to improve the docs of untar_data
untar_data [source][test]
untar_data(url:str,fname:PathOrStr=None,dest:PathOrStr=None,data=True,force_download=False) →Path
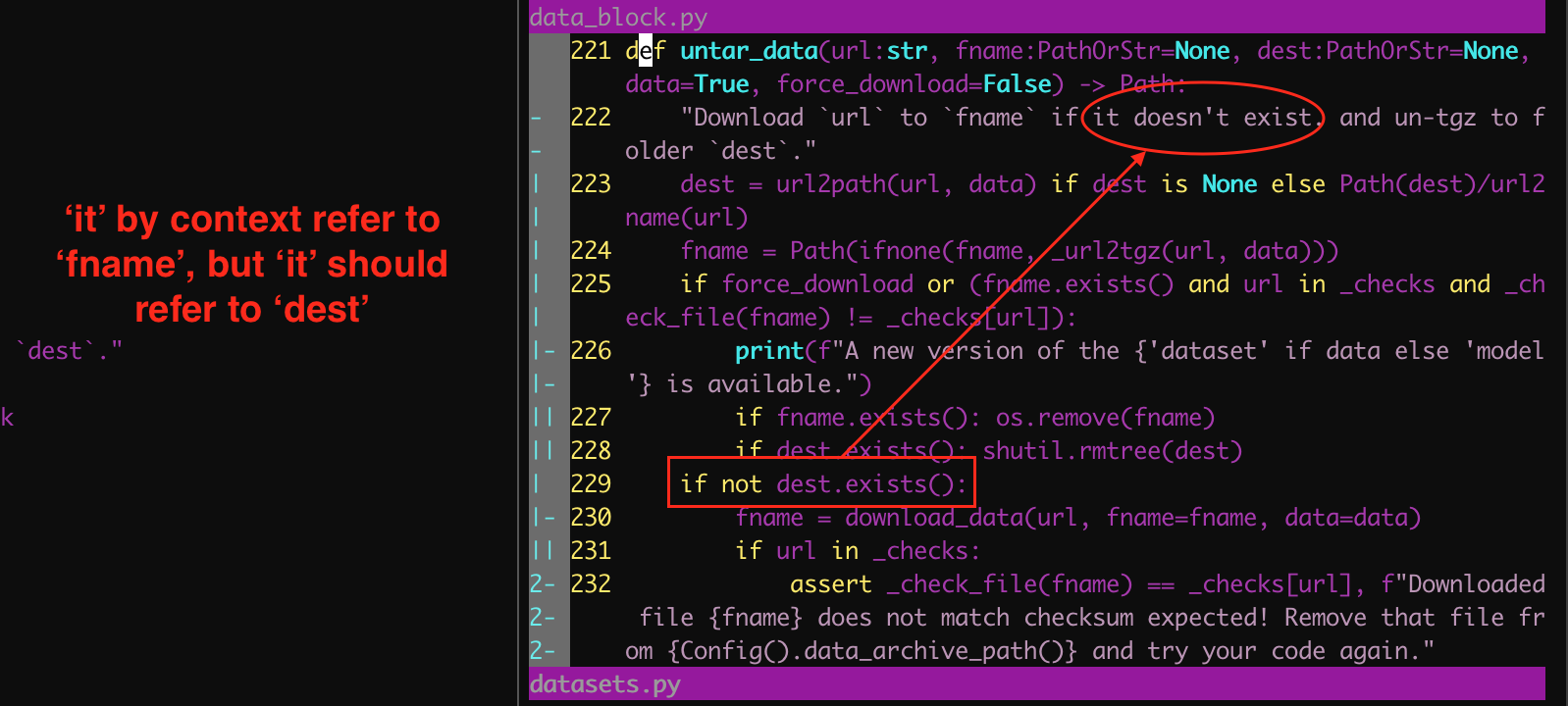
Download url to fname if it doesn’t exist, and un-tgz to folder dest .
it above in its semantic context refers to fname, but according to the source code, it should refer to dest, because only when not dest.exist() returns True, download_data will be executed
I would like to provide the following docs for untar_data
In general,
untar_datause aurlto download atgzfile underfname, and then un-tgzfnameinto a folder underdest.
After initial download, if running
untar_dataagain withforce_download=Trueor the tgz file underfnameis corrupted somehow, then existingfnameanddestwill be removed and start to download again.
After initial downloading, if
destdoes not exist, meaning no folder underdestexist (the folder could be removed or renamed somehow), then runninguntar_datawill executedownload_data; and if the tgz file underfnameexist, then there will be no actual downloading rather than un-tgzfnameintodest; iffnamedoes not exist, then downloading for the tgz file will be actually executed.
Note: the
urlyou feed tountar_datamust be one ofURLs.something.
What do you think of this version of docs? Thanks
@stas @sgugger