: 563,951
# Total non-trainable params: 21,267,648
learn = cnn_learner(data,
models.resnet34,
metrics=error_rate,
bn_final=False, # bn_final=True什么意思?
model_dir='/kaggle/working') # 确保模型可被写入,且方便下载
learn.summary() # bn_final=False, 少了不到100个参数weights, 因为没有下面最后一层BN
# Linear [1, 37] 18,981 True
# ______________________________________________________________________
# BatchNorm1d [1, 37] 74 True
# ______________________________________________________________________
slice(1e-2), max_lr=slice(1e-6,1e-3)的实际用途
slice(1e-2), max_lr=slice(1e-6,1e-3)的实际用途
learn.fit_one_cycle(3, slice(1e-2), pct_start=0.8)
# slice(1e-2), max_lr=slice(1e-6,1e-3)
# 具体什么用途见 https://docs.fast.ai/basic_train.html#Learner.lr_range
learn.model_dir = '/kaggle/working/'
learn.save('3_1e-2_0.8')
# Total time: 06:19
# epoch train_loss valid_loss error_rate time
# 0 2.406209 1.178268 0.188769 02:04
# 1 1.676663 0.509336 0.140054 02:06
# 2 1.438834 0.590069 0.139378 02:07
learn.load(path_model12/'3_1e-2_0.8')
pct_start的用意
pct_start的用意
learn.unfreeze()
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-3), pct_start=0.8)
# 理解pct_start用途见 https://github.com/fastai/fastai/blob/master/fastai/callbacks/one_cycle.py#L30
# 默认值=0.3,这里设置0.8, 作为annealing的分水岭
learn.save('2_1e-6_1e-3_0.8')
# Total time: 04:21
# epoch train_loss valid_loss error_rate time
# 0 1.283900 0.470629 0.104195 02:09
# 1 1.200091 0.379310 0.103518 02:11
learn.load(path_model12/'2_1e-6_1e-3_0.8')
**生成链接,下载模型到本地**
生成链接,下载模型到本地
from IPython.display import FileLinks
FileLinks('.')
fit_one_cycle 源码
fit_one_cycle 源码
def fit_one_cycle(learn:Learner,
cyc_len:int,
max_lr:Union[Floats,slice]=defaults.lr,
moms:Tuple[float,float]=(0.95,0.85),
div_factor:float=25.,
pct_start:float=0.3,
final_div:float=None,
wd:float=None,
callbacks:Optional[CallbackList]=None,
tot_epochs:int=None,
start_epoch:int=None)->None:
"Fit a model following the 1cycle policy."
max_lr = learn.lr_range(max_lr)
callbacks = listify(callbacks)
callbacks.append(OneCycleScheduler(learn,
max_lr,
moms=moms,
div_factor=div_factor,
pct_start=pct_start,
final_div=final_div,
tot_epochs=tot_epochs,
start_epoch=start_epoch))
learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
快捷调整数据特点
快捷调整数据特点
data = get_data(352,bs) # 放大图片尺寸
learn.data = data
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4)) # 缩小学习率,以及搜索范围, 但pct_start = 0.3默认值
# Total time: 06:53
# epoch train_loss valid_loss error_rate time
# 0 1.273031 0.375372 0.092693 03:27
# 1 1.203877 0.460149 0.088633 03:25
learn.model_dir = '/kaggle/working/'
learn.save('2_1e-6_1e-4')
from IPython.display import FileLinks
FileLinks('.') # 点击链接下载models
# ./
# 2_1e-6_1e-4.pth
# __notebook_source__.ipynb
# ./.ipynb_checkpoints/
# __notebook_source__-checkpoint.ipynb
data = get_data(352,16)
learn = cnn_learner(data,
models.resnet34,
metrics=error_rate,
bn_final=True,
model_dir='/kaggle/working/').load(path_model3/'2_1e-6_1e-4')
提取一个验证集中的数据样本并展示
提取一个验证集中的数据样本并展示
idx=150
x,y = data.valid_ds[idx] # 验证集图片保持不变(不论运行多少次)
y
y.data
data.valid_ds.y[idx] # 打印label
data.classes[25] # 说明25是leonberger的序号
x.show()
Category leonberger
25
Category leonberger
'leonberger'

创造一个3x3的matrix作为kernel
创造一个3x3的matrix作为kernel
k = tensor([
[0. ,-5/3,1],
[-5/3,-5/3,1],
[1. ,1 ,1],
]).expand(1,3,3,3)/6 # 然后在转化为一个4D,rank4 tensor,在缩小6倍
k
tensor([[[[ 0.0000, -0.2778, 0.1667],
[-0.2778, -0.2778, 0.1667],
[ 0.1667, 0.1667, 0.1667]],
[[ 0.0000, -0.2778, 0.1667],
[-0.2778, -0.2778, 0.1667],
[ 0.1667, 0.1667, 0.1667]],
[[ 0.0000, -0.2778, 0.1667],
[-0.2778, -0.2778, 0.1667],
[ 0.1667, 0.1667, 0.1667]]]])
k.shape # 查看尺寸
torch.Size([1, 3, 3, 3])
从图片中提取数据tensor
从图片中提取数据tensor
t = data.valid_ds[idx][0].data # 从图片中提取数据tensor
t.shape # 展示tensor尺寸
torch.Size([3, 352, 352])
将图片tensor转化为一个rank 4 tensor
将图片tensor转化为一个rank 4 tensor
t[None].shape
torch.Size([1, 3, 352, 352])
对图片tensor做filter处理,并展示图片
对图片tensor做filter处理,并展示图片
# F.conv2d??
edge = F.conv2d(t[None], k)
show_image(edge[0], figsize=(5,5)) # 展示被kernel处理过的图片的样子
<matplotlib.axes._subplots.AxesSubplot at 0x7f8f718fe240>

查看类别和模型结构
查看类别和模型结构
data.c # 可以理解成类别数量
37
learn.model # 查看模型结构
print(learn.summary()) # 查看layer tensor尺寸和训练参数数量
Heatmap
进入 evaluation 模式
进入 evaluation 模式
# learn.model.eval?
m = learn.model.eval();
one_item: 将上图的数据x变成一个batch
one_item: 将上图的数据x变成一个batch
xb,_ = data.one_item(x); xb.shape; # 获取一个图片tensor, 应该是变形过后的,
xb # xb tensor长什么样子
# Image(xb) # 是rank 4 tensor, dim 过多,无法作图
# data.denorm?
denorm: 给予新的mean, std
denorm: 给予新的mean, std
data.denorm(xb) # 给予一个新的mean, std转化xb,展示新tensor
data.denorm(xb)[0].shape # 4D 转化为 3D
Image: 将tensor转化为图片
Image: 将tensor转化为图片
xb_im = Image(data.denorm(xb)[0]); xb_im # denorm之后就能作图了
xb = xb.cuda(); xb # tensor 后面带上了cuda
torch.Size([1, 3, 352, 352])
tensor([[[[0.8961, 0.8951, 0.8790, ..., 0.3319, 0.3157, 0.3138],
[0.8655, 0.8798, 0.8790, ..., 0.3328, 0.3301, 0.3165],
[0.9095, 0.9247, 0.9248, ..., 0.3023, 0.3140, 0.3523],
...,
[1.1673, 1.1432, 1.1060, ..., 0.4234, 0.4285, 0.4219],
[1.1567, 1.0827, 1.0074, ..., 0.4222, 0.4070, 0.4433],
[1.0902, 1.1368, 1.1531, ..., 0.4014, 0.5059, 0.4622]],
[[1.1116, 1.0795, 1.0630, ..., 0.5738, 0.5573, 0.5845],
[1.0804, 1.0639, 1.0630, ..., 0.5748, 0.5720, 0.5597],
[1.1254, 1.1099, 1.1099, ..., 0.5436, 0.5555, 0.5947],
...,
[0.9607, 0.9342, 0.8925, ..., 0.2860, 0.2912, 0.2844],
[0.9957, 0.9016, 0.7907, ..., 0.3179, 0.3024, 0.3395],
[0.9424, 0.9560, 0.9231, ..., 0.3297, 0.4366, 0.3919]],
[[1.0694, 1.0530, 1.0365, ..., 0.6192, 0.6027, 0.6153],
[1.0383, 1.0374, 1.0365, ..., 0.6201, 0.6174, 0.6043],
[1.0831, 1.0831, 1.0831, ..., 0.5891, 0.6009, 0.6400],
...,
[0.8151, 0.7938, 0.7524, ..., 0.2805, 0.2855, 0.2820],
[0.8724, 0.8237, 0.7159, ..., 0.3149, 0.2976, 0.3620],
[0.8487, 0.8806, 0.8972, ..., 0.3413, 0.4477, 0.4033]]]],
device='cuda:0')
tensor([[[[0.6902, 0.6900, 0.6863, ..., 0.5610, 0.5573, 0.5569],
[0.6832, 0.6865, 0.6863, ..., 0.5612, 0.5606, 0.5575],
[0.6933, 0.6968, 0.6968, ..., 0.5542, 0.5569, 0.5657],
...,
[0.7523, 0.7468, 0.7383, ..., 0.5820, 0.5831, 0.5816],
[0.7499, 0.7329, 0.7157, ..., 0.5817, 0.5782, 0.5865],
[0.7346, 0.7453, 0.7490, ..., 0.5769, 0.6009, 0.5908]],
[[0.7050, 0.6978, 0.6941, ..., 0.5845, 0.5808, 0.5869],
[0.6980, 0.6943, 0.6941, ..., 0.5847, 0.5841, 0.5814],
[0.7081, 0.7046, 0.7046, ..., 0.5778, 0.5804, 0.5892],
...,
[0.6712, 0.6653, 0.6559, ..., 0.5201, 0.5212, 0.5197],
[0.6790, 0.6580, 0.6331, ..., 0.5272, 0.5237, 0.5320],
[0.6671, 0.6701, 0.6628, ..., 0.5299, 0.5538, 0.5438]],
[[0.6466, 0.6429, 0.6392, ..., 0.5453, 0.5416, 0.5444],
[0.6396, 0.6394, 0.6392, ..., 0.5455, 0.5449, 0.5420],
[0.6497, 0.6497, 0.6497, ..., 0.5385, 0.5412, 0.5500],
...,
[0.5894, 0.5846, 0.5753, ..., 0.4691, 0.4702, 0.4694],
[0.6023, 0.5913, 0.5671, ..., 0.4769, 0.4730, 0.4875],
[0.5970, 0.6041, 0.6079, ..., 0.4828, 0.5067, 0.4967]]]])
torch.Size([3, 352, 352])
%20Lesson%206_%20pets%E4%B8%AD%E6%96%87%E7%89%88/output_71_4.jpeg?raw=true)
tensor([[[[0.8961, 0.8951, 0.8790, ..., 0.3319, 0.3157, 0.3138],
[0.8655, 0.8798, 0.8790, ..., 0.3328, 0.3301, 0.3165],
[0.9095, 0.9247, 0.9248, ..., 0.3023, 0.3140, 0.3523],
...,
[1.1673, 1.1432, 1.1060, ..., 0.4234, 0.4285, 0.4219],
[1.1567, 1.0827, 1.0074, ..., 0.4222, 0.4070, 0.4433],
[1.0902, 1.1368, 1.1531, ..., 0.4014, 0.5059, 0.4622]],
[[1.1116, 1.0795, 1.0630, ..., 0.5738, 0.5573, 0.5845],
[1.0804, 1.0639, 1.0630, ..., 0.5748, 0.5720, 0.5597],
[1.1254, 1.1099, 1.1099, ..., 0.5436, 0.5555, 0.5947],
...,
[0.9607, 0.9342, 0.8925, ..., 0.2860, 0.2912, 0.2844],
[0.9957, 0.9016, 0.7907, ..., 0.3179, 0.3024, 0.3395],
[0.9424, 0.9560, 0.9231, ..., 0.3297, 0.4366, 0.3919]],
[[1.0694, 1.0530, 1.0365, ..., 0.6192, 0.6027, 0.6153],
[1.0383, 1.0374, 1.0365, ..., 0.6201, 0.6174, 0.6043],
[1.0831, 1.0831, 1.0831, ..., 0.5891, 0.6009, 0.6400],
...,
[0.8151, 0.7938, 0.7524, ..., 0.2805, 0.2855, 0.2820],
[0.8724, 0.8237, 0.7159, ..., 0.3149, 0.2976, 0.3620],
[0.8487, 0.8806, 0.8972, ..., 0.3413, 0.4477, 0.4033]]]],
device='cuda:0')
调用hooks
调用hooks
from fastai.callbacks.hooks import * # import hooks functions
refactor来调用activation值和对应的grads
refactor来调用activation值和对应的grads
def hooked_backward(cat=y): # y = leonberger label
with hook_output(m[0]) as hook_a:
with hook_output(m[0], grad=True) as hook_g:
preds = m(xb) # xb = leonberger tensor
print(preds.shape)
print(int(cat))
print(preds[0, int(cat)])
print(preds)
preds[0,int(cat)].backward() # 返回 leonberger对应的grad给到hook_g
return hook_a,hook_g
用y来选择某一个类别宠物的grads
用y来选择某一个类别宠物的grads
y
int(y) # 获取类别对应的序号
hook_a,hook_g = hooked_backward()
Category leonberger
25
torch.Size([1, 37])
25
tensor(4.0113, device='cuda:0', grad_fn=<SelectBackward>)
tensor([[-1.7866, -1.7982, -1.7469, -2.7751, -2.0945, -2.2714, -1.8462, -2.7926,
-1.8879, -1.4872, -1.3824, -1.9029, -2.7254, -2.2443, -2.2777, -2.5630,
-1.6129, -2.0326, -2.1197, -1.7727, -2.7254, -0.8984, -2.0933, -2.4925,
-0.9572, 4.0113, -1.7384, -0.6208, -1.2898, -2.0548, -0.7799, -2.2127,
-2.8315, -2.2126, -2.0787, -1.4111, -1.6095]], device='cuda:0',
grad_fn=<CudnnBatchNormBackward>)
提取activation值,调整shape
提取activation值,调整shape
# hook_a -> <fastai.callbacks.hooks.Hook at 0x7f8b78205278>
# hook_g -> <fastai.callbacks.hooks.Hook at 0x7f8b78205208>
# hook_a.stored.shape # 4D tensor, torch.Size([1, 512, 11, 11])
# hook_a.stored[0].shape # from 4D to 3D
acts = hook_a.stored[0].cpu() # 从gpu模式到cpu模式
acts.shape
torch.Size([512, 11, 11])
压缩activation到2D, 11x11
压缩activation到2D, 11x11
avg_acts = acts.mean(0) # 压缩512个值,来获取他们的均值
avg_acts.shape
torch.Size([11, 11])
show_heatmap 制作热力图对比
show_heatmap 制作热力图对比
def show_heatmap(hm): # 用activation的压缩tensor来做热力图
_,ax = plt.subplots(1,3)
xb_im.show(ax[0]) # 画出原图
ax[1].imshow(hm, alpha=0.6, extent=(0,352,352,0),
interpolation='bilinear', cmap='magma');
xb_im.show(ax[2]) # 两图合并
ax[2].imshow(hm, alpha=0.6, extent=(0,352,352,0),
interpolation='bilinear', cmap='magma');
show_heatmap(avg_acts)

Grad-CAM
调用grads并压缩成1D tensor
Paper: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
调用grads并压缩成1D tensor
# hook_g.stored.__class__ # is a list
# len(hook_g.stored) # just 1
# hook_g.stored[0].__class__ # is a tensor
# hook_g.stored[0].shape # 4D tensor
# hook_g.stored[0][0].shape # 3D tensor
grad = hook_g.stored[0][0].cpu()
# grad.mean(1).shape # 对中间的11取均值
# grad.mean(1).mean(1).shape # 对中间的两个11取均值
grad_chan = grad.mean(1).mean(1)
grad.shape,grad_chan.shape
(torch.Size([512, 11, 11]), torch.Size([512]))
activations 与 grads 共同生成一个kernel
activations 与 grads 共同生成一个kernel
# grad_chan[...,None,None].shape # 将压缩后的grad从1D变3D
mult = (acts*grad_chan[...,None,None]).mean(0) # activation 与 grad 的相乘,再取一个维度的均值,变成一个kernel
# 最后一层的activation * 最后一层压缩的grad 再求和,并压缩512层取均值
mult.shape
torch.Size([11, 11])
show_heatmap(mult)

采用一张新图片
采用一张新图片
# fn = get_image_files(path_img); fn
path_img/'catdogTogether.png'
PosixPath('/kaggle/input/catdogtogether/catdogTogether.png')
# x = open_image(fn[0]); x
x = open_image(path_img/'catdogTogether.png'); x
%20Lesson%206_%20pets%E4%B8%AD%E6%96%87%E7%89%88/output_94_0.jpeg?raw=true)
data.one_item将上图用data设置来处理
data.one_item将上图用data设置来处理
xb,_ = data.one_item(x)
xb_im = Image(data.denorm(xb)[0]) # 生成图片
xb = xb.cuda()
xb_im
%20Lesson%206_%20pets%E4%B8%AD%E6%96%87%E7%89%88/output_96_0.jpeg?raw=true)
提取activations and grads, 用上图但y依旧是序号为25的leonberger
提取activations and grads, 用上图但y依旧是序号为25的leonberger
hook_a,hook_g = hooked_backward() # y依旧是序号为25的leonberger
torch.Size([1, 37])
25
tensor(-1.1971, device='cuda:0', grad_fn=<SelectBackward>)
tensor([[-0.8193, -1.4613, -0.6137, 0.1928, 0.4691, -0.9221, 0.1603, -0.7036,
-0.1686, -0.7140, -0.9200, -1.8551, -1.0651, -0.0114, -0.5084, 0.5980,
-0.9214, -0.8087, -0.8323, -1.9692, -1.4863, 0.0782, -0.2809, -1.0330,
-1.8064, -1.1971, -1.6896, -1.1700, -0.0138, -0.3851, -0.9035, -1.2556,
-1.5972, -0.6435, -0.7848, -1.0125, -1.2785]], device='cuda:0',
grad_fn=<CudnnBatchNormBackward>)
按上述方式生成kernel
按上述方式生成kernel
acts = hook_a.stored[0].cpu() # 本图片 最后一层activation
grad = hook_g.stored[0][0].cpu() # 本图片 最后一层 grad, 并且是基于leonberger类别去提取的grad!!!!!!!!
grad_chan = grad.mean(1).mean(1) # 对 11x11 取均值, 512 长的vector
mult = (acts*grad_chan[...,None,None]).mean(0); mult.shape # 生成11x11 tensor
torch.Size([11, 11])
热力图识别出:y依旧是序号为25的leonberger
热力图识别出:y依旧是序号为25的leonberger
show_heatmap(mult)

将y改换成另一个猫类别,重复上述操作,热力图识别猫而不再是狗
将y改换成另一个猫类别,重复上述操作,热力图识别猫而不再是狗
data.classes[0]
'Abyssinian'
hook_a,hook_g = hooked_backward(0)
torch.Size([1, 37])
0
tensor(-0.8193, device='cuda:0', grad_fn=<SelectBackward>)
tensor([[-0.8193, -1.4613, -0.6137, 0.1928, 0.4691, -0.9221, 0.1603, -0.7036,
-0.1686, -0.7140, -0.9200, -1.8551, -1.0651, -0.0114, -0.5084, 0.5980,
-0.9214, -0.8087, -0.8323, -1.9692, -1.4863, 0.0782, -0.2809, -1.0330,
-1.8064, -1.1971, -1.6896, -1.1700, -0.0138, -0.3851, -0.9035, -1.2556,
-1.5972, -0.6435, -0.7848, -1.0125, -1.2785]], device='cuda:0',
grad_fn=<CudnnBatchNormBackward>)
acts = hook_a.stored[0].cpu()
grad = hook_g.stored[0][0].cpu()
grad_chan = grad.mean(1).mean(1)
mult = (acts*grad_chan[...,None,None]).mean(0)
show_heatmap(mult)

文档框架梳理
modules如何相互依赖和搭建整个系统
library 内各个modules之间的依赖关系 官方文档
library结构图
由多个submodule组合而成
-
transform
-
data (DataBunch)
-
models
-
learn (optionally, such as Learner)

fastai调用哪些基础依赖库的具体内容
fastai/imports/core
fastai从torch中调用了哪些内容
fastai/imports/torch
fastai.core的目的功能
fastai.core 从 fastai.imports.core 中调用工具建设关键功能性函数来 format and split data
fastai.torch_core的目的功能
为fastai定制的处理tensor的功能函数集
调用了 imports.torch, core, collections.OrderedDict, torch.nn.parallel.DistributedDataParallel
basic_data的目的和功能
"`fastai.data` loads and manages datasets with `DataBunch`"
from .torch_core import *
from torch.utils.data.dataloader import default_collate
DatasetType = Enum('DatasetType', 'Train Valid Test Single Fix')
__all__ = ['DataBunch', 'DeviceDataLoader', 'DatasetType', 'load_data']
data_block的目的和功能
from .torch_core import *
from .basic_data import *
from .layers import *
from numbers import Integral
__all__ = ['ItemList', 'CategoryList', 'MultiCategoryList', 'MultiCategoryProcessor' ,
'LabelList', 'ItemLists', 'get_files', 'PreProcessor', 'LabelLists', 'FloatList',
'CategoryProcessor', 'EmptyLabelList', 'MixedItem', 'MixedProcessor','MixedItemList']
layers的目的和功能
"`fastai.layers` provides essential functions to building and modifying `model` architectures"
from .torch_core import *
__all__ = ['AdaptiveConcatPool2d', 'BCEWithLogitsFlat', 'BCEFlat', 'MSELossFlat', 'CrossEntropyFlat', 'Debugger',
'Flatten', 'Lambda', 'PoolFlatten', 'View', 'ResizeBatch', 'bn_drop_lin', 'conv2d', 'conv2d_trans', 'conv_layer',
'embedding', 'simple_cnn', 'NormType', 'relu', 'batchnorm_2d', 'trunc_normal_', 'PixelShuffle_ICNR', 'icnr',
'NoopLoss', 'WassersteinLoss', 'SelfAttention', 'SequentialEx', 'MergeLayer', 'res_block', 'sigmoid_range',
'SigmoidRange', 'PartialLayer', 'FlattenedLoss', 'BatchNorm1dFlat', 'LabelSmoothingCrossEntropy']
metrics的目的功能
"Implements various metrics to measure training accuracy"
from .torch_core import *
from .callback import *
from .layers import *
__all__ = ['error_rate', 'accuracy', 'accuracy_thresh', 'dice', 'exp_rmspe', 'fbeta','FBeta', 'mse', 'mean_squared_error',
'mae', 'mean_absolute_error', 'rmse', 'root_mean_squared_error', 'msle', 'mean_squared_logarithmic_error',
'explained_variance', 'r2_score', 'top_k_accuracy', 'KappaScore', 'ConfusionMatrix', 'MatthewsCorreff',
'Precision', 'Recall', 'R2Score', 'ExplainedVariance', 'ExpRMSPE', 'RMSE', 'Perplexity']
callback的功能目的
"Callbacks provides extensibility to the `basic_train` loop. See `train` for examples of custom callbacks."
from .basic_data import *
from .torch_core import *
import torch.distributed as dist
__all__ = ['AverageMetric', 'Callback', 'CallbackHandler', 'OptimWrapper', 'SmoothenValue', 'Scheduler', 'annealing_cos', 'CallbackList', 'annealing_exp', 'annealing_linear', 'annealing_no', 'annealing_poly']
basic_train的功能目的
"Provides basic training and validation with `Learner`"
from .torch_core import *
from .basic_data import *
from .callback import *
from .data_block import *
from .utils.ipython import gpu_mem_restore
import inspect
from fastprogress.fastprogress import format_time, IN_NOTEBOOK
from time import time
from fastai.sixel import plot_sixel
__all__ = ['Learner', 'LearnerCallback', 'Recorder', 'RecordOnCPU', 'fit', 'loss_batch', 'train_epoch', 'validate', 'get_preds', 'load_learner']
callbacks功能目的
callbacks是文件夹,下面有很多submodules.
It (depends on basic_train) is a submodule defining various callbacks, such as for mixed precision training or 1cycle annealing;
__pycache__/
tracker.py*
__init__.py
csv_logger.py
fp16.py
general_sched.py
hooks.py
loss_metrics.py
lr_finder.py
mem.py
misc.py
mixup.py
mlflow.py
one_cycle.py
rnn.py
tensorboard.py
~
vision.data的目的功能
"""
Manages data input pipeline - folderstransformbatch input.
Includes support for classification, segmentation and bounding boxes
"""
from ..torch_core import *
from .image import *
from .transform import *
from ..data_block import *
from ..basic_data import *
from ..layers import *
from .learner import *
from torchvision import transforms as tvt
__all__ = ['get_image_files', 'denormalize', 'get_annotations', 'ImageDataBunch', 'ImageList', 'normalize', 'normalize_funcs', 'resize_to','channel_view', 'mnist_stats', 'cifar_stats', 'imagenet_stats', 'download_images',
'verify_images', 'bb_pad_collate', 'ImageImageList', 'PointsLabelList', 'ObjectCategoryList', 'ObjectItemList', 'SegmentationLabelList','SegmentationItemList', 'PointsItemList']
text.data的功能目的
"NLP data loading pipeline. Supports csv, folders, and preprocessed data."
from ..torch_core import *
from .transform import *
from ..basic_data import *
from ..data_block import *
from ..layers import *
from ..callback import Callback
__all__ = ['LanguageModelPreLoader', 'SortSampler', 'SortishSampler', 'Text List', 'pad_collate', 'TextDataBunch',
-- 'TextLMDataBunch', 'TextClasDataBunch', 'Text', 'open_text', 'To-- kenizeProcessor', 'NumericalizeProcessor',
|| 'OpenFileProcessor', 'LMLabelList']
tabular.data功能目的
"Data loading pipeline for structured data support. Loads from pandas DataFrame"
from ..torch_core import *
from .transform import *
from ..basic_data import *
from ..data_block import *
from ..basic_train import *
from .models import *
from pandas.api.types import is_numeric_dtype, is_categorical_dtype
__all__ = ['TabularDataBunch', 'TabularLine', 'TabularList',
'TabularProces sor', 'tabular_learner']
共建文档
如果你想尝试学习阅读和改进文档,可以看看下面三个贡献的经验总结视频。论坛里大家都很热情,认真提问,努力尝试,肯定会有收获的!
初学者可视化PR指南 论坛版, github版本, 视频解读
如何对源码内文档做更新 讨论
freeze文档解读 学习探讨, Notebook, 成果, 视频解读
freeze_to文档解读 学习探讨, Kaggle kernel, 听写, 成果, 视频解读
layer groups的由来 学习探讨
max_lr的设计和使用 学习探讨
fit_one_cycle的最优实践 学习探讨
cnn_learner是如何使用pretrained models 源码解说
from fastai import * 真有必要吗 探讨, kaggle kernel
data 的链接错误?探讨 已更新
learn 对应的modules? 探讨 已更新
ImageList的items.create_func set to open_image 开始探讨
improve on untar_data docs 探讨, PR
improve docs of ImageList 探讨 PR
improve on docs of get_files and _get_files 探讨, PR
1 Like
课程笔记汉化项目
欢迎大家共同来建设课程笔记汉化项目!
fast.ai v3 2019课程笔记源泉
项目分解
步骤1. 汉化知识点标题,构建链接
@hiromi 步骤1进行中
@PoonamV 步骤1进行中
@Daniel 步骤1已完成
第一课 你的宠物
第二课 你的图片数据集
第三课 多标注和像素隔离问题
第四课 自然语言问题,表格数据,Recsys
第五课 反向传递与手写神经网络
第六课 深入学习CNN与数据科学伦理
第七课 Resnet, U-net, GAN
步骤2. 汉化每个知识点内容
Hi @jeremy
I finally decided to translate video lessons into Chinese. I started with Lesson 3 and found the following translating style comfortable and easier:
- not word for word translation, not even phrase by phrase translation
- it is more like sentence by sentence translation or more precisely meaning to meaning translation (beyond strict translation per sentence)
I am not sure whether such style is acceptable for Youtube review or do you have a strict standard for accepting translation for fastai video lessons?
Another question is after I submit the finished lesson 3 translation for review, do you have any control of the review? or it is totally up to Youtube?
Thanks!
Great! That sounds fine - but I think try to get at least sentence-to-sentence where possible because a lot of listeners use the captions to help them understand the English. If it’s too different, it could be a little confusing!
It’s totally up to me - I don’t think Youtube are involved. It’s worth letting me know when it’s there.
1 Like
Thanks! I got it!
I will make sure to translate on sentence to sentence level from now on.
I am half way through Lesson 3, can I leave the first half be for this version of translation?
Sure!
1 Like
Hi @jeremy
I have just submitted the finished version of Lesson 3 Chinese translation. Could you have a look?
Once this version of Chinese translation is accepted, if I make improvement edits later, do I have to get submit, reviewed by you for approval again before the changes can be seen publicly, right?
Thanks!
OK that should be accepted now.
I believe I have to accept any changes, yes.
1 Like
Thank you @jeremy
Yes, I can visit the course.fast.ai and watch the lesson with Chinese subtitles now, and I will keep working on the other lessons.
1 Like
持续更新 fastai 中文字幕
可能几年之后,机器翻译就会彻底取代人工字幕翻译,希望那一天到来前,我翻译的字幕能对大家有所帮助!
翻译,其实也是非常个性化的事情,每个人用语习惯不一样,希望大家不喜勿喷 
自定义的翻译质量目标:
- 努力确保意思准确传达(为了帮助大家更轻松理解深度学习);
- 努力做到句对句翻译(为了顺便学习英语的小伙伴,谢谢 @jeremy 提醒);
- phrase to sentence的翻译方式,感觉更高效,且更有助于中英对照 (个人感受)
- 专业术语,字幕中会保留完整英文,尽量寻找公允的中文对应
第一二版字幕出来后,肯定存在很多不足,欢迎大家多多指正!
我会持续维护和更新字幕,持续推出更完善的字幕版本,力争落实上述3个目标 
也欢迎大家就视频内容提问,我也努力回答!
第三课 第二版字幕已完成 官网 | B站
第四课 第二版字幕已完成 官网 | B站
第五课 第一版字幕已完成 官网 | B站
1 Like
非常棒! 正好在学Lession 3
1 Like