Neither I. I had to truncate my long post to limited number of words. Maybe in discourse settings something can be found.
1 Like
Lesson 1 你的宠物
如何启动你的第一个GPU
0:00-0:47
ytcropper Lesson 0 How to get GPU running
- Lesson 0 How to get GPU running gpu
如何启动你的第一个GPU
你需要做些什么准备
0:30-3:16
What else do you need to get started
你需要做些什么准备?
- Jupyter notebook基础
- Python 基础,学习资源
- 做实验的心态准备
如何最大化利用课程视频与notebook
3:13-4:29
How to make the most out of these lesson videos and notebooks
如何最大化利用课程视频与notebook?
- 从头看到尾,不要纠结概念细节
- 一边看,一边跑代码
- 试试实验代码
你可以期望的学习成就高度与关键学习资源
4:29-5:28
what you expect to be with fastai course
- 成为世界级水准深度学习实践者,构建和训练具备达到甚至超越学术界state of art水平的模型
为什么我们要跟着Jeremy Howard学习
5:26-6:47
why should we learn from Jeremy Howard
- 从事 ML 实践25年+
- 起始于麦肯锡首位数据分析专员,然后进入大咨询领域
- 创建并运行了多个初创企业
- 成为Kaggle主席
- 成为Kaggle排行第一级的参赛者
- 创建了Enlitic, 史上第一个深度学习医疗公司
- San Francisco大学教职人员
- 与Rachel Thomas共同创建了fastai
- 是务实非学术风格,聚焦于用深度学习做有用的事情
fast.ai让人人都成为深度学习高手的策略方针
6:40-7:26
How to make DL accessible to everyone to do useful things
- 创建fastai library
- 能用最简洁,最快速,最可靠的构建深度学习模型
- 创建fast.ai系列课程
- 帮助更多人免费便捷地学习
- 将学术论文成果落地 fastai library
- 将学术界最高水平的技术融入到fastai library中,让所有人便捷使用
- 创建维护学习社区
- 让深度学习实践者能够找到并帮助彼此
需要投入多少精力,会有怎样的收获
7:25-8:51
How much to invest and What I get out
- 我们需要投入都少精力学习?
- 看完课程视频至少需要14小时,完成代码实验整个课程至少需要70-80小时
- 当然具体情况,因人而异
- 有人全职学习
- 也有人只看视频,不做作业,只需要获取课程概要
- 如果跟玩整个课程,你将能够做到:
- 在世界级水平实践深度学习,甚至训练出打败学术state of art水平的模型
- 对任意图片数据集做分类
- 对文本做情感分类
- 预测连锁超市销售额
- 创建类似Netflix的电影推荐系统
学习深度学习的必要基础是什么,以及常见的误解与成见
8:51-10:23
Prerequisites and False assumptions and claims on DL
- 仅凭1年python和高中数学,你是无法学会深度学习的!
- fast.ai让其不攻自破
- 深度学习是黑箱,无法理解
- 很多模型是可解释可理解的
- 比如可以用可视化工具理解CNN参数的功能
- 需要巨量数据才能做深度学习
- 迁移学习不需要大量数据
- 可分享的训练好的模型
- 做前沿研究需要博士学位为前提
- fastai 或则 keras libs 和MOOCs就足够了
- Jeremy只有哲学学位
- 好应用仅限于视觉识别领域
- 优秀应用同样存在于speech, tabular data, time series领域
- 需要大量GPU为前提
- 一个云端GPU即可,甚至是免费的
- 当然对于大型项目,的确需要多个GPU
- 深度学习不是真正的AI
- 我们不是在造人造大脑
- 我们只是在用深度学习做造福世界的事情
完成第一课后你将能做些什么
10:22-11:04
What will you be able to do at the end of lesson 1
- 创建你的图片数据集的分类器
- 你甚至可以仅用30张图实现曲棍球和棒球的接近完美的分类器训练
fast.ai的教学哲学是什么
11:04-12:31
What is fastai learning philosophy
- 从代码开始,然后在尝试理解理论
- 不需要在博士最后一年才开始真正写代码做项目
- 创造多个模型,研究模型内部结构,掌握良好的深度学习实践者的直觉
- 用Jupyter notebooks做大量代码实验
如何像专业人士一样使用jupyter notebook
12:30-13:17 *
How to use Jupyter notebook as a pro
- 从最基础的快捷键开始,每天学习3-5个快捷键,每天用,很快就上手了
什么是Jupyter magics
13:17-14:00
What are Jupyter magics
什么是fastai库以及如何使用
14:00-17:56
What are fastai lib and how to use it
-
fast.ai课程和机构名称 -
fastai库的名称 - 依赖的library
-
pytorchis easier and more powerful than tensorflow
-
- fastai 支持四大领域应用
- CV, NLP, Tabular, Collaborative Filtering
- 两种
*的使用都支持-
from fastai import *(个人评论:但实际作用几乎为零) -
from fastai.vision import *引入所需工具
-
个人评论:代码探索发现 from fastai import *并无真用途
学术和Kaggle数据,CatsDogs 与 Pets数据的异同
17:56-21:08
Academic vs Kaggle Datasets, CatsDogs vs Pets dataset
两大数据集来源
- 学术和Kaggle
学术数据集特点?
- 学术人员耗费大量时间精力收集处理
- 用来解决富有挑战的问题
- 对比不同方法或模型的表现效果,从而凸显新方法的突破性表现
- 不断攀登和发表学术最优水平
为什么这些数据集有帮助?
- 提供强大的比较基准
- 排行榜与学界最优表现
- 从而得知你的模型的好坏程度
记住要注明对数据集和论文的引用
- 同时学习了解数据集创建的背景和方法
你的宠物数据集问题的难度
- 猫狗大战相比较是非常简单的问题
- 二元分类,全部猜狗也有50%准确率
- 而且猫狗之间差异大,特征比较简单
- 刚开始做猫狗大战竞赛时,80%已经是行业顶级水平
- 如今我们的模型几乎做到预测无误
- 宠物数据集要求识别37不同种的猫狗
- 猜一种只会有1/37正确率
- 因为不同种猫和不同种狗之间差异小,特征难度更高
- 我们要做的是细微特征分类fine-grain classification
如何下载数据集
21:07-23:56
How to download dataset with fastai
AWS 在云端为fast.ai所需数据集提供免费告诉下载
我们去Kernel中看untar_data的用法
如何进入图片文件夹以及查看里面的文件
23:56-25:49
How to access image folders and check filenames inside
我们去Kernel中看Path,ls,get_image_files的用法
如何从文件名中获取标注
25:40-27:53
How to get the labels of dataset
如何理解用regular expression 提取label,见笔记
运行代码理解其用法,见kernel
为什么以及如何选择图片大小规格
27:48-29:15
Why and how to pick the image size for DataBunch
- Why do we need to set the image size?
- every image has its size
- GPU needs images with same shape, size to run fast
- what shape we usually create?
- in part 1, square shape, most used
- in part 2, learn rectangle shape, with nuanced difference
- What size value work most of the time generally?
size = 224
- What special about fastai? *
- teach us the best and most used techniques to improve performance
- make the all the decisions for us if necessary, such as
size=224now
什么是DataBunch
29:15-29:56
What is a DataBunch
What does DataBunch contain
- training Dataset
- images and labels
- texts and labels
- tabular data and labels
- etc
- validation Dataset
- testing Dataset (optional)
如何normalize DataBunch
29:56-30:19
What does normalize do to DataBunch
to make data about the same size with same mean and std
如果图片大小不是224会怎样
30:19 - 31:50
What to do if size is not 224
* get_transforms function will make the size so
- data looks zoomed
- center-cropping
- resizing
- padding
- these techniques will be used in data augmentation
normalize 图片意味着什么
31:50-33:01
What does it mean to normalize images
* all pixel start 0 to 255
* but some channels are very bright and other not, vary a lot
* if all channels don’t have mean 0 and std 1
* models may be hard to train well
为什么图片尺寸是224而不是256
33:01- 33:34
Why 224 not 256 as power of 2
- because final layer of model is 7x7
- so 224 is better than 256
- more in later
如何查看图片和标注
33:34-35:06
How to check the real images and labels
* to be a really good practitioner is to look at your data
* how to look at your images
* data.show_batch(rows=3, figsize=(7,6))
* how to look at your labels
* print(data.classes
- what is data.c of DataBunch
* number of classes for classification problem
* not for regression and other problems
如何构建一个CNN模型
35:06-37:25
How to build a CNN learner/model
what is a Learner?
- things can learn to fit the data/model
what is ConvLearner?
- to create convolution NN
- ConvLearner is replaced by create_cnn *
what is needed to make such a model?
- required
- DataBunch
- Model: resnet34 or resnet50
- metrics = is from kwargs *
How to pick between resnet34 and resnet50?
- always start with smaller one
- then see whether bigger is better
What is metrics
- things to print out during training
- e.g., error_rate
为什么要用训练好的模型的框架与参数
37:25-40:03
Why use a pretrained model (framework and parameters) for your CNN? in other words, What is transfer learning?
* the model resnet34 will be automatically downloaded if not already so
* what exactly is downloaded
* pretrained model with weights trained with ImageNet dataset
* why a pretrained model is useful?
* such model can recognize 1000 categories
* not the 37 cats and dogs,
* but know quit a lot about cats and dogs
* what is transfer learning?
* take a model which already can do something very well (1000 objects)
* make it do your thing well (37 cats dogs species)
* also need thousands times less data to train your model
什么是过拟合?为什么我们的模型很难过拟合?
40:03-41:40
what is overfitting? why wouldn’t the model cheating?
How do we know the model is not cheating?
- not learn the patterns to tell cricket from baseball
- but only member those specific objects in the images
How to avoid cheating
- use validation set which your model doesn’t see when training
what use validation set for?
- use validation set to plot metrics to check how good model is fairly
Where is validation set?
- automatically and directly baked into the DataBunch
- to enforce the best practice, so it is impossible to not use it
如何用最优的技术来训练模型?
41:40-44:33
How to train the model with the best technique
we can use function fit, but always better to use fit_one_cycle
What is the big deal of fit_one_cycle?
- a paper released in 2018
- more accurate and faster than any previous approach
- ::fastai incorporates the best current techniques *::
keyboard shortcut for functions
* tab to use autocomplete for possible functions
* shift + tab to display all args for the function
how to pick the best number of epochs for training?
- learn how to tune epochs (4) in later lessons
- I don’t remember it had been discussed in later 6 lessons *
- not too many, otherwise easy overfit
如何了解模型的好坏?
44:28 - 46:42
How to find out how good is your model
- How to find out the state of art result of 2012 paper?
- Section of Experiment, check on accuracy
- Oxford, nearly 60% accuracy
- What is our result
- 96% accuracy
如何放大课程效果?
46:47-48:41
How to get the most out of this course
What is the most occurred mistake or regret?
- spend too much on the concept and theory
- spend too little time on notebooks and codes
What your most important skill is about
- understanding what goes in
- and what comes out
fastai的业界口碑以及与kera的对比
48:41-52:53
The popularity of fastai library
* Why we say fastai library becomes very popular and important
* major cloud support fastai
* many researchers start to use fastai
* what is the best way of understand fastai software well?
* docs.fast.ai
* How fastai compare with keras
* codes are much shorter
* keras has 31 lines which you need to make a lot of decisions
* fastai has 5 lines which make the decisions for you
* accuracy is much higher
* training time is much less
* cutting edge researches use fastai to build models
* “the ImageNet moment” for NLP done with fastai
* github: “towards Natural Language Semantic code search”
* Where on the forum people talking about papers?
* Deep Learning section
学员能够用fast.ai所学完成的项目
52:45-65:51
What students achieved with fastai and this course
Sarah Hooker
- first course student, economics (no background in coding)
- delta analytics to detect chainsaw to prevent rainforest
- google brain researcher and publish papers
- go to Africa to setup the first DL research center
- dig deep into the course and Deep learning book
Christine Mcleavey Payne
- 2018 year student
- openAI
- Clara: a neural net music generator
- background: math and …. too much to mention
- pick one project and do it really well and make it fantastic
Alexandre Cadrin
- can tell MIT X-ray chest model is overfitting
- bring deep learning into your industry and expertise
Melissa Fabros
- English literature degree, became Kiva engineer
- help Kiva (micro-lending) to recognize faces to reduce gender and racial bias
Karthik and envision
- after the course started a startup named envision
- help blind people use phone to see ahead of you
Jeremy helped a small student team
- to beat google team in ImageNet competition
Helena Saren? @glagoli…?
- combine her own artistic skills with image generator
- style transfer
a student as Splunk engineer to detect fraud
Francisco and Language Model Zoo at the forum
- use NLP to do different languages with different students
Don’t feel intimidated and ask for help and contribute
为什么选择ResNet 而非Inception作为模型框架和已训练的参数
66:00 - 67:57
Why use Resnet rather than Inception
* DAWNBench on ImageNet classification
* “Resnet is good enough” for top 5 places
* edge computing
* but the most flexible way is let your model on cloud talk with your mobile app
* inception is memory intensive and not resilient
如何保存训练好的模型
67:57-68:43
How to save a trained model
What is inside the trained model?
- updated weights
why do we need to save model?
- keep working and updating the previous weights
how to save a model?
- learn.save("stage-1")
where will be the model be located?
- in the same fold where data is
如何画出损失值最高的数据/图?
68:43-73:22
how to plot top losses examples/images
How to create model interpreter?
- interp = ClassificationInterpretation.from_learner(learn)
Why plot the high loss?
- to find out our high prob predictions are wrong
- they are the defect of our model
How to plot top losses using the interpreter?
- interp.plot_top_losses(9, figsize=(15,11))
How to read the output of the plotting and numbers?
- doc(interp.plot_top_losses) -> doc & source
What does those numbers on the plotting mean?
- prediction, actual, loss, prob of actual (not prediction)
Why fastai source code is very easy to read?
- intension when writing it
- don’t be afraid to read the source
Why it is useful to see top loss images
- figure out where is the weak spot
- error analysis * (Ng)
如何找出模型混淆度最高的图片?
73:20 -74:39
How to find out the most confused images of our model
* why we need the confusion matrix to interpret the model?
* when not to use interp.plot_confusion_matrix(figsize=(12,12), dpi=60)?
* when to use interp.most_confused(min_val=2)?
如何用微调改进模型?
74:37 - 76:26
How to improve our model
What is the default way of training?
- add a few layers at the end
- only train or update weights for the last few layers
What is the benefit of the default way?
- less likely to overfit
- much faster
How to train the whole model?
- unfreeze the model learn.unfreeze()
- train the entire model learn.fit_one_cycle(1)
why it is easy to ruin the model by training the whole model?
- learning rate is more likely to set too large for earlier layers *
- to understand it please see the next question
CNN模型在学习些什么?以及为什么直接用全模型学习效果不佳?
76:24 - 82:32
what is CNN actually learning and why previous full model training didn’t work
what is the plot of layer 1?
- coefficients? weights? filters
- finding some basic shapes
what are the plots of layer 2?
- 16 filters
- each filter is good at finding one type of pattern
What are the plots of layer3?
- 12 filters
- each is more complex patterns
What are inside plots of layer4 and layer 5?
- filters to find out even more complex patterns using previous layer patterns
Which layer’s filter pattern can be improved?
- less likely for layer 1
- maybe not layer 4-5
- probably much later layers should be changed to some extent
Why the previous full model train won’t work?
- the same learning rate is applied to earlier and later layers
训练全模型的正确方式是什么
82:32- 86:55
How to train the whole model in the right way
How we go back to the unbroken model by full training?
- load the backup model
- learn.load('stage-1');
How to find the best learning rate?
- to find the fastest learning rate value
- learn.lr_find()
How to plot the result of learning rate finding?
- learn.recorder.plot()
how to read the learning rate plot?
- learn.unfreeze()
- learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))
- how to find the lowest/fastes learning rate?
- find the lr value before loss get worse
- how to find the highest/slowest learning rate?
- 10x smaller than original learning rate
- how to give learning rate value to middle layers?
- distribute values equally to other middle layers
Why you can’t win Kaggle easily?
- many fastai alumni compete on Kaggle
- this is the first thing they will try out
如何用更大的模型来改进效果
86:55-91:00
How to improve model with more layers
to use ResNet50 instead of ResNet34
- data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=299, bs=bs//2).normalize(imagenet_stats)
- learn = create_cnn(data, models.resnet50, metrics=error_rate)
what to do when GPU memory is tight?
- due to model is too large and take too much GPU memory
- less 8 GPU memory can’t run ResNet50
How to fix it?
- shrink the batch_size when creating the DataBunch
How good is 4% error rate for Pets dataset?
- compare to CatsDogs 3% error rate
- 4% for 37 similar looking species is extraordinary
Why ResNet50 still use the same lr range from ResNet34? *
- the lr plot looks different from that of ResNet34
- but why we still use the following code
- learn.fit_one_cycle(3, max_lr=slice(1e-6,1e-4))
- problem asked on formum
How to use most confused images to demonstrate model is already quite good?
- check out the most confused images online
- see whether human can’t tell the difference neither
- if so, then model is doing good enough
- it teaches you to become a domain expert
生成DataBunch的不同方式有哪些
91:35-95:10
Different ways to put your data into DataBunch
How to use MNIST sample dataset?
* path = untar_data(URLs.MNIST_SAMPLE); path
How to create DataBunch while labels on folder names?
- data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=26)
How to check the images and labels?
How to read from CSV?
- df = pd.read_csv(path/'labels.csv')
How to create DataBunch while labels in CSV file?
- data = ImageDataBunch.from_csv(path, ds_tfms=tfms, size=28)
How to create DataBunch while labels in dataframe?
- data = ImageDataBunch.from_df(path, df, ds_tfms=tfms, size=24)
How to create DataBunch while labels in filename?
- data = ImageDataBunch.from_name_re(path, fn_paths, pat=pat, ds_tfms=tfms, size=24)
How to create DataBunch while labels in filename using function?
- data = ImageDataBunch.from_name_func(path, fn_paths, ds_tfms=tfms, size=24, label_func = lambda x: '3' if '/3/' in str(x) else '7')
How to create DataBunch while labels in a list?
- labels = [('3' if '/3/' in str(x) else '7') for x in fn_paths]
- data = ImageDataBunch.from_lists(path, fn_paths, labels=labels, ds_tfms=tfms, size=24)
如何最大化利用fastai文档
95:10-97:28
How to make the most out of documents
- To experiment the doc notebook
- How do I do better?
关于fastai与多GPU和3D数据的问题
97:28-98:09
QA on fastai with multi-GPU, 3D data
一些有趣的项目
98:09-end
An interesting and inspiring project
how to transform mouse moment into images
then train it with CNN
5 Likes
第二课 创造你的数据集
如何使用论坛与参与贡献
how to use forum and contribute to fastai
start - 4:26
how to use forum and contribute to fastai
resources
* How to contribute to fastai - Part 1 (2019)
* Doc Maintenance | fastai
where is the most important information at forum?
- official updates and resources
- start from here
how not be intimidated by the overwhelming forum
- click summary button
如何重返工作
How to return to work?
- with [kaggle](https://course.fast.ai/update_kaggle.html)
- click into kernels
- with your local workplace
- `git pull`
- `condo update conda` outside conda environment
- `conda install -c fastai fastai`
学员第一周的成果
What students have done after the first week?
4:26-12:56
What students have done after the first week
- use NN to clear whatapp downloaded images
- use NN to beat the state of art on recognize background noise
- new state of art performance on a language DHCD recognition
- turn point mutation of tumor into images and beat the sate of art
- automatically playing science communication games with transfer learning and fastai
- James Delinger: do useful things without reading math equations (greek)
- Daniel R. Armstrong: want to contribute to the library, step by step, you will get there
- project to classify zucchinis (39 images) and cucumbers (47 images)
- use PCA to create a hairless classifier for dogs and cats
- classifier for new and old special buses
- models classify 110 cities from satellite images
- models to classify complete and incomplete construction sites
课程结构和教学哲学
What is the course structure and teaching philosophy
12:56 - 16:20
What is the course structure and teaching philosophy
* recursive learning in curriculum
* Perkins’s theory (chinese version)
* code first
* whole game with videos
* concepts not details
* keep moving forward
如何创造属于你的图片分类数据集
How to create your own dataset for classifier
16:20-23:47
How to create your own dataset for classifier
inspired by PyImageSearch, great resources
project to classify teddy bear, grizzly bear and black bear
search “teddy bear” in google image
- ctrl+shift+j or cmd+opt+j
paste the codes and save image urls into a file in your directory
how to create three set of folders experimentally
- create variables for a folder and url.txt
- create the folder path
- download the images into the folder
- do it three times for three kinds of bears
How to verify images that are problematic with `verify_images’?
如何从单一图片文件夹中创造DataBunch
How to create DataBunch from a single fold of images?
23:47-25:42
How to create DataBunch from a single fold of images
- how to set the training set from the single folder
- how to split into a validation set from the single folder
- why set random seed before creating DataBunch?
如何检验图片,标注,数据集的大小
How to check images, labels, and sizes of train and validation set
25:42-26:49
How to check images, labels, and sizes of train and validation set
* How to display images from a batch
* How to check labels and classes
* How to count the size of train_ds and valid_ds?
如何训练和保存模型
How to train and save the model
26:49-27:41
How to train and save the model
- how to create a CNN model with ResNet34 and plot error-rate
- how to train the model for 4 epochs
- how to save the trained model
如何寻找最优学习率
如何从图中读取最优学习率区间
27:36-29:39
视频节点
- 怎样的下坡才是真正有意义的最优学习率区间?
- “bumpy"起伏不平的不好,”平滑坡陡”更好?
- 主要靠实验来积累感官经验,构造良好直觉
- 怎么选择的 (3e-5, 3e-4)?
- 确定好了3e-5后,通常选择1e-4或3e-4
- 依旧是依靠实验和经验累积
如何解读模型
How to interpret the model
29:39-29:57
How to interpret the model
how to read most confused matrix?
噪音数据和模型输出
Noisy data and model output
29:57-31:31
Noisy data and model output
What does noisy data mean?
- such as mislabelled data
What problem noisy data could cause model to have?
- unlikely, some data are predicted correctly with high confidence
- these data are likely to be mislabelled
Solution approach
- joint domain expert and machine automation
如何用widget清理数据中的噪音
How to clean up noisy data with widget?
31:31-35:32
How to clean up noisy data with widget
How to work with widget to clean mislabelled data manually?
如何为Nb创造一个widget
How to build a ipywidget for your notebook
35:12-37:37
How to build a ipywidget for your notebook
how to read the source code of the widget?
how to build a tool for notebook experimenter?
Exciting to create tools for fellow practitioners
encouraged to dig into the ipywidget docs
not a production web app
什么是偏差噪音
What is biased noise?
37:35-38:32
What is biased noise?
* most time after remove mislabelled data, model improved only a little
* it is normal as model can handle some level of noise itself
* what is toxic is biased noise, not randomly noisy data
如何将模型植入APP
How to put model into production web app?
38:32-45:50
How to put model into production web app
* why to run production on CPU not GPU?
* the time difference between CPU web app vs GPU server is 0.2 vs 0.01s
* how to prepare your model for production use?
* it is very easy and free to use with some instruction on course wiki
* try to make all your classifier into web apps
99%的时间里我们只需调控学习率和训练次数
99% of time what we need to finetune is lr and epochs for CV
46:05-53:09
99% of time what we need to finetune is lr and epochs for CV
experiment what happen when lr is very high
- no way to undo it, has to recreate model
experiment what happen when lr is too low
- loss down very slow
validation loss is lower than training loss
- lr is too low
- too few epochs
too many epochs
- overfitting - to learn specific images of teddy bears
- signal - loss goes down but goes up again
- but it is difficult to make our model to overfit
图片和图片识别背后的数学
what is the math behind an image and its classification?
53:09-62:15
what is the math behind an image and its classification
what is the math behind an image and its classification?
what is behind learn.predict source
what does np.argmax do
what is error_rate source code?
what is behind accuracy function?
which dataset does metric apply to?
doc is not just nice printing of ?, because it may has examples
why use the 3 of 3e-5 often?
线性函数,数组乘法与神经网络的关系
what is linear function, and how matrix multiplication fit in?
62:15- 68:23
what is linear function, and how matrix multiplication fit in
* KhanAcademy for basics and advanced math
* to replace b with a_2*x_2
* there are lots of examples (x1, y1), (x2, y2), …
* Rachel’s best linear algebra course
* vectorization, dot product, matrix product to avoid loop and speed up
* matrix multiplication in visualization
关于数据大小,不对称数据,模型结构,参数的问题
QA on data size, unbalanced data, model framework and weights
68:32-74:14
QA on data size, unbalanced data, model framework and weights
How do we know we don’t have enough data
* lr is good, can’t be a little higher or lower
* if epochs goes a little bigger then make validation loss worse
* then we may need to get more data
* most time you need less data than you think
How do you deal with unbalanced data?
- do nothing, it always works
What is ResNet34 as function?
- function framework without number or weights
- pretrained model with weights
如何手动构建一个简单的神经网络
How to create the simplest NN (tensor, rank)?
74:14-101:10
How to create the simplest NN (tensor, rank)
what is the simplest architecture?
what is SGD?
how to generate some data for a simple linear function?
how to use matrix product @ to create the linear architecture?
what is a tensor?
- array
what is a rank?
- rank 1 tensor is a vector
how to create the X features?
how to create the coefficients or the weights?
how to plot the x and y (ignoring x_2 as it is just 1)?
what about matplotlib?
how to create MSE function?
how to do scatter plot?
how to do Gradient Descent?
how to calculate derivative with Pytorch?
为什么需要学习率
why do we need learning rate at all?
101:10-105:47
why do we need learning rate at all
- derivative tells us direction and how much
- but it may not best reduce the loss
- we need learning rate to help get loss down appropriately
为什么小批量让训练更高效
why mini-batches makes training more efficient?
108:09-109:49
why mini-batches makes training more efficient
新学到的词汇
What are the new vocab learnt?
109:49-111:43
What are the new vocal learnt?
Learning rate
epoch: too many epochs, easily overfit
mini batch: more efficient than full batch training
SGD : GD with mini-batch
Model/Architecture: y = x@a, Resnet34, matrix product
parameters: weights
loss function
什么是过拟合,正则化与验证集
what is overfitting and regularization and validation set
114:43-end
what is overfitting and regularization and validation set
- what is training dataset on the graph?
- which model/graph is underfitting the training set?
- doing bad, having worse loss
- which model/graph is overfitting the training set?
- doing good, having low loss
- both are different from the right model
- both have bad loss on new/validation dataset
- false assumption
- more parameters -> overfitting
- less parameters -> underfitting
- truth
- overfitting and underfitting -> nothing to do with parameter number
- boss and org
- training set can tell underfitting from overfitting and ok models
- validation set can differ overfitting model from OK model
- use validation set from being sold snake oil
- further study
- Rachel’s blog post
- Rachel’s courses


2 Likes
第一课 你的宠物
本Nb的目的
the purpose of this Nb
In this lesson we will build our first image classifier from scratch, and see if we can achieve world-class results. Let’s dive in!
三行Jupyter notebook魔法代码
three lines of magics
Every notebook starts with the following three lines; they ensure that any edits to libraries you make are reloaded here automatically, and also that any charts or images displayed are shown in this notebook.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
fastai如何使用import
how fastai designs import
We import all the necessary packages. We are going to work with the fastai V1 library which sits on top of Pytorch 1.0. The fastai library provides many useful functions that enable us to quickly and easily build neural networks and train our models.
如何快速调用我们所需的一切
import everything we need
from fastai.vision import *
from fastai.metrics import error_rate
如何解决内存不够问题?
how to handle out of memory problem?
If you’re using a computer with an unusually small GPU, you may get an out of memory error when running this notebook. If this happens, click Kernel->Restart, uncomment the 2nd line below to use a smaller batch size (you’ll learn all about what this means during the course), and try again.
设置小批量大小
set batch_size
bs = 64
# bs = 16 # uncomment this line if you run out of memory even after clicking Kernel->Restart
Looking at the data
关于Pets数据集
What Pets dataset is about?
We are going to use the Oxford-IIIT Pet Dataset by O. M. Parkhi et al., 2012 which features 12 cat breeds and 25 dogs breeds. Our model will need to learn to differentiate between these 37 distinct categories. According to their paper, the best accuracy they could get in 2012 was 59.21%, using a complex model that was specific to pet detection, with separate “Image”, “Head”, and “Body” models for the pet photos. Let’s see how accurate we can be using deep learning!
We are going to use the untar_data function to which we must pass a URL as an argument and which will download and extract the data.
如何查看函数文档帮助
How to get docs
help(untar_data)
Help on function untar_data in module fastai.datasets:
untar_data(url: str, fname: Union[pathlib.Path, str] = None, dest: Union[pathlib.Path, str] = None, data=True, force_download=False) -> pathlib.Path
Download `url` to `fname` if it doesn't exist, and un-tgz to folder `dest`.
fastai如何下载数据集
how fastai get dataset
path = untar_data(URLs.PETS); path
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet')
如何快捷查看文件夹内容
how to see inside a folder
path.ls()
[PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images'),
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/annotations')]
如何快速查看子文件夹
how to build path to sub-folders
path_anno = path/'annotations'
path_img = path/'images'
怎样才算查看数据
what does it mean to look at the data
The first thing we do when we approach a problem is to take a look at the data. We always need to understand very well what the problem is and what the data looks like before we can figure out how to solve it. Taking a look at the data means understanding how the data directories are structured, what the labels are and what some sample images look like.
处理数据集的难点是获取标注
getting labels is the key of handling dataset
The main difference between the handling of image classification datasets is the way labels are stored. In this particular dataset, labels are stored in the filenames themselves. We will need to extract them to be able to classify the images into the correct categories. Fortunately, the fastai library has a handy function made exactly for this, ImageDataBunch.from_name_re gets the labels from the filenames using a regular expression.
如何将文件夹中文件转化为文件地址列表
turn files inside a folder into a list of path objects
fnames = get_image_files(path_img)
fnames[:5]
[PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images/saint_bernard_188.jpg'),
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images/staffordshire_bull_terrier_114.jpg'),
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images/Persian_144.jpg'),
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images/Maine_Coon_268.jpg'),
PosixPath('/home/ubuntu/.fastai/data/oxford-iiit-pet/images/newfoundland_95.jpg')]
如何确保验证集一致性?
how to make sure the same validation set?
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
如何从regular expression 创建ImageDataBunch
how to create an ImageDataBunch from re
data = ImageDataBunch.from_name_re(path_img,
fnames,
pat,
ds_tfms=get_transforms(),
size=224,
bs=bs
).normalize(imagenet_stats)
打印图片和标注
print out images with labels
data.show_batch(rows=3, figsize=(7,6))

打印类别和c
print out all classes and c
print(data.classes)
len(data.classes),data.c
['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair', 'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue', 'Siamese', 'Sphynx', 'american_bulldog', 'american_pit_bull_terrier', 'basset_hound', 'beagle', 'boxer', 'chihuahua', 'english_cocker_spaniel', 'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese', 'japanese_chin', 'keeshond', 'leonberger', 'miniature_pinscher', 'newfoundland', 'pomeranian', 'pug', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu', 'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']
(37, 37)
Training: resnet34
迁移学习大概模样?
what is transfer learning like?
Now we will start training our model. We will use a convolutional neural network backbone and a fully connected head with a single hidden layer as a classifier. Don’t know what these things mean? Not to worry, we will dive deeper in the coming lessons. For the moment you need to know that we are building a model which will take images as input and will output the predicted probability for each of the categories (in this case, it will have 37 outputs).
We will train for 4 epochs (4 cycles through all our data).
如何做CNN迁移学习
how to create a CNN model as transfer learning
learn = create_cnn(data, models.resnet34, metrics=error_rate)
如何查看模型结构
how to see the structure of model
learn.model
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten()
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25)
(4): Linear(in_features=1024, out_features=512, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
(8): Linear(in_features=512, out_features=37, bias=True)
)
)
如何用最优默认值训练模型
how to fit the model with the best default setting
learn.fit_one_cycle(4)
Total time: 01:46
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 1.409939 | 0.357608 | 0.102165 |
| 2 | 0.539408 | 0.242496 | 0.073072 |
| 3 | 0.340212 | 0.221338 | 0.066306 |
| 4 | 0.261859 | 0.216619 | 0.071042 |
如何保存模型
how to save a model
learn.save('stage-1')
Results
如何判断模型是否工作正常?
how do we know our model is working correctly or reasonably or not?
Let’s see what results we have got.
We will first see which were the categories that the model most confused with one another. We will try to see if what the model predicted was reasonable or not. In this case the mistakes look reasonable (none of the mistakes seems obviously naive). This is an indicator that our classifier is working correctly.
confusion matrix能告诉我们什么?
what can confusion matrix tell us?
Furthermore, when we plot the confusion matrix, we can see that the distribution is heavily skewed: the model makes the same mistakes over and over again but it rarely confuses other categories. This suggests that it just finds it difficult to distinguish some specific categories between each other; this is normal behaviour.
如何获取最大损失值对应照片的序号和损失值
how to access the idx and losses of the images with the top losses
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
len(data.valid_ds)==len(losses)==len(idxs)
True

如何查看漂亮的docs
how to print out docs nicely
doc(interp.plot_top_losses)
如何画confusion matrix
how to plot confusion matrix
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)
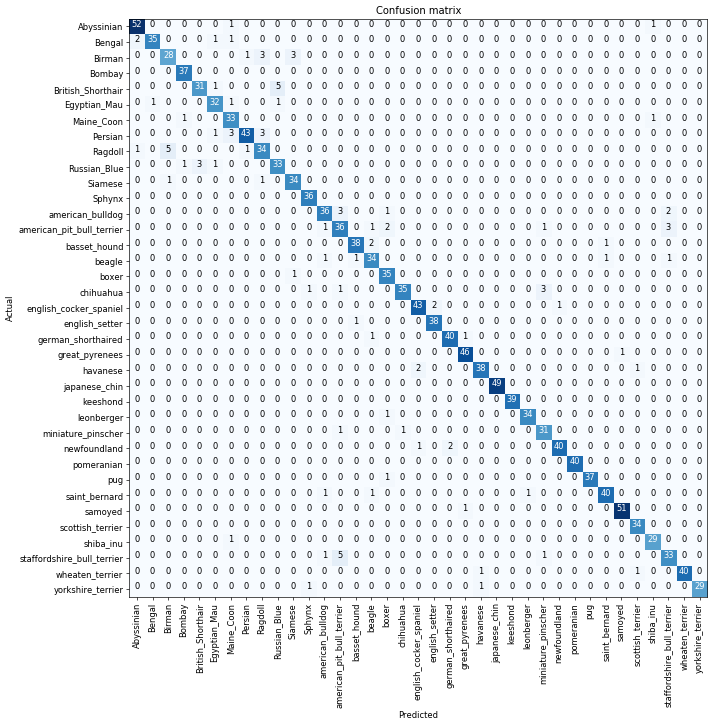
如何打印出最易出错的类别和它们的计数
how to print out the most confused categories and count errors
interp.most_confused(min_val=2)
[('British_Shorthair', 'Russian_Blue', 5),
('Ragdoll', 'Birman', 5),
('staffordshire_bull_terrier', 'american_pit_bull_terrier', 5),
('Birman', 'Ragdoll', 3),
('Birman', 'Siamese', 3),
('Persian', 'Maine_Coon', 3),
('Persian', 'Ragdoll', 3),
('Russian_Blue', 'British_Shorthair', 3),
('american_bulldog', 'american_pit_bull_terrier', 3),
('american_pit_bull_terrier', 'staffordshire_bull_terrier', 3),
('chihuahua', 'miniature_pinscher', 3)]
Unfreezing, fine-tuning, and learning rates
什么时候解冻模型?
when to unfreeze the model?
Since our model is working as we expect it to, we will unfreeze our model and train some more.
如何解冻模型?
how to unfreeze the model?
learn.unfreeze()
如何训练一次
how to fit for one epoch
learn.fit_one_cycle(1)
Total time: 00:26
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.558166 | 0.314579 | 0.101489 |
如何保存模型
how to save the model
learn.load('stage-1');
如何在一个范围里探索学习率对损失值影响?
how to explore lr within a range for lower loss?
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
如何对学习率损失值作图以及解读最佳区间?
how to plot the loss-lr graph and read the best range?
learn.recorder.plot()

如何解冻模型并用学习率区间训练数次
how to unfreeze model and fit with a specific range of lr with epochs
learn.unfreeze()
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))
Total time: 00:53
| epoch | train_loss | valid_loss | error_rate |
|---|---|---|---|
| 1 | 0.242544 | 0.208489 | 0.067659 |
| 2 | 0.206940 | 0.204482 | 0.062246 |
That’s a pretty accurate model!
Training: resnet50
what is the difference between resnet34 and resnet50
what is the difference between resnet34 and resnet50
Now we will train in the same way as before but with one caveat: instead of using resnet34 as our backbone we will use resnet50 (resnet34 is a 34 layer residual network while resnet50 has 50 layers. It will be explained later in the course and you can learn the details in the resnet paper).
why use larger model and image to train with smaller batch size?
why use larger model and image to train with smaller batch size?
Basically, resnet50 usually performs better because it is a deeper network with more parameters. Let’s see if we can achieve a higher performance here. To help it along, let’s us use larger images too, since that way the network can see more detail. We reduce the batch size a bit since otherwise this larger network will require more GPU memory.
how to create an ImageDatabunch with re and setting image size and batch size?
how to create an ImageDatabunch with re and setting image size and batch size?
data = ImageDataBunch.from_name_re(path_img,
fnames,
pat,
ds_tfms=get_transforms(),
size=299,
bs=bs//2).normalize(imagenet_stats)
how to create an CNN model with this data?
how to create an CNN model with this data?
learn = create_cnn(data, models.resnet50, metrics=error_rate)
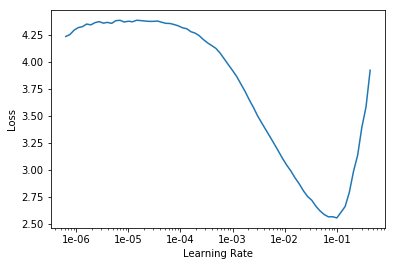
find and plot the loss-lr relation
find and plot the loss-lr relation
learn.lr_find()
learn.recorder.plot()
LR Finder complete, type {learner_name}.recorder.plot() to see the graph.
how to fit the model 8 epochs
how to fit the model 8 epochs
learn.fit_one_cycle(8)
Total time: 06:59
epoch train_loss valid_loss error_rate
1 0.548006 0.268912 0.076455 (00:57)
2 0.365533 0.193667 0.064953 (00:51)
3 0.336032 0.211020 0.073072 (00:51)
4 0.263173 0.212025 0.060893 (00:51)
5 0.217016 0.183195 0.063599 (00:51)
6 0.161002 0.167274 0.048038 (00:51)
7 0.086668 0.143490 0.044655 (00:51)
8 0.082288 0.154927 0.046008 (00:51)
how to save the model with a different name
how to save the model with a different name
learn.save('stage-1-50')
It’s astonishing that it’s possible to recognize pet breeds so accurately! Let’s see if full fine-tuning helps:
how to unfreeze and fit with a specific range for 3 epochs
how to unfreeze and fit with a specific range for 3 epochs
learn.unfreeze()
learn.fit_one_cycle(3, max_lr=slice(1e-6,1e-4))
Total time: 03:27
epoch train_loss valid_loss error_rate
1 0.097319 0.155017 0.048038 (01:10)
2 0.074885 0.144853 0.044655 (01:08)
3 0.063509 0.144917 0.043978 (01:08)
how to go back to previous model
how to go back to previous model
learn.load('stage-1-50');
how to get classification model interpretor
how to get classification model interpretor
interp = ClassificationInterpretation.from_learner(learn)
how to print out the most confused categories with minimum count
how to print out the most confused categories with minimum count
interp.most_confused(min_val=2)
[('american_pit_bull_terrier', 'staffordshire_bull_terrier', 6),
('Bengal', 'Egyptian_Mau', 5),
('Bengal', 'Abyssinian', 4),
('boxer', 'american_bulldog', 4),
('Ragdoll', 'Birman', 4),
('Egyptian_Mau', 'Bengal', 3)]
Other data formats
how to get MNIST_SAMPLE dataset
how to get MNIST_SAMPLE dataset
path = untar_data(URLs.MNIST_SAMPLE); path
PosixPath('/home/ubuntu/course-v3/nbs/dl1/data/mnist_sample')
how to set flip false for transformation
how to set flip false for transformation
tfms = get_transforms(do_flip=False)
how to create ImageDataBunch from folders
how to create ImageDataBunch from folders
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=26)
how to print out image examples from a batch
how to print out image examples from a batch
data.show_batch(rows=3, figsize=(5,5))

how to create a cnn with resnet18 and accuracy as metrics
how to create a cnn with resnet18 and accuracy as metrics
learn = create_cnn(data, models.resnet18, metrics=accuracy)
how to fit 2 epocs
how to fit 2 epocs
learn.fit(2)
Total time: 00:23
epoch train_loss valid_loss accuracy
1 0.116117 0.029745 0.991168 (00:12)
2 0.056860 0.015974 0.994603 (00:10)
how to read a csv with pd
how to read a csv with pd
df = pd.read_csv(path/'labels.csv')
how to read first 5 lines
how to read first 5 lines
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| name | label | |
|---|---|---|
| 0 | train/3/7463.png | 0 |
| 1 | train/3/21102.png | 0 |
| 2 | train/3/31559.png | 0 |
| 3 | train/3/46882.png | 0 |
| 4 | train/3/26209.png | 0 |
how to create ImageDataBunch with csv
how to create ImageDataBunch with csv
data = ImageDataBunch.from_csv(path, ds_tfms=tfms, size=28)
how to print out images from a batch and classes
how to print out images from a batch and classes
data.show_batch(rows=3, figsize=(5,5))
data.classes
[0, 1]

how to create ImageDataBunch from df
how to create ImageDataBunch from df
data = ImageDataBunch.from_df(path, df, ds_tfms=tfms, size=24)
data.classes
[0, 1]
how to create file path object into a list from df
how to create file path object into a list from df
fn_paths = [path/name for name in df['name']]; fn_paths[:2]
[PosixPath('/home/ubuntu/course-v3/nbs/dl1/data/mnist_sample/train/3/7463.png'),
PosixPath('/home/ubuntu/course-v3/nbs/dl1/data/mnist_sample/train/3/21102.png')]
how to create ImageDataBunch from re
how to create ImageDataBunch from re
pat = r"/(\d)/\d+\.png$"
data = ImageDataBunch.from_name_re(path, fn_paths, pat=pat, ds_tfms=tfms, size=24)
data.classes
['3', '7']
how to create ImageDataBunch from name function with file path list
how to create ImageDataBunch from name function with file path list
data = ImageDataBunch.from_name_func(path, fn_paths, ds_tfms=tfms, size=24,
label_func = lambda x: '3' if '/3/' in str(x) else '7')
data.classes
['3', '7']
how to create a list of labels from list of file path
how to create a list of labels from list of file path
labels = [('3' if '/3/' in str(x) else '7') for x in fn_paths]
labels[:5]
['3', '3', '3', '3', '3']
how to create an ImageDataBunch from list
how to create an ImageDataBunch from list
data = ImageDataBunch.from_lists(path, fn_paths, labels=labels, ds_tfms=tfms, size=24)
data.classes
['3', '7']
3 Likes
如何创建属于你自己的图片数据集
Creating your own dataset from Google Images
Nb的目的
Nb的目的
by: Francisco Ingham and Jeremy Howard. Inspired by Adrian Rosebrock
In this tutorial we will see how to easily create an image dataset through Google Images. Note: You will have to repeat these steps for any new category you want to Google (e.g once for dogs and once for cats).
仅需的library
仅需的library
from fastai.vision import *
Get a list of URLs
如何精确搜索
如何精确搜索
Search and scroll
Go to Google Images and search for the images you are interested in. The more specific you are in your Google Search, the better the results and the less manual pruning you will have to do.
Scroll down until you’ve seen all the images you want to download, or until you see a button that says ‘Show more results’. All the images you scrolled past are now available to download. To get more, click on the button, and continue scrolling. The maximum number of images Google Images shows is 700.
It is a good idea to put things you want to exclude into the search query, for instance if you are searching for the Eurasian wolf, “canis lupus lupus”, it might be a good idea to exclude other variants:
"canis lupus lupus" -dog -arctos -familiaris -baileyi -occidentalis
You can also limit your results to show only photos by clicking on Tools and selecting Photos from the Type dropdown.
如何下载图片的链接
如何下载图片的链接
Download into file
Now you must run some Javascript code in your browser which will save the URLs of all the images you want for you dataset.
Press CtrlShiftJ in Windows/Linux and CmdOptJ in Mac, and a small window the javascript ‘Console’ will appear. That is where you will paste the JavaScript commands.
You will need to get the urls of each of the images. You can do this by running the following commands:
urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);
window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));
创建文件夹并上传链接文本到云端
创建文件夹并上传链接文本到云端
Create directory and upload urls file into your server
Choose an appropriate name for your labeled images. You can run these steps multiple times to create different labels.
一个类别,一个文件夹,一个链接文本
folder = 'black'
file = 'urls_black.txt'
folder = 'teddys'
file = 'urls_teddys.txt'
folder = 'grizzly'
file = 'urls_grizzly.txt'
You will need to run this cell once per each category.
下面这个Cell,每个类别运行一次
创建子文件夹
创建子文件夹
path = Path('data/bears')
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
查看文件夹内部
查看文件夹内部
path.ls()
[PosixPath('data/bears/urls_teddy.txt'),
PosixPath('data/bears/black'),
PosixPath('data/bears/urls_grizzly.txt'),
PosixPath('data/bears/urls_black.txt')]
Finally, upload your urls file. You just need to press ‘Upload’ in your working directory and select your file, then click ‘Upload’ for each of the displayed files.
通过云端的Nb’upload’来上传
Download images
如何下载图片并设置下载数量上限
如何下载图片并设置下载数量上限
Now you will need to download your images from their respective urls.
fast.ai has a function that allows you to do just that. You just have to specify the urls filename as well as the destination folder and this function will download and save all images that can be opened. If they have some problem in being opened, they will not be saved.
Let’s download our images! Notice you can choose a maximum number of images to be downloaded. In this case we will not download all the urls.
You will need to run this line once for every category.
classes = ['teddys','grizzly','black']
download_images(path/file, dest, max_pics=200)
下载出问题的处理方法
下载出问题的处理方法
# If you have problems download, try with `max_workers=0` to see exceptions:
download_images(path/file, dest, max_pics=20, max_workers=0)
如何删除无法打开的图片
如何删除无法打开的图片
Then we can remove any images that can’t be opened:
for c in classes:
print(c)
verify_images(path/c, delete=True, max_size=500)
View data
从一个文件夹生成DataBunch
从一个文件夹生成DataBunch
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
用CSV文件协助生成DataBunch
用CSV文件协助生成DataBunch
# If you already cleaned your data, run this cell instead of the one before
# np.random.seed(42)
# data = ImageDataBunch.from_csv(".", folder=".", valid_pct=0.2, csv_labels='cleaned.csv',
# ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
Good! Let’s take a look at some of our pictures then.
查看类别
查看类别
data.classes
['black', 'grizzly', 'teddys']

查看类别,训练集和验证集的数量
查看类别,训练集和验证集的数量
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
(['black', 'grizzly', 'teddys'], 3, 448, 111)
Train model
创建基于Resnet34的CNN模型
创建基于Resnet34的CNN模型
learn = create_cnn(data, models.resnet34, metrics=error_rate)
用默认参数训练4次
用默认参数训练4次
learn.fit_one_cycle(4)
保存模型
保存模型
learn.save('stage-1')
解冻模型
解冻模型
learn.unfreeze()
当前寻找最优学习率
当前寻找最优学习率
learn.lr_find()
对学习率和损失值作图
对学习率和损失值作图
learn.recorder.plot()
用学习率区间训练2次
用学习率区间训练2次
learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4))
保存模型
保存模型
learn.save('stage-2')
Interpretation 解读
加载模型
加载模型
learn.load('stage-2');
生成分类器解读器
生成分类器解读器
interp = ClassificationInterpretation.from_learner(learn)
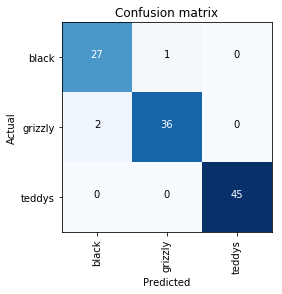
对confusion matrix 作图
对confusion matrix 作图
interp.plot_confusion_matrix()
Cleaning Up
调用widget
调用widget
Some of our top losses aren’t due to bad performance by our model. There are images in our data set that shouldn’t be.
有些高损失值是因为错误标注造成的。
Using the ImageCleaner widget from fastai.widgets we can prune our top losses, removing photos that don’t belong.
ImageCleaner可以帮助找出和清除这些图片
from fastai.widgets import *
如何获取高损失值图片的图片数据和序号
如何获取高损失值图片的图片数据和序号
First we need to get the file paths from our top_losses. We can do this with .from_toplosses. We then feed the top losses indexes and corresponding dataset to ImageCleaner.
Notice that the widget will not delete images directly from disk but it will create a new csv file cleaned.csv from where you can create a new ImageDataBunch with the corrected labels to continue training your model.
ds, idxs = DatasetFormatter().from_toplosses(learn, ds_type=DatasetType.Valid)
用`ImageCleaner`生成这些图片以便清除
用ImageCleaner生成这些图片以便清除
ImageCleaner(ds, idxs, path)
'No images to show :)'
Flag photos for deletion by clicking ‘Delete’. Then click ‘Next Batch’ to delete flagged photos and keep the rest in that row. ImageCleaner will show you a new row of images until there are no more to show. In this case, the widget will show you images until there are none left from top_losses.ImageCleaner(ds, idxs)
找出相似图片的图片数据和序号
找出相似图片的图片数据和序号
You can also find duplicates in your dataset and delete them! To do this, you need to run .from_similars to get the potential duplicates’ ids and then run ImageCleaner with duplicates=True. The API works in a similar way as with misclassified images: just choose the ones you want to delete and click ‘Next Batch’ until there are no more images left.
ds, idxs = DatasetFormatter().from_similars(learn, ds_type=DatasetType.Valid)
清除相似图片
清除相似图片
ImageCleaner(ds, idxs, path, duplicates=True)
'No images to show :)'
记住用新生成的CSV来生成DataBunch(不含清除的图片)
记住用新生成的CSV来生成DataBunch(不含清除的图片)
Remember to recreate your ImageDataBunch from your cleaned.csv to include the changes you made in your data!
Putting your model in production 创建网页 APP
为量产生成模型包
为量产生成模型包
First thing first, let’s export the content of our Learner object for production:
learn.export()
This will create a file named ‘export.pkl’ in the directory where we were working that contains everything we need to deploy our model (the model, the weights but also some metadata like the classes or the transforms/normalization used).
使用CPU来运行模型
使用CPU来运行模型
You probably want to use CPU for inference, except at massive scale (and you almost certainly don’t need to train in real-time). If you don’t have a GPU that happens automatically. You can test your model on CPU like so:
defaults.device = torch.device('cpu')
打开一张图片
打开一张图片
img = open_image(path/'black'/'00000021.jpg')
img

如何将export.pkl生成模型
如何将export.pkl生成模型
We create our Learner in production enviromnent like this, jsut make sure that path contains the file ‘export.pkl’ from before.
learn = load_learner(path)
如何用模型来预测(生成预测类别,类别序号,预测值)
如何用模型来预测(生成预测类别,类别序号,预测值)
pred_class,pred_idx,outputs = learn.predict(img)
pred_class
Category black
Starlette核心代码
Starlette核心代码
So you might create a route something like this (thanks to Simon Willison for the structure of this code):
@app.route("/classify-url", methods=["GET"])
async def classify_url(request):
bytes = await get_bytes(request.query_params["url"])
img = open_image(BytesIO(bytes))
_,_,losses = learner.predict(img)
return JSONResponse({
"predictions": sorted(
zip(cat_learner.data.classes, map(float, losses)),
key=lambda p: p[1],
reverse=True
)
})
(This example is for the Starlette web app toolkit.)
Things that can go wrong
多数时候我们仅需要调试epochs和学习率
多数时候我们仅需要调试epochs和学习率
- Most of the time things will train fine with the defaults
- There’s not much you really need to tune (despite what you’ve heard!)
- Most likely are
- Learning rate
- Number of epochs
学习率过高会怎样
学习率过高会怎样
Learning rate (LR) too high
learn = create_cnn(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(1, max_lr=0.5)
Total time: 00:13
epoch train_loss valid_loss error_rate
1 12.220007 1144188288.000000 0.765957 (00:13)
学习率过低会怎样
学习率过低会怎样
Learning rate (LR) too low
learn = create_cnn(data, models.resnet34, metrics=error_rate)
Previously we had this result:
Total time: 00:57
epoch train_loss valid_loss error_rate
1 1.030236 0.179226 0.028369 (00:14)
2 0.561508 0.055464 0.014184 (00:13)
3 0.396103 0.053801 0.014184 (00:13)
4 0.316883 0.050197 0.021277 (00:15)
learn.fit_one_cycle(5, max_lr=1e-5)
Total time: 01:07
epoch train_loss valid_loss error_rate
1 1.349151 1.062807 0.609929 (00:13)
2 1.373262 1.045115 0.546099 (00:13)
3 1.346169 1.006288 0.468085 (00:13)
4 1.334486 0.978713 0.453901 (00:13)
5 1.320978 0.978108 0.446809 (00:13)
learn.recorder.plot_losses()
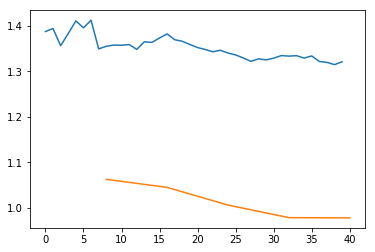
As well as taking a really long time, it’s getting too many looks at each image, so may overfit.
训练太少会怎样
训练太少会怎样
Too few epochs
learn = create_cnn(data, models.resnet34, metrics=error_rate, pretrained=False)
learn.fit_one_cycle(1)
Total time: 00:14
epoch train_loss valid_loss error_rate
1 0.602823 0.119616 0.049645 (00:14)
训练太多会怎样
训练太多会怎样
Too many epochs
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.9, bs=32,
ds_tfms=get_transforms(do_flip=False, max_rotate=0, max_zoom=1, max_lighting=0, max_warp=0
),size=224, num_workers=4).normalize(imagenet_stats)
learn = create_cnn(data, models.resnet50, metrics=error_rate, ps=0, wd=0)
learn.unfreeze()
learn.fit_one_cycle(40, slice(1e-6,1e-4))
Total time: 06:39
epoch train_loss valid_loss error_rate
1 1.513021 1.041628 0.507326 (00:13)
2 1.290093 0.994758 0.443223 (00:09)
3 1.185764 0.936145 0.410256 (00:09)
4 1.117229 0.838402 0.322344 (00:09)
5 1.022635 0.734872 0.252747 (00:09)
6 0.951374 0.627288 0.192308 (00:10)
7 0.916111 0.558621 0.184982 (00:09)
8 0.839068 0.503755 0.177656 (00:09)
9 0.749610 0.433475 0.144689 (00:09)
10 0.678583 0.367560 0.124542 (00:09)
11 0.615280 0.327029 0.100733 (00:10)
12 0.558776 0.298989 0.095238 (00:09)
13 0.518109 0.266998 0.084249 (00:09)
14 0.476290 0.257858 0.084249 (00:09)
15 0.436865 0.227299 0.067766 (00:09)
16 0.457189 0.236593 0.078755 (00:10)
17 0.420905 0.240185 0.080586 (00:10)
18 0.395686 0.255465 0.082418 (00:09)
19 0.373232 0.263469 0.080586 (00:09)
20 0.348988 0.258300 0.080586 (00:10)
21 0.324616 0.261346 0.080586 (00:09)
22 0.311310 0.236431 0.071429 (00:09)
23 0.328342 0.245841 0.069597 (00:10)
24 0.306411 0.235111 0.064103 (00:10)
25 0.289134 0.227465 0.069597 (00:09)
26 0.284814 0.226022 0.064103 (00:09)
27 0.268398 0.222791 0.067766 (00:09)
28 0.255431 0.227751 0.073260 (00:10)
29 0.240742 0.235949 0.071429 (00:09)
30 0.227140 0.225221 0.075092 (00:09)
31 0.213877 0.214789 0.069597 (00:09)
32 0.201631 0.209382 0.062271 (00:10)
33 0.189988 0.210684 0.065934 (00:09)
34 0.181293 0.214666 0.073260 (00:09)
35 0.184095 0.222575 0.073260 (00:09)
36 0.194615 0.229198 0.076923 (00:10)
37 0.186165 0.218206 0.075092 (00:09)
38 0.176623 0.207198 0.062271 (00:10)
39 0.166854 0.207256 0.065934 (00:10)
40 0.162692 0.206044 0.062271 (00:09)
1 Like
Lesson 3 multi-label and segmentation
介绍吴恩达和fastai机器学习课程
Intro Andrew Ng and Fastai ML courses
Intro Andrew Ng and Fastai ML courses
- what special about fastai ML course?
- why should take both Ng and fastai ML courses?
用Zeit实现Web App
Deploy your model on Zeit
Deploy your model on Zeit
- just a page instruction
- free and easy
学员第二周项目展示
Student Projects deployed online
3:30-9:20
Student Projects deployed online 170-418
- what car is that by Edward Ross
- build the app help understand the model better
- no need to use mobile NN api
- Healthy or Not!
- [image:104C2ABE-D1CF-440B-A38B-6BE5569D516B-86291-000381CF60EFD424/26B26097-13E0-4526-95CD-64EBD0D52680.png]
- Trinidad and Tobago Hummingbird classifier
- [image:ADB4E47E-BFF5-4065-9471-E6AAE95CF2B8-86291-000381DF9FE0D786/2A47E6C9-ABAB-4FD9-B329-02DDE21DBD83.png]
- Check your mushroom
- [image:A2CAB546-E926-4BEF-B0FE-A97CA8C59C8E-86291-000381EE4799B078/0866584B-7A59-49B8-9718-CA9CC3D1881E.png]
- cousin classifier
- [image:0A3510E0-A979-43EE-A560-AFD9E5D0CD98-86291-000381F869D4F914/CFBB57C7-1ED6-4D19-9D63-2DD2A480C3BD.png]
- emotion detector and classifier
- [image:CDC2A15D-C402-4533-A51C-A572060A2AD6-86291-000382017E9B9B81/9AF78E81-7344-49B1-894A-F81033F7BFD6.png]
- sign language detector
- [image:29705796-EDB2-4EA3-B67F-34E1A272AD0B-86291-0003820E0154E0B5/3106750F-8A8D-4414-9910-780AB4DE4411.png]
- your city detector
- [image:ACB64105-9676-4D10-A7ED-A3CA094E4462-86291-0003821CB4217822/D18076AA-FA7F-4F10-A674-CA84BA810373.png]
- time series classification
- [image:877696BC-C47D-4AB7-AE0D-05205B9BCA85-86291-00038228FFA7EFC0/4738255D-E810-4830-84C7-D34109F22E69.png]
- facial emotion classification
- [image:1647B963-2CAC-406D-8EA5-B8C8E41431D8-86291-00038355D164F364/F9A95BBA-6683-4E15-8757-A798FC5258A0.png]
- tumor sequencing
- [image:D0B6EDB8-9781-4C0E-BE11-AE5E9CF49EDA-86291-0003835CAE96793E/6E587C7F-FD7C-43E8-B06F-EDE585B8007C.png]
- [Face Expression Recognition with fastai v1 – Pierre Guillou – Medium](https://medium.com/@pierre_guillou/face-expression-recognition-with-fastai-v1-dc4cf6b141a3)
介绍卫星图片集
Introduction to Satellite Imaging dataset
Introduction to Satellite Imaging dataset 9:20-11:02 418-500
9:20-11:02
- check out the image examples and labels
- what is multi-label classification?
如何下载kaggle 数据集
how to download dataset from Kaggle
11:00-14:56
How to download dataset from Kaggle
- What is Kaggle and why it is good?
- How to download dataset from Kaggle?
- How to comment, reverse comment?
- use the notebook to guide the process of downloading
- how to download with 7zip format?
- how to unzip 7zip file?
介绍data block api
Introduction to data block API
14:56-18:28
Introduction to data block API
- Note the dataset is images with multiple labels
- how to read csv with pandas?
- what data object we use for modeling?
- previously what was the trickiest step of deep learning?
- how to create more flexible ways to create your DataBunch, instead of factory method?
- What is data block api and how does it work in general?
介绍 Dataset, DataLoader, DataBunch
Introduction to Dataset, DataLoader, DataBunch
18:30-24:00
Introduction to Dataset, DataLoader, DataBunch
- What is Dataset class?
- what does __getitem__ and __len__ do?
- How to use DataLoader to handle mini-batch?
- How to validate model with DataBunch?
- How to link all the above together through data block api?
用api Nb学习data block 用法
Explore data block api notebook
Explore data block api notebook
24:00-30:20
- use data block api notebook to play with the functions and tiny version of dataset
- a lot of skills to dig into (a lot of questions can be further created)
如何做transformation
How to do transforms
30:11-33:50
How to do transforms
- when and how to pick on flip_vert?
- how to experiment to find out the best values for other parameters?
- what does max_warp do?
- when and how to use it for different dataset?
- building a model procedure is the same as usual
如何设计你的metrics
How to create your own version of metrics
How to create your own version of metrics
30:11-41:08
* what does we use metrics for?
* how to create the accuracy required by Kaggle?
* how does accuracy in fastai source code?
* what does data.c mean?
* why a threshold is needed for satellite dataset accuracy?
* how to create a special version of an accuracy function with specific arg values using partial?
问答:纠错数据,api风格,视频截取
QA on corrected data, data api style, video frames
QA on corrected data, data api style, video frames
42-48:56
* should we record the error from app?
* how to do finetuning with the corrected dataset?
* how we set the learning rate with the corrected dataset?
* should data block api be in certain order?
* where does the idea of data block come from?
* how to dig into the details of data block source code?
* what software to pull frames? (web api, opencv)
如何读取学习率作图
How to pick learning rate carefully?
48:37-50:27
How to pick learning rate carefully
* How to read the lr for fine-tuning?
* How to read the lr for full training?
* What is discriminative learning rate?
如何改进卫星图模型
How to further improve Satellite Imaging model performance
How to further improve CamVid model performance
50:27-56:32
why use smaller images than Kaggle provided for training?
why then larger images to train the model again can avoid overfitting and improve model?
How do we make use the larger images and train model?
- how to change the data with large images?
- how to put the new data into the learner previously trained?
- how to freeze most of the layers of the model and only train the last few layers?
- how to find the best learning rate?
- how to train the model 5 times?
- evetually we move up to top 10%
- How to further improve the performance?
- how to unfreeze to train all the layers?
- how to pick the learning rate to train properly?
- to get into top 20
How to actually do Kaggle competition?
介绍camvid数据集
Introducing Camvid dataset
56:24-60:25
Introducing Camvid dataset
* what kind of problem is segmentation?
* What kind of dataset needed for segmentation?
* What industries have such segmentation problems?
* How to cite the datasets to get them credits?
问答:如何解读合适的学习率
QA How to find a specific lr number or range
60:23-63:06
QA How to find a specific lr number or range
- still a bit more artisanal than expected
- require certain experiment
- bottom point value not good
- try numbers x10 smaller and a few more around
- maybe someone will create an auto learning rate finder
如何做图片区域隔离
How to do segmentation modeling
63:06-69:50
How to do segmentation modeling
- How to get data?
- How to take a look at the data?
- how to extract labels for the data?
- How to open image and segmentation image?
- how to create DataBunch and how to set validation dataset?
- how to pick and use classes names?
- how to do transformation for Camvid dataset?
- how to choose batch size?
- how convenient to do show batch for Camvid dataset?
- How to create a learner
- how to find the learning rate
- how to start training, unfreeze and train more
问答:无监督学习和不同图片尺寸训练
QA unsupervised learning and different sized dataset training
69:55-72:32
QA unsupervised learning and different sized dataset training
* can we do unsupervised learning do segmentation?
* cons of unsupervised learning for segmentation
* should we make smaller size dataset to do training?
* great idea and great trick to improve you model
问答:像素隔离所需的准确度算法
QA what kind of accuracy do we use for pixel segmentation?
72:35-75:03
what kind of accuracy do we use for pixel segmentation
why we use acc_camvid rather than accuracy?
what are void pixels?
what are the basic skills you need to create such metrics?
问答:当训练损失值高于验证损失值时怎么办
QA what to do when training loss higher than validation loss?
75:03-76:21
QA what to do when training loss higher than validation loss
- what to do?
- training longer
- train the last bit with lower learning rate
- decease regularization
- data augmentation
- what to learn about regularization in coming weeks?
为什么以及如何创建U-net来做隔离问题
Why and how to create a U-net for segmentation?
76:21-78:52
Why and how to create a U-net for segmentation
* what does a U-net look like?
* how a medical DL paper contribute to DL in general?
* U-net is the best option for segmentation so far
* What is the usual factory procedure for building and training segmentation model?
什么是one-cycle-learning
What is the trick of one cycle learning?
78:52-86:22
What is the trick of one cycle learning
* How to plot the loss during training and validation?
* Why loss go up a bit and then go down?
* why it is a good idea to start low and push lr up and push it down?
* how to explain it through visualization?
* too small or large is bad
* you want lr to decrease as it is converging
* what does the loss space look like?
* what is learning rate annealing?
* what is leslie Smith’s contribution in one cycle learning?
* How Smith see the loss space in general?
* What is Smith’s learning rate strategy to explore the space much more quickly and efficiently?
* How to get yourself to be an experimentalist?
如何使用更大的图片来进一步训练模型
how to get full image size to train the previous trained model
86:22-90:56
how to get full image size to train the previous trained model
* how to get full image size to train the previous trained model?
* how to show result for segmentation model?
* how good is our model compared to the state of art?
* how big deal with U-net and one-cycle-learning from this example?
什么是mixed precision training
What is mixed precision training for memory limit?
90:56-94:01
What is mixed precision training for memory limit
* what does to_fp16 mean? and how to use it?
* what the hardware requirement is?
* why it is so fast and easy with GPU?
* how good is its performance?
介绍BIWI数据集
Introduction to BIWI dataset
94:01-97:20
Introduction to BIWI dataset
What does this dataset problem do?
How to use the provided functions and methods to calculate the coordinates for dot on the face?
what is the interesting point about the ImagePoints?
what kind of problem is it? (classification or regression)
如何将BIWI数据做成DataBunch
how to prepare BIWI data into DataBunch?
97:20-99:14
how to prepare BIWI data into DataBunch
* how to pick validation set?
* how to set the labels?
* how to do transformation?
如何用CNN做回归问题
How to train CNN for regression
99:14-101:11
How to train CNN for regression
* how to choose a model
* how to choose a loss
* how to find the lr?
* how to fit and save model
* how to check the result
介绍IMDB数据集
Introduction to IMDB dataset
101:08-106:52
Introduction to IMDB dataset
* How to classify document
* which submodule of fastai to use
* introduction to IMDB dataset
* how to create DataBunch quickly?
* how to create it step by step?
- what is tokenization?
- what is numericalization?
- how to do all these steps with data block api?
- What is a language model?
- How to train a learner and save the model
- there is a fastai paper on this model
深度学习理论有多么简单
How simple DL theory is
108:40-116:45
How simple DL theory is
* why NN is all about matrix multiplication?
* what is nonlinear activation?
* what were the popular activations?
* what is ReLU, as the current popular activation?
* how come matrix multiplication + nonlinear + stack together = deep NN?
* what is universal approximation theorem?
* BP is used to find parameter values
* people can’t accept DL theory is so simple
问答:tokenization如何处理San Francisco
QA how tokenization work on things like San Francisco?
116:45-119:10
QA how tokenization work on things like San Francisco
* what did the old way do (Bigram, N-gram)?
* what does NN do with tokens? (how words work together)
问答:4个channel的图片怎么处理?
QA how to deal with images with four channels
119:08-121:23
how to deal with images with four channels
* plan to incorporate into fastai library
* what if you only got 2 channels?
* what if you have 4 channels?
总结
summary of lesson 3
121:23-end
- a single workflow to solve different kinds of problems
- data block api is not big and you are free to add your own
summary of lesson 3
NLP, Tabular Data, Recsys
课程计划与展望
lesson plan and forward
lesson plan and forward
::keywords::
classification, image regression, localization, tabular data, collaborative filtering, NLP transfer learning, U-turn, math
::key questions::
* What we learnt before lesson 4?
* What’s our focus (NLP transfer learning, and collaborative filtering) in lesson 4?
* What’s the math behind collaborative filtering?
* How to take a U-turn to dive into previous learnt applications behind the scene?
fastai在camvid数据集的战绩
fastai model beat state of art in camvid dataset
fastai model beat state of art in camvid dataset
::keywords::
The one hundred layers tiramisu (paper), camvid, state of art, smaller subset of classes, 94% > 91%, default setting
::key questions::
* How good is fastai model on camvid dataset?
* What is the fair comparison between different models on camvid dataset?
* How much can a default fastai model do these days?
NLP问题与神经网络解决方案
NLP problems and neural nets approach
NLP problems and neural nets approach
::Key words::
NLP transfer learning, IMDB dataset, Legal text classifier, Wikitext dataset,
::Key questions::
- What are the applications of NLP?
- Why it is difficult to use neuralnet to NLP classification?
- Why and how we say there isn’t enough information to learn?
- What is the nature or core of neural nets or deep learning?
- Why transfer learning is always the trick to go?
- How come Jeremy think of trying it then he can actually try it out, as if no one else thought of it and tried it? (I thought of it, but I didn’t know how to try it out)
如何将迁移学习用于NLP
How to do NLP transfer learning?
How to do NLP transfer learning?
::keywords::
Wikitext, language model, IMDB, classifier, finetune, target corpus,
::key questions::
* What is a language model? what can it do?
* What is the difference between language model from Wikitext and IMDB?
* How so that to train a movie review classifier is to train with wikitext first, and finetune with IMDB dataset, and finally train the classifier with positive/negative dataset?
* Can language model learn some abbreviation expressions? think of language model generate math papers like output
* What is swiftkey’s language model in your phone?
* what exactly has been learnt from a language model trained with wikipedia dataset?
实验IMDB数据集和NLP的基本操作步骤
Experiment the IMDB sample and NLP basic procedure
Experiment the IMDB sample and NLP basic procedure 14:00-19:44
::key questions::
* How to experiment on the IMDB sample from csv file?
* What is token, numericalization?
* How to access the vocab?
* What is the default number of vocabulary?
* What is the threshold number of appearance to keep/throw the word?
* How to turn dataset from csv file into a DataBunch with data block api?
* But how to put the original IMDB dataset into DataBunch? (it is not in csv file anymore)
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.text import *
path = untar_data(URLs.IMDB_SAMPLE)
path.ls()
df = pd.read_csv(path/'texts.csv')
df.head()
df['text'][1]
data_lm = TextDataBunch.from_csv(path, 'texts.csv')
data_lm.save()
data = TextDataBunch.load(path)
data.show_batch()
data.vocab.itos[:10]
data.train_ds[0][0]
data.train_ds[0][0].data[:10]
data = (TextList.from_csv(path, 'texts.csv', cols='text')
.split_from_df(col=2)
.label_from_df(cols=0)
.databunch())
如何训练IMDB语言模型
How to train IMDB language model?
How to train IMDB language model?
::key questions::
* what if you got a huge medical dataset no smaller than wikitext dataset?
* why we can use test set to train our language model?
* what does label language model mean?
* how to create a language model learner with RNN?
* what is dropout in terms of regularization?
* what is moms in fit-one-cycle?
* what does the model predict do? and how to do it?
* what does encoder do? and how to just save encoder as the model?
如何训练语言模型来做分类
How to train a language model for classification
How to train a language model for classification
time 27:13-33:12
::key questions::
* How to create the DataBunch to train the language classifier?
* why use vocab?
* How to manage the batch_size given the size of GPU memory card?
* What does the time spent look like on the second model and many classifier models?
* How to freeze up to specific number of layers?
* What is moms or momentum parameter for?
* How exactly do Jeremy figure out the best hyper-parameter value such as moms to automate?
如何用random forest来寻找最优学习率
How to find the best parameter value for learning rate using random forest
How to find the best parameter value for learning rate using random forest
time: 33:12-36:47
- Where does 2.6**4 come from?
[image:DAF31EAD-5DA5-4FD9-82A3-2299FF5EA1B0-11295-0002318019A7FB44/C9F72A37-9B3B-45A1-9D75-49539C461B27.png]
* How to use random forest search for the best hyper-parameter value?
* what is all about auto-ML? build models to how to train your model
* but we are fond of building models to better understand how your hyper-parameters work
如何用深度学习来做表格数据问题
How to do tabular data with deep learning
How to do tabular data deep learning
time: 36:31 - 53:09
* What are the problems with tabular data?
* How people first reacted to deep learning in tabular data problem?
* How such wrong reaction has been changed?
* Why and how (feature engineering and Pinterest conference) deep learning become powerful and useful in dealing with tabular data?
* What is Jeremy’s top options for tabular data problem? (DL, RF, GBoost?)
* What are the reasons why DL for tabular data not widely used? (library)
* Why fastai use pandas a lot for tabular data?
* What are the 10% cases in which DL is not the default approach?
* Why do we use URLs.ADULT_SAMPLE dataset?
* How to make tabular DataBunch from dataframe?
* What are dep_var, cat_names, cont_names and procs?
* How to deal with categorical variables inside tabular data in DL models? (embeddings) How about continuous variables?
* What are the differences between processor and transform? (once ahead of time vs every time sending in model)
* What does FillMissing, Categorify, Normalize do?
* Why do we split valid with split_by_idx to have connected sub dataset for validation?
* How to build tabular model with get_tabular_learner? what does parameter layers=[200,100] do?
* How to combine NLP data with metadata (tabular data) and let DL to apply to them?
* Will sklearn and XGBoost go outdated?
* What does metrics do?
如何将深度学习应用到collaborative filltering问题
How to apply DL to collaborative filtering
How to apply DL to collaborative filtering
53:09-67:24
* What kind of problems do we apply Collab filtering?
* What is the data structure like? (user, movie, rating two styles representing)
* What is the pros and cons of the sparse matrix style?
* What if you want to learn to deal with large sparse matrix storage problem? (Rachel’s computation LA course)
* What is GroupLense dataset about?
* How to experiment with the dataset using Collab filtering?
* How to create a collaborative filtering model?
* Why using Collab filtering was difficult?
* What is Cold stack problem?
* How Netflix fix the Cold stack problem?
* What is the other solution (predictive model) to cold stack problem?
* How to make language model learn to use emoji’s?
* How to deal with time series tabular data with DL? (extract and add more columns, not use RNN)
* Is there a source to learn more of Cold stack problem?
如何用excel帮助理解colaborative filtering的数据集和模型
How to understand dataset and models with excel
How to understand dataset and models with excel
time: 67:23-77:11
* How to visualize collaborative filtering process with excel?
* How to create weights for users and weights for movies?
* How to do gradient descent with solver?
用Vim来探索collab embedding的源代码
Explore collab embedding with VIM
Code Browsing - YouTube
Explore collab embedding with VIM
VIM Adventures
Timesavers: Bash kernel for Jupyter notebooks & ctag Vim navigation
77:07-92:28
How to use VIM to explore source code quickly?
What is embedding and how it is created?
总结
Explain deep learning process up to output layer
Explain deep learning process up to output layer
92:11 - end
* what is the deep learning workflow?
* what is input layer, hidden layers, output?
* what are parameters, weights?
* what are activations?
* How much linear algebra we need to do deep learning?
第五课:反向传递与手写神经网络
本课框架
lesson 5 outline
lesson 5 outline
0:00-3:30
* downhill into details behind the scene
* why start with machine vision?
* why we finish with tabular data and collaborative filtering?
* how this lesson is structured by starting with the latest notebook?
* regularization is the key in this lesson and will help improve your models
对深度学习原理和反向传递的回顾
review the workflow of deep learning and backprop
3:20-8:30
review the workflow of deep learning and backprop
* How to understand the Layers of parameters and activations
* how to update parameters
* how to get activations with parameters
* Inputs are special kind of activations
* original inputs
* inputs created by element-wise function with activations, Relu
* Relu works all the time
* What is Universal Approximation theorem
* parameter matrix product with input
* activations with relu to get input features
* stack many and large enough of weight matrices together to solve any function to any level of accuracy
* This is all the trick you need about DL for CS
* What is bp?
* name sounds impressive, but
* in fact = prediction + target -> loss -> gradient -> update parameters by - lr*gradient
如何理解迁移学习的微调训练
How to understand fine-tuning with ImageNet on new classifiers
8:30-19:51
How to understand fine-tuning with ImageNet on new classifiers
what exactly does Resnet classifier do behind the scene?
how to change ResNet’s last second matrix of 1000 category to suit your classes need?
What are the other/remaining hidden layers good at?
- as layers go up, features become more complex
- you want earlier layers weights stay where they are
- so we want them frozen
What does freeze do to the model?
- don’t backpropagate those frozen layers
- model run faster
- earlier layers’ weights stay the same
After a while, we want to train the rest of network, how to do that?
- unfreeze the layers
- earlier layers need almost no update, refer to very small learning rate
- middle layers need slight higher learning rate to have a little more update
- later layers need larger learning rate to update even more
- this process is called “discriminative learning rate”
How to do discriminative learning rate with fastai?
- fit(1, 1e-3)
- fit(1, slice(1e-3)), middle layer rate/3
- fit(1, slice(1e-5, 1e-3)), spread reasonably
- different learning rate for each layer group
为什么N-embedding比one-hot encoding更优
why is N-embedding better than one-hot encoding
19:50-36:00
why is N-embedding better than one-hot encoding
What is Affine function?
- sort of matrix multiplications
- CNN: weights are tied, so affine function is more accurate
- most common in DL
How to use one-hot encoding as input
- 15 users one-hot encoding as user input
- 15 movie one-hot encoding as movie input
How to understand one-hot encoding vs N-embedding
- conventionally, user weights(embedding) do matrix multiplication with user input (one-hot encoding)
- output is activation, which actually is the same to user weights (embedding)
- activations are actually the same to user embedding
- or equal to user embedding with array lookup (computationally easy)
What does it mean that user embeddings corresponds to user idx (same to movie)?
- when movie and user embedding matrix multiplication output (activation) is high, it means
- user embedding features corresponds to movie embedding features
- they are referring to the same features in their own corresponding embedding values
- user’s features = personal tastes, corresponds to/matches to movie’s features
- these underlying features are latent factor or latent features
How to deal with bad movies even though there are good features inside?
- solution is to add bias (for both user and movie)
- use user bias to represent user rating behavior
- use movie bias to represent movie overall quality
- so, bias is important, this is why by default all NN add bias to train
问答:训练次数与Affine函数
questions on epoch and affine function
questions on epoch and affine function
36:06-38:21
* When we load a pretrained model, can we reload activations to say what they are good at?
* yes
* What is Affine function?
* linear function
* multiplication + add up = affine function
* affine function (affine function) = affine function
* affine + relu + affine + relu …. = deep neural net
用collaborative filtering来解决电影用户预测问题
run full movie lens dataset with collaborative filtering
run full movie lens dataset with collaborative filtering
38:21- 48:02
- Introduction to Movielens dataset and how to pick the dataset
- How to open and check the dataset with pandas
- What does encoding="latin-1" do?
- nowadays standards is unicode
- old style is latin-1
- what about the genre of movie in the dataset?
- how to use merge function to bring title into the table?
- how to create a CollabDataBunch and set specific column to be the movie or item column?
- what about the trick of setting the y-range to improve performance?
- first use sigmoid to move values into [0, 1]
- better, to move [0,1] to [0, 5.5] make sure the largest rate can be 5
- What are n_factors (latent factors)?
- matrix factorization
- the width of embedding matrix
- tried a number of values, 40 works the best so far
- How to pick the lr from lr plotting?
- paper author’s method
- find the lowest value
- then go back by x10
- Jeremy method method
- find the sharpest decline
- go back and forward by x10
- see which one works better
- go to LibRec to compare your result with the benchmarks
如何解读用户和电影对应的参数
How to interpret the weights or parameters of users and movies
48:00-61:00
How to interpret the weights or parameters of users and movies
- What interesting inside the latent factors (embeddings)?
- How to deal with Anime fans who just love anime and rate very high, so you see many episodes of anime stay the top 100 over the top 1000 movies?
- this kind of features are captured by bias
- it is interesting to check out bias vector of all movies
- how to use pandas to find the movies being rated the most?
- to find movies we might have seen hopefully
- How to access model’s item/movie bias?
- it is a vector of course
- how to group mean_ratins , bias and movie title together?
- then, how to sort them by bias values
- to compare bias value and rating numbers
- How to squish the 40 latent factors into 3 factors?
- how to use pca?
- Rachel teaches PCA from a different course
- How to use PCA to compare image similarities?
- How to group PCA latent factors with movie titles
- and sort by different factors
- how to interpret
- How to plot the movie by factors
如何解读collaborative learner的源代码
How to read source code of collaborative learner
How to read source code of collaborative learner
- just watch Jeremy explore it a lot more times
- dive deeper with vim
- dive deeper with ipdb
61:00-66:57
如何解读embeddings
Interpreting embeddings
66:57-72:27
Interpreting embeddings
What is the big deal about entity embeddings?
- a Kaggle dataset with 2016 paper with entity embeddings
- how it work with different models?
What is the interesting founding from plotting the embedding?
- embedding projection discovered geography
- clear path between weekday and month of a year
- Embedding is under researched
- interesting to see pre-trained models’ embeddings
什么是weight decay
what is weight decay
72:20-79:35
what is weight decay
- weight decay is a kind of regularization
- how to understand regularization with Ng’s graph?
- what is under and over fitting?
- what is the lie taught in social statistics courses?
- too many parameters cause overfitting
- complexity depend on number parameters
- How to balance complexity and parameters number?
- real life is full of complexity, curve lines, more nonlinearity, many parameters
- but no more curvy than necessary
- but how to avoid overfitting at the same time?
- how to penalize complexity?
- use a lot of parameters but penalize complexity
- one way: sum up value of parameters(not really), sum up the square of parameter values
- all such value to loss
- what problem can it be?
- good loss require sum of squared parameters to be zero
- solution: multiply wd to the sum of squares of parameters
- generally, wd = 0.01, but here we use 0.1
- wd too small, model is easy to overfit, so can’t train too long
- what is the difference on using kwarg between collab_learner and learner?
- how to pass on or add additional args, such as wd
如何手写SGD与weight decay
How to write SGD with weight decay from scratch?
79:35-102:50
How to write SGD with weight decay from scratch
- how to implement SGD from scratch? (review)
- what is loss from scratch, such as MSE?
- how to move from loss to loss with weight decay?
- How to use MNIST dataset pickle file for experiment
- How to use Pytorch to create DataLoader, loss and Affine function?
- How to access a batch of dataset? (why always use DataBunch)
- Make sure you can do subModule
- What does nn.Linear do? do the same to Mnist_logistic
- how to create a model out of the submodule you create?
- what does model.parameters() do?
- why use crossEntropy rather than MSE?
- How to implement update with weight_decay?
- how to write w2 sum squared of parameters?
- what to access all the parameters for update?
- how to write loss with weight decay?
- what does loss.item() mean?
- why we need reduce learning rate as we train the model further?
- see the plotting of loss
- why we call w2*wd weight decay?
- linear algebra transformation outcome show wd*w
- without this transformation, we call it L2 regularization
- later they become different some how
- How to further refactor the code Mnist_NN
- How to do all the above with less code using Pytorch functions?
什么是Adam优化算法
What is Adam optimization
102:50-120:00
What is Adam optimization
* what is SGD in excel?
* what is momentum in excel?
* v = v_{t-1}*0.9 + g*0.1
* w = w_{t-1} - lr*v
* so momentum is gradients momentum, not weights
* what is the intuition of momentum on graph
* weighted gradient
* ::one more step by inertia, maybe we see the world better::
* how to do SGD with momentum in pytorch
* what is RMSProp in excel?
* where is the first citation of this method
* v = v_{t-1}*0.9 + 0.1*g^2 ->
* if gradient is consistently small, v will be small
* if gradient is volatile, v will be large
* if gradient is consistently large, v will be large
* w = w_{t-1} - g_{t-1}*lr/sqrt(v_{t-1}) ->
* if previous momentum of gradient is very small, let’s update weight in bigger steps
* vice versa
* ::make a change the previous lasting state, maybe we see the world better::
* learning rate is still necessary
* what is Adam in excel?
* adding momentum and RMSProp together
* w = w_{t-1} - lr*v_momentum/sqrt(v_rmsp)
* Deep dive into the excel sheet
* Deep Dive: An overview of gradient descent optimization algorithms
什么是fit-one-cycle
What is fit-one-cycle
120:00-123:30
What is fit-one-cycle
- fastai takes care of the optimization details for us
- what does fit-one-cycledo?
- make learning rate start low
- as we know very little of the world
- go up about half of the time
- knows the world better, direction is correct
- then go down about half of the time
- finetune to get closer to convergence
- right : momentum graph
- when steps are small and momentum is accumulating, suggest we can just make big steps
- when steps are big, momentum is small, suggesting we change flexibly
- when steps are getting smaller, the momentum is increasing, we can make big steps again
- make it super fast convergence
- an inspiring story
什么是cross-entropy loss
What is cross-entropy loss?
123:30-end
What is cross-entropy loss
Introduction to the toy dataset
what is the intuition of cross-entropy loss in excel
what is intuition of softmax in excel
- single label multiple classification
How pytorch does them both for us?
- nn.CrossEntropyLoss has both loss functions above inside
what pytorch multiple class classification model return to us?
- pytorch default is different from fastai default
深入学习CNN与数据科学伦理
如何使用platform.ai网站来标注图片
How to use platform.ai to label images
0:00-9:46
How to use platform.ai to label images
- How to use combine human skills with platform.ai to group or label images efficiently?
介绍Rossmann Store Sales 数据集
Getting Started with Rossmann Store Sales dataset
Getting Started with Rossmann Store Sales dataset
9:46-16:59
* How to understand Tabular learner source code?
* How to sort out Rossmann Store Sales dataset?
* Why the test set is more closer to the recent time?
* What is the loss function offered by Kaggle competition?
* Where to learn how to joint and manipulate data tables?
* Which notebook to clean rossman_data to generate pickle file?
* What does add_datepart do?
* Why it is useful to turn date into metadata columns?
如何预处理数据集
How to preprocess the dataset before DataBunch
How to preprocess the dataset
16:54-22:26
- What is transform and what transforms are good at?
- What is preprocess and how to use it?
- How to graph a small subset of data to experiment with?
- How to categorify for tabular dataset?
- what does categorify mean and what the output look like?
- What does NaN and -1 mean?
- Why we can’t use -1? and How we deal with -1 here?
- How to use FillMissing to fill the missing value with median values?
- How does fastai do all these preprocessing automatically or easily together?
如何对Rossmann数据集生成DataBunch
How to create DataBunch for Rossmann dataset?
22:26-27:14
How to create DataBunch for Rossmann dataset
- how to provide column names for all variables?
- how to determine validation set using test set from Kaggle?
- why make sure label_cls to be FloatList not IntList?
- Why use log=true for FloatList to use RMSPE?
如何用tabular模型来解决Rossmann数据集问题
How to build tabular model for Rossmann dataset?
How to build tabular model for Rossmann dataset
27:14-30:04
- What to do about y_range for tabular_learner and why?
- What kind of NN structure for tabular dataset? (simple fully connected)
- What does layers=[1000, 500] suggest?
- How to use ps and emb_drop to prevent overfitting?
如何理解dropout层
How to understand and use dropout?
30:03-39:14
How to understand and use dropout
* How to understand the basic idea of dropout from the paper?
* not only hidden activations but also inputs (sometimes) to be thrown away
* why it is useful?
* to make parameters to remember patterns rather than the specific images
* where usually do new brilliant ideas come from
* not from math
* but from life and intuition
* How to choose the probability to drop out for each layer?
* a single p
* or list of p
* What to do in training and testing time?
* do we throw activations too?
* if not, how to balance with training throwing percentage?
- How to understand dropout C source code?
- How to use ps and emb_drop in coding?
- How to understand the use of emb_drop?
- just another layer’s output/activations to be dropped with probability
如何理解Tabular Learner模型中的embedding 层
How to understand embedding layers in Tabular learner?
39:14-42:25
How to understand embedding layers here
How to experiment things out to find the best hyper parameter values?
- such as the process of finding emb_drop=0.04
How to understand embeddings?
- how embedding layers corresponds to categorical input variables?
- how to read and set the embedding sizes?
- continuous input variables work not with embedding layers, but batch norm layers
什么是Batch Normalization
What is Batch normalization
42:00-48:28
What is Batch normalization
* What is Batch normalization in a sentence?
* What is interesting about the recognition story of dropout paper by major journals?
* Why batch norm paper was accepted quickly?
* Why you should understand papers and give no big deal to math jargons?
* What is the real reason why BN is so powerful?
* loss vs parameters is not as bumpy, therefore model can converge with higher lr
- what does BN algorithm actually do?
- BN is a layer to produce activations
- get mean and sd from a batch, and normalize the batch with them
- [image:C1E8B194-E4C9-4561-89B3-0AF453351EF4-76996-000338D1A2BB7D80/579DC33D-7356-4458-907E-68A08C964680.png]
- scale (coefficient param) and shift (bias param) the distribution of the batch (most important)
为什么BN中的scale, shift能产生显著功效
Why BN (scale and shift) make a difference?
48:25-52:00
Why BN (scale and shift) make a difference
* what is the problem behind the scene?
* target range 1 to 5
* prediction range -1 to 1
* it causes difficulties
* scale with alpha and shift with beta can deal with it
* to transform [-1,1] closer to [1, 5]
如何在代码中具体使用BN
How to use BN in code?
51:50-54:56
How to use BN in code
- what does momentum=0.1 mean for BatchNorm1d?
- value low = mean and sd vary less between mini-batches = less regularization
- value high = otherwise = high regularization
- it trains much faster now
如何在BN,数据增强,dropout, weight decay 和L2 norm之间选择
How to pick between BN, data augmentation, dropout, weight decay and L2 norm
54:56-56:46
How to pick between BN, data augmentation, dropout, weight decay and L2 norm
- L2 = weight decay, use weight decay
- always use BN, data augmentation
- experiment to see the combination options for dropout and weight decay
如何做数据增强
How to do data augmentation
56:45-65:24
How to do data augmentation
- Why it is Least well studied and most exciting regularization?
- no cost
- no longer to train
- no underfitting
- how to find out all about data transformation through docs
- how to pick appropriate values for brightness
- how to pick for diheral
- how about flip
- pad mode a fastai paper about it
- what is symmetric warp doing
- how to transform a single dog picture into many “different looking” images
- why data augmentation is such a big potential opportunity?
本课目标和展望
Overview and Why to understand CNN by creating a heat map in the end?
65:12-67:30
Overview and Why to understand CNN by creating a heat map in the end
* how to quickly create, train and save a CNN with fastai?
* To understand CNN by creating a heat map from scratch
如何动态可视化理解kernels的功能
How to understand kernels with Setosa’s web app?
67:27-75:05
How to understand kernels with Setosa’s web app
why study how CNN work in the end of a course?
- not useful in terms of just using them
- but if want to do it slightly differently, we need to know CNN behind the scenes
- convolution: a special matrix multiplication
How to understand CNN kernel or image kernel with Setosa’s web app?
- how the kernel transform an image?
- why there is black outer edge of the output image?
- why head area is transformed into while cells but face areas into black cells?
- How to define a convolution with this example?
- How to relate this to channel visualization with the paper?
- Why such kernel is to help find up-edges?
如何理解Convolution以及padding的用途
How to understand convolution differently and what is padding for?
75:05-80:00
How to understand convolution differently and what is padding for
* How to view convolution as standard matrix multiplication?
* transform kernel convolution movement into a single larger matrix kernel doing simple matrix multiplication with input matrix
* How to understanding padding?
* to keep the output feature map the same size as input feature map
kernels, stride, padding在CNN中是如何工作的
How kernels, stride, padding work in a real CNN?
79:55-89:39
How kernels, stride, padding work in a real CNN
what does a 3-channel kernel look like? and how does it work?
how do we find more features by adding more 3-channels kernels?
- e.g., add 16 kernels to find 16 different features
Why and How to shrink the feature map but double the kernels?
- avoid memory goes out of control by kernel skipping over one or several pixels
- feature map size shrinks, but we can add more kernels
Let’s Experiment an image with kernels, stride and padding
- create a CNN over an image
- check out its model summary, particularly its feature map size half and kernels double
如何手写你的CNN
How to do your manual CNN?
89:30-93:49
How to do your manual CNN
- how to create your own 3 channel kernel with 4D to show bottom right edge
- how to get a single image
- how to create a kernel as a 4D tensor
- how to create a mini-batch of size 1
- how to apply the kernel to an image
如何创建heat map
How to create the heat map?
93:46-109:00
How to create the heat map
- how to turn a 512x11x11 tensor into a vector of 37 values
- average pool 2d with output size 1
- linear layer with (512, 37)
- what does the finally feature map (512, 1, 1) tell us?
- what does (512, 11, 11) tell us?
- what does it mean to average cross same cell position for 512 channels rather than 11x11 grid of a single channel?
- how to use hook to get the feature map 512x11x11?
- how to run model on a single example
数据科学与伦理
Ethics and data science
Ethics and data science
109:08-end
- what are generative models?
- what are the ethics issues of data science
- what are the gender bias based on facial classifier on major DL companies
- why? what are the reasons caused such bias? (where is data source)
- how biased surveillance DL cause massive arrest?
- the best way to get publicity is to do something like “Amazon Face Recognition falsely matched black 28 members of congress with mugshots”
- google machine translation seem don’t fix the gender bias
- machine bias is overwhelming in public policy and judicious system
- Facebook and Mianmar genocide
- how should a DL engineer face ethical issues
1 Like
第七课 Resnet, U-net, GAN
本课预览
A warning of lesson 7 and a student role model to checkout
A warning of lesson 7 and a student role model to checkout
0:00-1:59
- Food classifier with fastai on Android and IOS app
- help docs, tutorials, community organizing
如何一步一步链接data block
How to do data block api step by step?
1:59-11:02
How to do data block api step by step
- how to extract images with gray scale with ImageItemList.from_folder and convert_mode?
- how to access each item from the folder path object?
- how to set the default color map for fastai?
- why fastai make each image into a rank 3 tensor rather than a 2D matrix?
- how to access an image item as file path and item as image?
- how to split training and validation sets by two folders “training” and “testing”?
- the images inside “testing” folder do has labels, not real testing data without label
- How to check what included inside training set folder?
- inside training set folder, there is a folder for each class
- how to provide labels for your training and validation sets?
- then check to see the difference from previous step
- how to access a single image example from training set with both x and y?
- how to do transforms for small image dataset recognition?
- how to do it with tuple setting for transforms?
- how to create DataBunch with normalize?
- how to access data example from DataBunch.train_ds?
- how to plot an image from data.train_ds?
- how to plot this image with different transformations?
- how to get a batch of x and y from DataBunch?
- how to show a batch of data?
如何手写CNN
How to create a CNN model from scratch
How to create a CNN model from scratch
11:00-16:54
- How to refactor nn.Conv2d for usual use?
- leaving two function inputs:
- ni: number of input channels
- nf: number of output channels
- #14 : the size of feature map 14 x 14
- How down-sampling from 7x7 to 4x4?
- 7/2=3.5 + max_ceiling = 4
- How to build a CNN model with conv and BatchNorm2d and Relu?
- [image:16EDA985-0D1A-4765-A638-A584274C1AFD-76996-00031B1524A7B3E7/31DEDE98-8C85-49DD-8BBD-805C7617B89C.png]
- How to use a single batch of data xb to double check on model built above?
- [image:30C46125-9967-4C3A-8CA4-E4D671AF1DBD-76996-00031BCD20A29908/E30127C3-CE26-42E0-AF31-531AF1DC1C19.png]
- How to refactor code further into `conv2`?
- use fastai `conv_layer` which include `conv2d`, `BatchNorm` and `Relu`
- refactor `conv_layer` into `conv2` with `stride=2`
如何手写Resnet
How to create a Resnet from scratch
16:10-31:02
How to create a Resnet from scratch
How to make the CNN deeper without shrink feature map size?
what caused a deeper CNN model to perform worse than a shallow one?
- [image:07F9441D-7B1B-42C7-AB03-511415A802C2-76996-00030C8FB1006D28/5F24E25C-4439-4077-BDE9-1F48D0CF7A30.png]
what does really good researcher do in front this kind of problem?
What is the key insight that ResNet or ResNet block offers to us? (identity/skip connection)
What the real reason for why ResNet block work so well?
- [image:4291DC80-8849-40B6-B0BA-EA852DFAB7F2-76996-00030CDE88DA86CA/CC14544A-4771-453E-B8CA-7A32D0B5DCD2.png]
How to write the ResNet block?
- [image:5FD3BB7A-9C45-44C5-9C19-339F57D213DC-76996-00030CEA99BEF92C/2D3B65A4-D464-4B14-BA1D-1259E04C3094.png]
How to build the ResNet model?
- [image:AB5244DF-26E5-4ED5-9868-41E9D041F6C6-76996-00030CFD98B63574/25A2D232-5166-4BF7-87D9-4003793E359F.png]
如何创建Resnet block和Dense block
::How to use sequentialEx and mergeLayer to create Resnet block and Dense block?::
26:18-31:36
How to use sequentialEx and mergeLayer to create Resnet block and Dense block
What are the pros and cons of Dense net?
What kind of tasks or problems does Dense net good at solving?
How does it link to U-net?
如何手动创建U-net
How to build upgraded U-net from scratch?
29:50-48:38
How to build upgraded U-net from scratch
- how much better skip/dense connection help to strengthen U-net on segmentation?
- 29:50-32:12
- What does it mean by upgrading U-net with ResNet and Deconvolution
- 32:00-36:10
* What is the wasteful way of doing deconvolution and what is the better way (nearest neighbor interpolation?
* 36:08-41:20
* how to enlarge feature maps not shrink anymore?
* [image:59E5FB01-2CFB-47DA-8085-05DD1DE7368D-76996-00031687B20EFB04/71B721CF-5FD1-494C-86BD-6149546E7D33.png]
* part2 : pixel shuffle > NN interpolation
- How to implement U-net?
- 41:20-48:31
- why simple convolution (down-sampling) + deconvolution(up-sampling) won’t work
- What kind of special skip connection does U-net have?
- skip long distance and not add but concat
- How such special skip connection enable U-net to better segmentation?
- 41:20-43:35
- What is the U-net implementation?
- 43:30-47:24
- what does a UnetBlock do and how to implement it?
- How exactly does U-net train? ::Not explained in the course::
问答:为什么要在之前做concat,以及如何用dense concat防止缩水
QA Why concat before and How to keep dense concat without shrinking
49:50-52:02
Why concat before and How to keep dense concat without shrinking
如何将低像素图片还原成高像素图片
How to make low resolution image with high resolution image
48:29-97:13
How to make low resolution image with high resolution image
什么是图片还原
What is image restoration?
48:29-49:50
What is image restoration
What are those specific applications of image restoration?
如何将原图变像素很差图
How to crappify image as low resolution?
52:04-55:12
How to crappify image as low resolution
Why to crappify image?
How did Jeremy do it? (low res and text written)
* How to open image file
* How to resize and bilinear interpolation
* How to write a text on the image
* How to save image with random quality level
[image:729A7FED-5489-478E-9D46-D06A95DE02D3-76996-0002E3F330FC7744/F7BF4E6B-D36E-4081-8005-6884400B0C9E.png]
Why not always see the text or number?
[image:16DA9837-D19A-4F7B-8796-EE82F3B0FC08-76996-0002E3F80F200E0C/685F50BB-D57C-4F3E-84A9-8BEDC654C340.png]
How to speed up with parallel?
[image:28BC542D-07E2-4ACA-82DD-26C52FFE4FE4-76996-0002E45B5374B1E2/A4868BD2-6333-44FC-B583-AE07FFF2666C.png]
How to come with your own crappification?
- this is how to make something interesting or original
Why crappify is important to models to learn?
如何训练模型来消除水印
How to train a model to remove watermarks
55:12-58:11
How to train a model to remove watermarks
Why use a U-net to train?
How to create the DataBunch?
Why need transfer learning to get rid of the text in the image?
What is a generator learner?
What does MSELossFlatdo here?
What is frozen for the U-net?
[image:846764AE-B33B-4504-8F95-CE6412299973-76996-0002E6F8C0878DB5/FDC2EBA7-29CB-4C0D-94EB-E39596FA4DCB.png]
如何用GAN来提升图片像素
How to use GAN to upgrade image resolution?
58:10-64:07
How to use GAN to upgrade image resolution
why to blame the MSE loss for current model can’t upgrade the resolution?
How GAN solves the upgrade problem with another loss function by calling another model?
How to understand all the concepts and the workflow in the diagram below?
[image:D3D36EFF-991E-4A7B-934C-276869A877A0-76996-0002F142639FB908/8E89A71B-A3FB-462A-8A96-279CC9BB7A7C.png](how loss change between different stages)
How the generator training and critic training do the ping pong game?
why it is a pain to train GAN (very slow to train especially at the beginning)?
How can pretrained both generator and discriminator to solve this problem?
如何构建和训练discriminator来区分真假图
How to build and train a discriminator to tell images and image_gen
64:07-70:10
How to build and train a discriminator to tell images and image_gen
What folders of images do we need for discriminator training?
How to generate and save prediction images into a folder?
- how to create and remove directories (trees)
- how to get all the image file names
- how to access each batch of files at a time
- how to save images with specific names in a directory
- [image:EDA6CF1C-83E8-4351-A8FF-0F144B9431B5-76996-0002F6B41F32AE5B/7A5230C9-302E-4B45-9DEC-8FE5394AAAA1.png]
Why we should start to learn write our own codes/functions?
How to use GPU memory efficiently to avoid restarting notebook?
How create DataBunch for discriminator with two classes images and image_gen?
- [image:ECD5A2F8-A1D2-4CF7-8A89-9C3495D82150-76996-0002F6AC6B981613/381EAF2C-0163-4BF1-9B31-744143C9E2D5.png]
Why do we use a specific gan_critic model architecture rather than ResNet to build discriminator?
- what kind of loss do we use here?
- what is spectral normalization to make GAN work?
- maybe we could make a ResNet with spectral normalization to replace gan_critic
- how to train the critic
- [image:C82EBF3E-0DAD-487B-96D6-0DF587286F76-76996-0002F6C426E9DFFA/D2675782-151B-4BE5-8A91-170D7C868D5F.png]
GAN是如何在generator 和 discriminator 之间反复训练的
How to use GAN to do pingpong with generator and discriminator training
70:08- 73:05
How to use GAN to do pingpong with generator and discriminator training
How to use GANLearner.from_learners to train the ping pong process?
How weights_gen combine both losses (pixel MSE and binaryEntropyLoss) together to balance generator and the critic?
Why and how to downplay momentum when use Adam?
- [image:7321EE22-B189-47AE-B7CA-EB65AEF00CED-76996-0002F93E289E4CA9/0A83E2DD-B404-41E5-A5D8-B1FE3E637856.png]
How to understand the gen_loss and disc_loss during the training? (one gets better and the other gets worse, and vice versa)
How to show the result of gan training?
- [image:C16059DC-7061-4621-ADB9-68F9CB0ADB33-76996-0002F99336D4EBFC/778D82F1-55F6-46B9-8A1B-A2FDFC96EB68.png]
问答:什么时候需要用U-net
Q&A: when use to U-net or not?
74:47-75:56
when use to U-net or not
- segmentation and high resolution
- classification make no sense
WGAN能做什么
What can WGAN do?
75:56-78:37
How can WGAN do
What does WGAN aim to do?
What does generator aim to train a noise image into?
Does WGAN use any pretrained model? NO
After hours, some bedroomish images can be produced eventually
如何用GAN来让模型学会识别猫眼
How to train GAN to pay attention to cat’s eyes
why cat’s eye features can’t be upgraded with current GAN?
73:05-74:47
How to implement feature loss paper to help
78:37-97:06
How to use the perceptual loss paper idea to solve the problem
78:37-83:49
- How exactly does the style loss and content loss help to capture eye features?
- do we really do GAN still now? (seems not)
How to implement the perceptual loss paper into FeatureLoss function?
83:52-88:54
* how to do crappification for this model?
* which the loss or base loss to pick? which loss does Jeremy like better?
* How to grab all the feature layers of pretrained VGG model?
* how to get all the layers for generating features losses?
* how to create the feature loss or perceptual loss?
How to train and test on our U-net with feature loss model?
88:54-93:25
- how to train a U-net with feature loss
- how to refactor do_fitto make the process easier a little
- how to train to improve performance
- test the model with larger images
What can we be creative with U-net + GAN + feature_loss notebook?
93:00-97
[image:3F83E9B6-CCF5-4BB7-91D3-008E50AFF678-76996-000305FCE24409DE/0AC75F18-A7C0-42EA-8410-FD9EEC5D54DB.png]
* What Jason’s crappification approach?
* What is deOldify doing?
* what should we learn and do about crappification and deOldify?
我们在第一部分里学到了些什么?
What we have learnt in part 1?
97:00-98:41
What we have learnt in part 1
How to link all the concepts below to pain a brief picture of deep learning workflow?
[image:7BE0220B-A7E5-471D-AAEF-B571901C66B6-76996-0002CD2B80C48B99/96AB3B59-287C-4127-83A6-E138EA601D64.png]
- people usually have to watch the lesson three times to get all the details and feel comfortable with those key concepts
如何在图上画出一个隐藏层的神经网络
How to represent basic NN with single hidden layer with diagram?
98:34-100:22
How to represent basic NN with single hidden layer with diagram
[image:54EB7701-8A48-4AD7-8165-97B9ECAA8B39-76996-0002CF0A4228A58B/AC0913D7-E16D-477F-B4C1-57387524EA8C.png]
- make sure you are comfortable with how to calculate the shape of the input, activations, and output
如何用全链接层模型预测第3第4个字
How to predict 3rd or 4th word with fully connected NN diagram
100:02-103:12
How to predict 3rd or 4th word with fully connected NN diagram
- How do fully connected NN use two words to predict the third?
- How then to predict the fourth word?
- why should same color parameters should be the same set of parameters?
[image:A3DB17E3-AB76-4818-A1BF-D767C7B646DE-76996-0002D85254D25DE9/BECCCC16-C799-41D3-943B-EBC449BEDA64.png] [image:2EBD0725-7D53-4292-9E85-CCD47C02242F-76996-0002D857FC4B16B9/B4551F3D-468F-4721-9A70-BCA8BF561B96.png]
如何用human numbers数据集来构建训练和验证集
RNN Toy example - how to create the training and validation sets from human numbers dataset?
103:09-109:11
Toy example - how to create the training and validation sets
- how to access the number of tokens in validation set?
- how to distinguish bs=batch_size, bptt=backpropagation through time, num_batches?
- How to get 3 batches of data from validation set one by one?
- How to count the number of elements within a batch of x or y?
- Why bptt=70 but first batch has 95 elements and second batch as 69 elements?
- How x1 and y1 differ from each other?
- How to textify numbers into words?
- How mini-batches of x join up with each other?
[image:AE5A0EB9-4737-49D4-A96D-5D7F639C6795-76996-0002D54E2D48B6B0/22BDBA2A-B966-420D-8A35-C0FD52358568.png] [image:18BC726D-3B3A-425F-A1FD-056D96B27B76-76996-0002D55B8C6BCD68/A55BC1CA-08A8-4410-A760-E044A17C636E.png]
[image:F0C85252-1AFF-453A-82C2-16D1F13119F5-76996-0002D564FBB255BD/384FE658-537D-45BC-AF0D-850578C3D6D0.png] [image:90F9A20B-F518-490F-9589-E642B14FEA94-76996-0002D56F65054CFA/DB6FB9FD-D207-470E-9069-631F54B9992A.png] [image:8617D414-3D73-472F-8A61-0D7A74FD76B1-76996-0002D57EE9EF1C9F/280A1DD4-0F34-4ED1-8063-951DF0C4258E.png]
如何按照上述结构图来构建模型预测第N和第N-1个字
How to build the predicting n-th from n-1 words model based on the diagram above
108:57-112:08
How to build the predicting n-th from n-1 words model based on the diagram above
* How to implement the diagram into a NN?
* When is appropriate to refractor code?
* Why RNN can be seen as actually the NN with refactor?
* How to create a tensor container for h the activation?
* Why the h the activation shape should be a fixed size? (just assume to be in the video)
[image:3559F672-B354-4F89-9B4C-3BAF03458589-76996-0002D67E54EA29E7/392E6C24-BDAD-499F-8179-C84AFFA17A3B.png] [image:FEBC5FE9-71E0-4759-BBAC-DB98CB7FD8D2-76996-0002D6BE424D17C4/76DF1742-C01A-4065-8994-3FC590FF12FF.png]
如何构建神经网络来预测第N和第N-1个字
How to build the NN to predict N-th word with N-1th word?
112:08-115:00
How to build the NN to predict N-th word with N-1th word
- How can such model’s loss function make the most out of words input (compared to previous model)?
- [image:115D0079-23B3-41B6-A52C-1F49EAAAFE22-76996-0002D8B1CA8E7878/EDE758BD-BEB8-4B1C-97C3-8A5821C2C0D0.png]
* What does the diagram and the NN look like now?
* [image:AD60460F-79F2-4AB9-A62B-7CEA27DEE907-76996-0002D8CF71CAF5D2/AF0DF661-4D14-4855-AA30-B80D8CE0325D.png] [image:05A5B6D4-9590-40E1-8E68-A7F5A0C0C163-76996-0002D8DAE81AD37C/0B17DF53-3B3B-46E0-8038-765B09D66A52.png]
- Why this new model has a worse performance?
- [image:B58A024E-E6D2-40F4-BC31-7CCEAAD717F1-76996-0002D8EC63A82D9B/9770EC6E-5046-417C-80FD-09132DBB0B24.png]
- How to solve this problem?
- [image:602586BF-3EC6-4B5C-9CD6-598BC7BB0E66-76996-0002D909E79C817B/1E5F7C06-85C4-4307-BBC8-E7B0454BC1EB.png][image:0D53D28C-C4CA-4315-A73D-D0D6FC0553B4-76996-0002D920A624A226/606BD09D-1FD6-493C-BFCF-4457923C4DCF.png]
* So, what is RNN?
* just fully connected NN with refactor of loops
如何构建多层RNN
How to construct multi-layer RNN?
115:00-119:00
How to construct multi-layer RNN
- How to refactor the code to with nn.RNN?
- [image:FBD17C9F-E448-4C70-9667-7518665CE381-76996-0002DBFE40EF2337/A2496C4A-EB7C-4FE3-8A7B-7183F6F24527.png]
- How to construct a 2-layer RNN?
- What is GRU or LSTM
- [image:98B2640C-1011-4FBC-B3CF-7A9D7F02D8BC-76996-0002DC3F7C828DAD/3E17705E-BFA2-4FC7-8CBF-FAC8D15AFC9E.png] [image:23733A06-1A7D-42C7-935E-2BC9BFAE7045-76996-0002DC47DC4EE864/F2D891A4-8012-461A-8814-6BEC49DEC1B1.png]
* What are sequence labeling tasks?
* What and how to do NLP classification?
如何用心学好
How to learn by heart
1:58:59-end
How to learn by heart
What is it like of watching lessons again and again?
- a second time can always help to get some bit of the lesson previously not understood and enable to implement some code which was not able to previously
为什么我们应该写和分享代码
Why should I write and share codes?
- make sure you code something on your own
- people can confirm what you did right and where to improve and learn more
为什么以及如何读论文
Why and How to read papers?
- more papers to cover in part 2
- just focus on practical sections such as “why we are solving this problem” and “what are the results”
用博客写什么
What to write on blogs?
- put into words on what you learnt
- not for DL academic professionals
- but to help people like you 6 months ago
如何利用论坛
What to do on forums?
- to get help from others
- to help others
- to share your successful stories
为什么以及如何做到一起学
Why and how to get together with your peers?
- social learning is very helpful
- we can do book clubs, meetups, study groups
为什么以及如何做些东西
Why and how to build something?
- make the world a slightly better place
- or, make people you love a little more delight
- just finish something, build something, such as a model can generate tweet sounds like Elon Musk
- people on forum can help even guide you to do so
- you can build an app, create a project, help with library
[image:9D096B6E-14A0-40E2-AB84-41EB42F1ABC5-76996-0002CB13B44C88BA/FD9C3647-BCE9-47D8-BB36-8EF64F8D9356.png]
如何参与fastai library 建设
How to get involved with fastai library?
- it may seem boring from outside
- help docs, texts require deep understanding of the implementation of codes
- curators can send you papers and materials to figure out why they wrote code this way
- eventually you are going to write the docs and texts to explain it clearly
[image:E6B8B10E-1561-469E-B457-9EB422A37EA0-76996-0002CB1789E76F94/391148FC-2619-4F2E-AF71-F7E7C064E926.png]
如何启动学习小组
How to initiate a study group?
- go on to forum and find your timezone
- get a google sheet to sign up
- to create projects and wiki together
我们会从part2中学到什么?
What to expect from part 2 fastai?
- see how the fastai codebase was built from stage to stage
- talking about software development in terms of fastai
- to learn the process of doing research and reading papers
- how to turn math into codes
- many more advanced architectures
[image:48B3388F-1A6C-4D5F-B31D-BFF092F6F724-76996-0002CC48AABA35C9/18DAEBA0-62B4-4E4A-84A0-DF8DC9AC6ECD.png]
Jeremy的工做状态是怎样的?以及如何平衡生活与工作
What Jeremy’s typical daylight is like? How to manage work and life?
- people shocked to see me disorganized and incompetent
- have a good time without a specific plan, just want to finish it
- DL is not like web app with regular feedback and specific milestones, therefore you must be able to have fun in DL to keep you going
- No meetings, phone calls, coffee, TV, PC games, but a lot of time coding, reading, exercising and with family
- make sure to get something finished properly, and even get a group to do it together
机器学习深度学习的哪些领域让你兴奋,为什么不是强化学习
What part of ML DL most exciting to you and why not RL?
- RL is overly complex and less useful to normal people in day to day work
- Transfer learning has always been under appreciated and researched, help changed NLP with transfer learning. I am excited to get transfer learning work better and faster in many areas
在part2开始前该做什么
What to recommend to practice before part 2?
- just coding and code all the time
- make sure you know all the tiny coding skills we covered
- rebuild all the notebooks from scratch but with fastai lib
- it makes you top edge students or practioners
fastai5年之后会是什么样子
What is fastai going to be in 5 years?
- become a software to use without coding
- get rid of course and code and do useful stuff easily and nicely
第二课 手写SGD
所需library
所需library
%matplotlib inline
from fastai.basics import *
本Nb的目的
本Nb的目的
In this part of the lecture we explain Stochastic Gradient Descent (SGD) which is an optimization method commonly used in neural networks. We will illustrate the concepts with concrete examples.
Linear Regression problem
什么是线性回归问题
什么是线性回归问题
The goal of linear regression is to fit a line to a set of points.
构建features, X
构建features, X
n=100
x = torch.ones(n,2) # 第二个特征的值都是1, 让问题简单点
x[:,0].uniform_(-1.,1)
x[:5]
tensor([[-0.1957, 1.0000],
[ 0.1826, 1.0000],
[-0.1008, 1.0000],
[-0.1449, 1.0000],
[ 0.7091, 1.0000]])
设置模型参数
设置模型参数
a = tensor(3.,2); a
tensor([3., 2.])
构建模型:X与y的关系
构建模型:X与y的关系
y = x@a + torch.rand(n)
作图 X与Y的关系图
作图:X[:0] 与Y的关系图
plt.scatter(x[:,0], y);
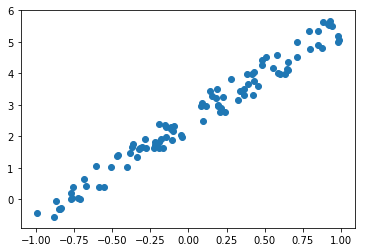
构建损失函数 MSE
构建损失函数 MSE
You want to find parameters (weights) a such that you minimize the error between the points and the line x@a. Note that here a is unknown. For a regression problem the most common error function or loss function is the mean squared error.
def mse(y_hat, y): return ((y_hat-y)**2).mean()
假设一个特点的线性模型
假设一个特点的线性模型
Suppose we believe a = (-1.0,1.0) then we can compute y_hat which is our prediction and then compute our error.
a = tensor(-1.,1)
计算y值和损失值
计算y值和损失值
y_hat = x@a
mse(y_hat, y)
tensor(7.9356)
对原始数据点和预测值作图
对原始数据点和预测值作图
plt.scatter(x[:,0],y)
plt.scatter(x[:,0],y_hat);
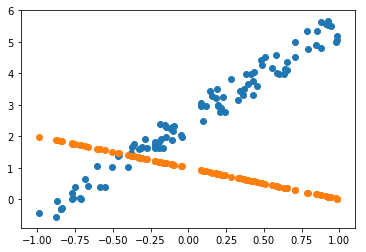
So far we have specified the model (linear regression) and the evaluation criteria (or loss function). Now we need to handle optimization; that is, how do we find the best values for a? How do we find the best fitting linear regression.
用pytorch构建梯度下降
用pytorch构建梯度下降
Gradient Descent
We would like to find the values of a that minimize mse_loss.
Gradient descent is an algorithm that minimizes functions. Given a function defined by a set of parameters, gradient descent starts with an initial set of parameter values and iteratively moves toward a set of parameter values that minimize the function. This iterative minimization is achieved by taking steps in the negative direction of the function gradient.
Here is gradient descent implemented in PyTorch.
创建模型参数
创建模型参数
a = nn.Parameter(a); a
Parameter containing:
tensor([-1., 1.], requires_grad=True)
构建SGD函数
构建SGD函数
def update():
y_hat = x@a
loss = mse(y, y_hat)
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad)
a.grad.zero_()
跑SGD函数100遍
跑SGD函数100遍
lr = 1e-1
for t in range(100): update()
tensor(7.9356, grad_fn=<MeanBackward1>)
tensor(1.4609, grad_fn=<MeanBackward1>)
tensor(0.4824, grad_fn=<MeanBackward1>)
tensor(0.1995, grad_fn=<MeanBackward1>)
tensor(0.1147, grad_fn=<MeanBackward1>)
tensor(0.0893, grad_fn=<MeanBackward1>)
tensor(0.0816, grad_fn=<MeanBackward1>)
tensor(0.0793, grad_fn=<MeanBackward1>)
tensor(0.0786, grad_fn=<MeanBackward1>)
tensor(0.0784, grad_fn=<MeanBackward1>)
作图
作图
plt.scatter(x[:,0],y)
plt.scatter(x[:,0],x@a);
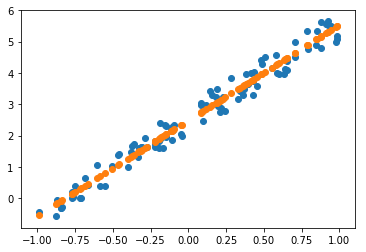
让画动起来
让画动起来
Animate it!
from matplotlib import animation, rc
rc('animation', html='jshtml')
a = nn.Parameter(tensor(-1.,1))
fig = plt.figure()
plt.scatter(x[:,0], y, c='orange')
line, = plt.plot(x[:,0], x@a)
plt.close()
def animate(i):
update()
line.set_ydata(x@a)
return line,
animation.FuncAnimation(fig, animate, np.arange(0, 100), interval=20)
深度学习关键词汇
深度学习关键词汇
In practice, we don’t calculate on the whole file at once, but we use mini-batches.
Vocab
- Learning rate
- Epoch
- Minibatch
- SGD
- Model / Architecture
- Parameters
- Loss function
For classification problems, we use cross entropy loss, also known as negative log likelihood loss. This penalizes incorrect confident predictions, and correct unconfident predictions.
Image segmentation with CamVid
3行魔法代码
3行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai import *
from fastai.vision import *
from fastai.callbacks.hooks import *
下载在GitHub中的数据集
下载在GitHub中的数据集
The One Hundred Layer Tiramisu paper used a modified version of Camvid, with smaller images and few classes. You can get it from the CamVid directory of this repo:
git clone https://github.com/alexgkendall/SegNet-Tutorial.git
构建path到所需文件夹
构建path到所需文件夹
path = Path('./data/camvid-tiramisu')
path.ls()
[PosixPath('data/camvid-tiramisu/valannot'),
PosixPath('data/camvid-tiramisu/test'),
PosixPath('data/camvid-tiramisu/val'),
PosixPath('data/camvid-tiramisu/val.txt'),
PosixPath('data/camvid-tiramisu/trainannot'),
PosixPath('data/camvid-tiramisu/testannot'),
PosixPath('data/camvid-tiramisu/train'),
PosixPath('data/camvid-tiramisu/test.txt'),
PosixPath('data/camvid-tiramisu/train.txt'),
PosixPath('data/camvid-tiramisu/models')]
Data
将文件夹中文件转化成path list
将文件夹中文件转化成path list
fnames = get_image_files(path/'val')
fnames[:3]
[PosixPath('data/camvid-tiramisu/val/0016E5_08065.png'),
PosixPath('data/camvid-tiramisu/val/0016E5_07989.png'),
PosixPath('data/camvid-tiramisu/val/0016E5_08041.png')]
lbl_names = get_image_files(path/'valannot')
lbl_names[:3]
[PosixPath('data/camvid-tiramisu/valannot/0016E5_08065.png'),
PosixPath('data/camvid-tiramisu/valannot/0016E5_07989.png'),
PosixPath('data/camvid-tiramisu/valannot/0016E5_08041.png')]
将文件path转化成Image,再展示
将文件path转化成Image,再展示
img_f = fnames[0]
img = open_image(img_f)
img.show(figsize=(5,5))

对应文件图片找到annot图片在转化成mask图片
对应文件图片找到annot图片在转化成mask图片
def get_y_fn(x): return Path(str(x.parent)+'annot')/x.name
codes = array(['Sky', 'Building', 'Pole', 'Road', 'Sidewalk', 'Tree',
'Sign', 'Fence', 'Car', 'Pedestrian', 'Cyclist', 'Void'])
mask = open_mask(get_y_fn(img_f))
mask.show(figsize=(5,5), alpha=1)

查看mask图片的尺寸和数据
查看mask图片的尺寸和数据
src_size = np.array(mask.shape[1:])
src_size,mask.data
(array([360, 480]), tensor([[[1, 1, 1, ..., 5, 5, 5],
[1, 1, 1, ..., 5, 5, 5],
[1, 1, 1, ..., 5, 5, 5],
...,
[4, 4, 4, ..., 3, 3, 3],
[4, 4, 4, ..., 3, 3, 3],
[4, 4, 4, ..., 3, 3, 3]]]))
Datasets
设置小批量大小
设置小批量大小
bs,size = 8,src_size//2
创建segmentation data source
创建segmentation data source
src = (SegmentationItemList.from_folder(path)
.split_by_folder(valid='val')
.label_from_func(get_y_fn, classes=codes))
从data source创建databunch
从data source创建databunch
data = (src.transform(get_transforms(), tfm_y=True)
.databunch(bs=bs)
.normalize(imagenet_stats))
show_batch 将原图和annot图进行了融合,好比图片与label一同打印一样
show_batch 将原图和annot图进行了融合,好比图片与label一同打印一样
data.show_batch(2, figsize=(10,7))

Model
找出'void'对应的mask代码
找出’void’对应的mask代码
name2id = {v:k for k,v in enumerate(codes)}
void_code = name2id['Void']
针对camvid的准确率设计
针对camvid的准确率设计
def acc_camvid(input, target):
target = target.squeeze(1)
mask = target != void_code
return (input.argmax(dim=1)[mask]==target[mask]).float().mean()
metrics=acc_camvid
设置weight decay
设置weight decay
wd=1e-2
创建U-net模型
创建U-net模型
learn = unet_learner(data, models.resnet34, metrics=metrics, wd=wd, bottle=True)
寻找并画出学习率-损失值图,并挑选学习率
寻找并画出学习率-损失值图,并挑选学习率
lr_find(learn)
learn.recorder.plot()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
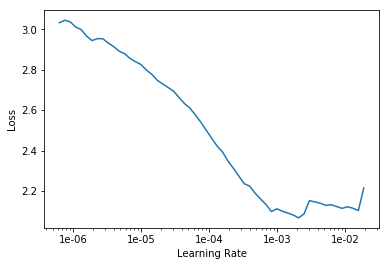
lr=2e-3
训练10次(设置pct_start)
训练10次(设置pct_start)
learn.fit_one_cycle(10, slice(lr), pct_start=0.8)
learn.save('stage-1')
加载,解冻,设置学习率区间slice, 用pct_start训练12次
加载,解冻,设置学习率区间slice, 用pct_start训练12次
learn.load('stage-1');
learn.unfreeze()
lrs = slice(lr/100,lr)
learn.fit_one_cycle(12, lrs, pct_start=0.8)
Total time: 05:52
| epoch | train_loss | valid_loss | acc_camvid |
|---|---|---|---|
| 1 | 0.277594 | 0.273819 | 0.913931 |
| 2 | 0.271254 | 0.266760 | 0.916620 |
| 3 | 0.269084 | 0.269211 | 0.915474 |
| 4 | 0.273889 | 0.295377 | 0.914132 |
| 5 | 0.268701 | 0.312179 | 0.906329 |
| 6 | 0.295838 | 0.363080 | 0.902990 |
| 7 | 0.304576 | 0.323809 | 0.898795 |
| 8 | 0.290066 | 0.267403 | 0.920294 |
| 9 | 0.274901 | 0.274512 | 0.914693 |
| 10 | 0.275207 | 0.273877 | 0.920632 |
| 11 | 0.248439 | 0.236959 | 0.931970 |
| 12 | 0.224031 | 0.253183 | 0.926807 |
learn.save('stage-2');
Go big
释放空间
释放空间
learn=None
gc.collect()
4194
根据数据大小,调整小批量大小
根据数据大小,调整小批量大小
You may have to restart your kernel and come back to this stage if you run out of memory, and may also need to decrease bs.
size = src_size
bs=8
准备Databunch
准备Databunch
data = (src.transform(get_transforms(), size=size, tfm_y=True)
.databunch(bs=bs)
.normalize(imagenet_stats))
构建U-net并加载之前训练的模型
构建U-net并加载之前训练的模型
learn = unet_learner(data, models.resnet34, metrics=metrics, wd=wd, bottle=True).load('stage-2');
寻找学习率并作图
寻找学习率并作图
lr_find(learn)
learn.recorder.plot()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
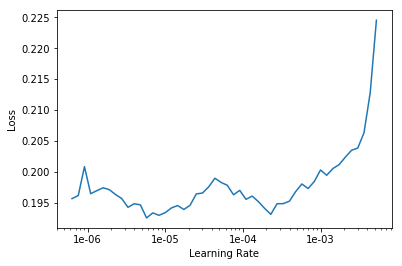
挑选学习率并开始训练,采用slice, pct_start
挑选学习率并开始训练,采用slice, pct_start
lr=1e-3
learn.fit_one_cycle(10, slice(lr), pct_start=0.8)
learn.save('stage-1-big')
加载模型,解冻,设置学习率区间slice, 并训练10次
加载模型,解冻,设置学习率区间slice, 并训练10次
learn.load('stage-1-big');
learn.unfreeze()
lrs = slice(lr/1000,lr/10)
learn.fit_one_cycle(10, lrs)
learn.save('stage-2-big')
加载训练好的模型,并展示结果
加载训练好的模型,并展示结果
learn.load('stage-2-big');
learn.show_results(rows=3, figsize=(9,11))

fin
# start: 480x360
总结模型特点
总结模型特点
print(learn.summary())
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
Conv2d [8, 64, 180, 240] 9408 False
______________________________________________________________________
BatchNorm2d [8, 64, 180, 240] 128 True
______________________________________________________________________
ReLU [8, 64, 180, 240] 0 False
______________________________________________________________________
MaxPool2d [8, 64, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
ReLU [8, 64, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
ReLU [8, 64, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
ReLU [8, 64, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 64, 90, 120] 36864 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
Conv2d [8, 128, 45, 60] 73728 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
ReLU [8, 128, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 128, 45, 60] 8192 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
ReLU [8, 128, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
ReLU [8, 128, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
ReLU [8, 128, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 128, 45, 60] 147456 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 294912 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 32768 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
ReLU [8, 256, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 256, 23, 30] 589824 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 512, 12, 15] 1179648 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
ReLU [8, 512, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 512, 12, 15] 2359296 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
Conv2d [8, 512, 12, 15] 131072 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
Conv2d [8, 512, 12, 15] 2359296 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
ReLU [8, 512, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 512, 12, 15] 2359296 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
Conv2d [8, 512, 12, 15] 2359296 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
ReLU [8, 512, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 512, 12, 15] 2359296 False
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
BatchNorm2d [8, 512, 12, 15] 1024 True
______________________________________________________________________
ReLU [8, 512, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 1024, 12, 15] 4719616 True
______________________________________________________________________
ReLU [8, 1024, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 512, 12, 15] 4719104 True
______________________________________________________________________
ReLU [8, 512, 12, 15] 0 False
______________________________________________________________________
Conv2d [8, 1024, 12, 15] 525312 True
______________________________________________________________________
PixelShuffle [8, 256, 24, 30] 0 False
______________________________________________________________________
ReplicationPad2d [8, 256, 25, 31] 0 False
______________________________________________________________________
AvgPool2d [8, 256, 24, 30] 0 False
______________________________________________________________________
ReLU [8, 1024, 12, 15] 0 False
______________________________________________________________________
BatchNorm2d [8, 256, 23, 30] 512 True
______________________________________________________________________
Conv2d [8, 512, 23, 30] 2359808 True
______________________________________________________________________
ReLU [8, 512, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 512, 23, 30] 2359808 True
______________________________________________________________________
ReLU [8, 512, 23, 30] 0 False
______________________________________________________________________
ReLU [8, 512, 23, 30] 0 False
______________________________________________________________________
Conv2d [8, 1024, 23, 30] 525312 True
______________________________________________________________________
PixelShuffle [8, 256, 46, 60] 0 False
______________________________________________________________________
ReplicationPad2d [8, 256, 47, 61] 0 False
______________________________________________________________________
AvgPool2d [8, 256, 46, 60] 0 False
______________________________________________________________________
ReLU [8, 1024, 23, 30] 0 False
______________________________________________________________________
BatchNorm2d [8, 128, 45, 60] 256 True
______________________________________________________________________
Conv2d [8, 384, 45, 60] 1327488 True
______________________________________________________________________
ReLU [8, 384, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 384, 45, 60] 1327488 True
______________________________________________________________________
ReLU [8, 384, 45, 60] 0 False
______________________________________________________________________
ReLU [8, 384, 45, 60] 0 False
______________________________________________________________________
Conv2d [8, 768, 45, 60] 295680 True
______________________________________________________________________
PixelShuffle [8, 192, 90, 120] 0 False
______________________________________________________________________
ReplicationPad2d [8, 192, 91, 121] 0 False
______________________________________________________________________
AvgPool2d [8, 192, 90, 120] 0 False
______________________________________________________________________
ReLU [8, 768, 45, 60] 0 False
______________________________________________________________________
BatchNorm2d [8, 64, 90, 120] 128 True
______________________________________________________________________
Conv2d [8, 256, 90, 120] 590080 True
______________________________________________________________________
ReLU [8, 256, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 256, 90, 120] 590080 True
______________________________________________________________________
ReLU [8, 256, 90, 120] 0 False
______________________________________________________________________
ReLU [8, 256, 90, 120] 0 False
______________________________________________________________________
Conv2d [8, 512, 90, 120] 131584 True
______________________________________________________________________
PixelShuffle [8, 128, 180, 240] 0 False
______________________________________________________________________
ReplicationPad2d [8, 128, 181, 241] 0 False
______________________________________________________________________
AvgPool2d [8, 128, 180, 240] 0 False
______________________________________________________________________
ReLU [8, 512, 90, 120] 0 False
______________________________________________________________________
BatchNorm2d [8, 64, 180, 240] 128 True
______________________________________________________________________
Conv2d [8, 96, 180, 240] 165984 True
______________________________________________________________________
ReLU [8, 96, 180, 240] 0 False
______________________________________________________________________
Conv2d [8, 96, 180, 240] 83040 True
______________________________________________________________________
ReLU [8, 96, 180, 240] 0 False
______________________________________________________________________
ReLU [8, 192, 180, 240] 0 False
______________________________________________________________________
Conv2d [8, 384, 180, 240] 37248 True
______________________________________________________________________
PixelShuffle [8, 96, 360, 480] 0 False
______________________________________________________________________
ReplicationPad2d [8, 96, 361, 481] 0 False
______________________________________________________________________
AvgPool2d [8, 96, 360, 480] 0 False
______________________________________________________________________
ReLU [8, 384, 180, 240] 0 False
______________________________________________________________________
MergeLayer [8, 99, 360, 480] 0 False
______________________________________________________________________
Conv2d [8, 49, 360, 480] 43708 True
______________________________________________________________________
ReLU [8, 49, 360, 480] 0 False
______________________________________________________________________
Conv2d [8, 99, 360, 480] 43758 True
______________________________________________________________________
ReLU [8, 99, 360, 480] 0 False
______________________________________________________________________
MergeLayer [8, 99, 360, 480] 0 False
______________________________________________________________________
Conv2d [8, 12, 360, 480] 1200 True
______________________________________________________________________
Total params: 41133018
Total trainable params: 19865370
Total non-trainable params: 21267648
Regression with BIWI head pose dataset
BIWI head pose数据集要处理什么问题
BIWI head pose数据集要处理什么问题
This is a more advanced example to show how to create custom datasets and do regression with images. Our task is to find the center of the head in each image. The data comes from the BIWI head pose dataset, thanks to Gabriele Fanelli et al. We have converted the images to jpeg format, so you should download the converted dataset from this link.
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.vision import *
Getting and converting the data
下载数据
下载数据
path = untar_data(URLs.BIWI_HEAD_POSE)
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6); cal
array([[517.679, 0. , 320. ],
[ 0. , 517.679, 240.5 ],
[ 0. , 0. , 1. ]])
从文件path打开图片
从文件path打开图片
fname = '09/frame_00667_rgb.jpg'
def img2txt_name(f): return path/f'{str(f)[:-7]}pose.txt'
img = open_image(path/fname)
img.show()

从文件图片path提取对应的头部位置坐标
从文件图片path提取对应的头部位置坐标
ctr = np.genfromtxt(img2txt_name(fname), skip_header=3); ctr
array([187.332 , 40.3892, 893.135 ])
def convert_biwi(coords):
c1 = coords[0] * cal[0][0]/coords[2] + cal[0][2]
c2 = coords[1] * cal[1][1]/coords[2] + cal[1][2]
return tensor([c2,c1])
def get_ctr(f):
ctr = np.genfromtxt(img2txt_name(f), skip_header=3)
return convert_biwi(ctr)
def get_ip(img,pts): return ImagePoints(FlowField(img.size, pts), scale=True)
get_ctr(fname)
tensor([263.9104, 428.5814])
将图片和坐标同时画出来
将图片和坐标同时画出来
ctr = get_ctr(fname)
img.show(y=get_ip(img, ctr), figsize=(6, 6))

Creating a dataset
从pointsItemList 创建Databunch
从pointsItemList 创建Databunch
data = (PointsItemList.from_folder(path)
.split_by_valid_func(lambda o: o.parent.name=='13')
.label_from_func(get_ctr)
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch().normalize(imagenet_stats)
)
展示小批量中的数据(图同标注)
展示小批量中的数据(图同标注)
data.show_batch(3, figsize=(9,6))

Train model
创建模型
创建模型
learn = create_cnn(data, models.resnet34)
寻找学习率作图,并选择
寻找学习率作图,并选择
learn.lr_find()
learn.recorder.plot()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
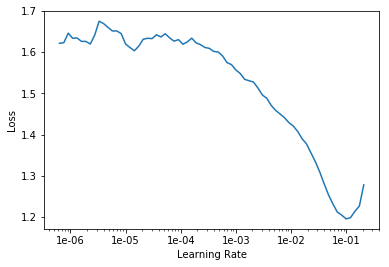
lr = 2e-2
slice学习率训练5次
slice学习率训练5次
learn.fit_one_cycle(5, slice(lr))
learn.save('stage-1')

Data augmentation
调整transformation设置
调整transformation设置
tfms = get_transforms(max_rotate=20, max_zoom=1.5, max_lighting=0.5, max_warp=0.4, p_affine=1., p_lighting=1.)
从PointsItemList 构建DataBunch
从PointsItemList 构建DataBunch
data = (PointsItemList.from_folder(path)
.split_by_valid_func(lambda o: o.parent.name=='13')
.label_from_func(get_ctr)
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch().normalize(imagenet_stats)
)
对一张图做多变形作图
对一张图做多变形作图
def _plot(i,j,ax):
x,y = data.train_ds[0]
x.show(ax, y=y)
plot_multi(_plot, 3, 3, figsize=(8,6))

IMDB
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.text import *
Preparing the data
介绍数据集
介绍数据集
First let’s download the dataset we are going to study. The dataset has been curated by Andrew Maas et al. and contains a total of 100,000 reviews on IMDB. 25,000 of them are labelled as positive and negative for training, another 25,000 are labelled for testing (in both cases they are highly polarized). The remaning 50,000 is an additional unlabelled data (but we will find a use for it nonetheless).
We’ll begin with a sample we’ve prepared for you, so that things run quickly before going over the full dataset.
查看数据文件夹
查看数据文件夹
path = untar_data(URLs.IMDB_SAMPLE)
path.ls()
[PosixPath('/home/ubuntu/notebooks/data/imdb_sample/data_clas_export.pkl'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/export_lm.pkl'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/export.pkl'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/texts.csv'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/data_lm_export.pkl'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/export_clas.pkl'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/models'),
PosixPath('/home/ubuntu/notebooks/data/imdb_sample/save_data_clas.pkl')]
查看csv
查看csv
It only contains one csv file, let’s have a look at it.
df = pd.read_csv(path/'texts.csv')
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| label | text | is_valid | |
|---|---|---|---|
| 0 | negative | Un-bleeping-believable! Meg Ryan doesn't even ... | False |
| 1 | positive | This is a extremely well-made film. The acting... | False |
| 2 | negative | Every once in a long while a movie will come a... | False |
| 3 | positive | Name just says it all. I watched this movie wi... | False |
| 4 | negative | This movie succeeds at being one of the most u... | False |
df['text'][1]
'This is a extremely well-made film. The acting, script and camera-work are all first-rate. The music is good, too, though it is mostly early in the film, when things are still relatively cheery. There are no really superstars in the cast, though several faces will be familiar. The entire cast does an excellent job with the script.<br /><br />But it is hard to watch, because there is no good end to a situation like the one presented. It is now fashionable to blame the British for setting Hindus and Muslims against each other, and then cruelly separating them into two countries. There is some merit in this view, but it\'s also true that no one forced Hindus and Muslims in the region to mistreat each other as they did around the time of partition. It seems more likely that the British simply saw the tensions between the religions and were clever enough to exploit them to their own ends.<br /><br />The result is that there is much cruelty and inhumanity in the situation and this is very unpleasant to remember and to see on the screen. But it is never painted as a black-and-white case. There is baseness and nobility on both sides, and also the hope for change in the younger generation.<br /><br />There is redemption of a sort, in the end, when Puro has to make a hard choice between a man who has ruined her life, but also truly loved her, and her family which has disowned her, then later come looking for her. But by that point, she has no option that is without great pain for her.<br /><br />This film carries the message that both Muslims and Hindus have their grave faults, and also that both can be dignified and caring people. The reality of partition makes that realisation all the more wrenching, since there can never be real reconciliation across the India/Pakistan border. In that sense, it is similar to "Mr & Mrs Iyer".<br /><br />In the end, we were glad to have seen the film, even though the resolution was heartbreaking. If the UK and US could deal with their own histories of racism with this kind of frankness, they would certainly be better off.'
从CSV中创建TextDataBunch
从CSV中创建TextDataBunch
It contains one line per review, with the label (‘negative’ or ‘positive’), the text and a flag to determine if it should be part of the validation set or the training set. If we ignore this flag, we can create a DataBunch containing this data in one line of code:
data_lm = TextDataBunch.from_csv(path, 'texts.csv')
TextDataBunch背后工作流程
TextDataBunch背后工作流程
By executing this line a process was launched that took a bit of time. Let’s dig a bit into it. Images could be fed (almost) directly into a model because they’re just a big array of pixel values that are floats between 0 and 1. A text is composed of words, and we can’t apply mathematical functions to them directly. We first have to convert them to numbers. This is done in two differents steps: tokenization and numericalization. A TextDataBunch does all of that behind the scenes for you.
Before we delve into the explanations, let’s take the time to save the things that were calculated.
保存和加载处理好的语言模型
保存和加载处理好的语言模型
data_lm.save()
Next time we launch this notebook, we can skip the cell above that took a bit of time (and that will take a lot more when you get to the full dataset) and load those results like this:
data = load_data(path)
Tokenization
什么是tokenization
什么是tokenization
The first step of processing we make the texts go through is to split the raw sentences into words, or more exactly tokens. The easiest way to do this would be to split the string on spaces, but we can be smarter:
- we need to take care of punctuation
- some words are contractions of two different words, like isn’t or don’t
- we may need to clean some parts of our texts, if there’s HTML code for instance
To see what the tokenizer had done behind the scenes, let’s have a look at a few texts in a batch.
创建并展示TextClasDataBunch
创建并展示TextClasDataBunch
data = TextClasDataBunch.from_csv(path, 'texts.csv')
data.show_batch()
| text | target |
|---|---|
| xxbos xxmaj raising xxmaj victor xxmaj vargas : a xxmaj review \n \n xxmaj you know , xxmaj raising xxmaj victor xxmaj vargas is like sticking your hands into a big , steaming bowl of xxunk . xxmaj it 's warm and gooey , but you 're not sure if it feels right . xxmaj try as i might , no matter how warm and gooey xxmaj raising xxmaj | negative |
| xxbos xxup the xxup shop xxup around xxup the xxup corner is one of the sweetest and most feel - good romantic comedies ever made . xxmaj there 's just no getting around that , and it 's hard to actually put one 's feeling for this film into words . xxmaj it 's not one of those films that tries too hard , nor does it come up with | positive |
| xxbos xxmaj now that xxmaj che(2008 ) has finished its relatively short xxmaj australian cinema run ( extremely limited xxunk screen in xxmaj sydney , after xxunk ) , i can xxunk join both xxunk of " xxmaj at xxmaj the xxmaj movies " in taking xxmaj steven xxmaj soderbergh to task . \n \n xxmaj it 's usually satisfying to watch a film director change his style / | negative |
| xxbos xxmaj this film sat on my xxmaj tivo for weeks before i watched it . i dreaded a self - indulgent xxunk flick about relationships gone bad . i was wrong ; this was an xxunk xxunk into the screwed - up xxunk of xxmaj new xxmaj yorkers . \n \n xxmaj the format is the same as xxmaj max xxmaj xxunk ' " xxmaj la xxmaj ronde | positive |
| xxbos xxmaj many neglect that this is n't just a classic due to the fact that it 's the first xxup 3d game , or even the first xxunk - up . xxmaj it 's also one of the first stealth games , one of the xxunk definitely the first ) truly claustrophobic games , and just a pretty well - xxunk gaming experience in general . xxmaj with graphics | positive |
The texts are truncated at 100 tokens for more readability. We can see that it did more than just split on space and punctuation symbols:
- the “'s” are grouped together in one token
- the contractions are separated like this: “did”, “n’t”
- content has been cleaned for any HTML symbol and lower cased
- there are several special tokens (all those that begin by xx), to replace unknown tokens (see below) or to introduce different text fields (here we only have one).
Numericalization
什么是numericalization
什么是numericalization
Once we have extracted tokens from our texts, we convert to integers by creating a list of all the words used. We only keep the ones that appear at least twice with a maximum vocabulary size of 60,000 (by default) and replace the ones that don’t make the cut by the unknown token UNK.
The correspondance from ids to tokens is stored in the vocab attribute of our datasets, in a dictionary called itos (for int to string).
查看 UNK
查看 UNK
data.vocab.itos[:10]
['xxunk',
'xxpad',
'xxbos',
'xxfld',
'xxmaj',
'xxup',
'xxrep',
'xxwrep',
'the',
'.']
查看数据data
查看数据data
And if we look at what a what’s in our datasets, we’ll see the tokenized text as a representation:
data.train_ds[0][0]
Text xxbos i know that originally , this film was xxup not a box office hit , but in light of recent xxmaj hollywood releases ( most of which have been decidedly formula - ridden , plot less , pointless , " save - the - blonde - chick - no - matter - what " xxunk ) , xxmaj xxunk of xxmaj all xxmaj xxunk , certainly in this sorry context deserves a second opinion . xxmaj the film -- like the book -- loses xxunk in some of the historical background , but it xxunk a uniquely xxmaj american dilemma set against the uniquely horrific xxmaj american xxunk of human xxunk , and some of its tragic ( and funny , and touching ) consequences .
xxmaj and worthy of xxunk out is the youthful xxmaj robert xxmaj xxunk , cast as the leading figure , xxmaj xxunk , whose xxunk xxunk is truly universal as he sets out in the beginning of his ' coming of age , ' only to be xxunk disappointed at what turns out to become his true education in the ways of the xxmaj southern plantation world of xxmaj xxunk , at the xxunk of the xxunk period . xxmaj when i saw the previews featuring the ( xxunk ) blond - xxunk xxmaj xxunk , i expected a xxunk , a xxunk , a xxunk -- i was pleasantly surprised .
xxmaj xxunk xxmaj davis , xxmaj ruby xxmaj dee , the late xxmaj ben xxmaj xxunk , xxmaj xxunk xxmaj xxunk , xxmaj victoria xxmaj xxunk and even xxmaj xxunk xxmaj guy xxunk vivid imagery and formidable skill as actors in the backdrop xxunk of xxunk , voodoo , xxmaj xxunk " xxunk , " and xxmaj xxunk revolt woven into this tale of human passion , hate , love , family , and racial xxunk in a society which is supposedly gone and yet somehow is still with us .
But the underlying data is all numbers
data.train_ds[0][0].data[:10]
array([ 2, 18, 146, 19, 3788, 10, 20, 31, 25, 5])
With the data block API
如何用TextList.from_csv构建DataBunch
如何用TextList.from_csv构建DataBunch
We can use the data block API with NLP and have a lot more flexibility than what the default factory methods offer. In the previous example for instance, the data was randomly split between train and validation instead of reading the third column of the csv.
With the data block API though, we have to manually call the tokenize and numericalize steps. This allows more flexibility, and if you’re not using the defaults from fastai, the variaous arguments to pass will appear in the step they’re revelant, so it’ll be more readable.
data = (TextList.from_csv(path, 'texts.csv', cols='text')
.split_from_df(col=2)
.label_from_df(cols=0)
.databunch())
Language model
如果数据量过大,需要调小批量
如果数据量过大,需要调小批量
Note that language models can use a lot of GPU, so you may need to decrease batchsize here.
bs=48
下载完整数据并查看文件夹
下载完整数据并查看文件夹
Now let’s grab the full dataset for what follows.
path = untar_data(URLs.IMDB)
path.ls()
[PosixPath('/home/ubuntu/.fastai/data/imdb/test'),
PosixPath('/home/ubuntu/.fastai/data/imdb/tmp_clas'),
PosixPath('/home/ubuntu/.fastai/data/imdb/README'),
PosixPath('/home/ubuntu/.fastai/data/imdb/unsup'),
PosixPath('/home/ubuntu/.fastai/data/imdb/train'),
PosixPath('/home/ubuntu/.fastai/data/imdb/tmp_lm'),
PosixPath('/home/ubuntu/.fastai/data/imdb/models'),
PosixPath('/home/ubuntu/.fastai/data/imdb/imdb.vocab')]
(path/'train').ls()
[PosixPath('/home/ubuntu/.fastai/data/imdb/train/neg'),
PosixPath('/home/ubuntu/.fastai/data/imdb/train/unsupBow.feat'),
PosixPath('/home/ubuntu/.fastai/data/imdb/train/pos'),
PosixPath('/home/ubuntu/.fastai/data/imdb/train/labeledBow.feat')]
如何做NLP的迁移学习
如何做NLP的迁移学习
The reviews are in a training and test set following an imagenet structure. The only difference is that there is an unsup folder on top of train and test that contains the unlabelled data.
We’re not going to train a model that classifies the reviews from scratch. Like in computer vision, we’ll use a model pretrained on a bigger dataset (a cleaned subset of wikipedia called wikitext-103). That model has been trained to guess what the next word, its input being all the previous words. It has a recurrent structure and a hidden state that is updated each time it sees a new word. This hidden state thus contains information about the sentence up to that point.
We are going to use that ‘knowledge’ of the English language to build our classifier, but first, like for computer vision, we need to fine-tune the pretrained model to our particular dataset. Because the English of the reviews left by people on IMDB isn’t the same as the English of wikipedia, we’ll need to adjust the parameters of our model by a little bit. Plus there might be some words that would be extremely common in the reviews dataset but would be barely present in wikipedia, and therefore might not be part of the vocabulary the model was trained on.
如何将三个文件夹数据汇集成训练数据,并生成TextDataBunch
如何将三个文件夹数据汇集成训练数据,并生成TextDataBunch
This is where the unlabelled data is going to be useful to us, as we can use it to fine-tune our model. Let’s create our data object with the data block API (next line takes a few minutes).
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files
# so we only keep what's in train and test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
data_lm.save('data_lm.pkl')
TextDataBunch:忽略label, shuffle训练集而非验证集
TextDataBunch:忽略label, shuffle训练集而非验证集
We have to use a special kind of TextDataBunch for the language model, that ignores the labels (that’s why we put 0 everywhere), will shuffle the texts at each epoch before concatenating them all together (only for training, we don’t shuffle for the validation set) and will send batches that read that text in order with targets that are the next word in the sentence.
The line before being a bit long, we want to load quickly the final ids by using the following cell.
data_lm = load_data(path, 'data_lm.pkl', bs=bs)
data_lm.show_batch()
| idx | text |
|---|---|
| 0 | original script that xxmaj david xxmaj dhawan has worked on . xxmaj this one was a complete bit y bit rip off xxmaj hitch . i have nothing against remakes as such , but this one is just so lousy that it makes you even hate the original one ( which was pretty decent ) . i fail to understand what actors like xxmaj salman and xxmaj govinda saw in |
| 1 | ' classic ' xxmaj the xxmaj big xxmaj doll xxmaj house ' , which takes xxmaj awful to a whole new level . i can heartily recommend these two xxunk as a double - bill . xxmaj you 'll laugh yourself silly . xxbos xxmaj this movie is a pure disaster , the story is stupid and the editing is the worst i have seen , it confuses you incredibly |
| 2 | of xxmaj european cinema 's most quietly disturbing sociopaths and one of the most memorable finales of all time ( shamelessly stolen by xxmaj tarantino for xxmaj kill xxmaj bill xxmaj volume xxmaj two ) , but it has plenty more to offer than that . xxmaj playing around with chronology and inverting the usual clichés of standard ' lady vanishes ' plots , it also offers superb characterisation and |
| 3 | but even xxmaj martin xxmaj short managed a distinct , supporting character . ) \n\n i can understand the attraction of an imaginary world created in a good romantic comedy . xxmaj but this film is the prozac version of an imaginary world . i 'm frightened to consider that anyone could enjoy it even as pure fantasy . xxbos movie i have ever seen . xxmaj actually i find |
| 4 | xxmaj pre - xxmaj code film . xxbos xxmaj here 's a decidedly average xxmaj italian post apocalyptic take on the hunting / killing humans for sport theme ala xxmaj the xxmaj most xxmaj dangerous xxmaj game , xxmaj turkey xxmaj shoot , xxmaj gymkata and xxmaj the xxmaj running xxmaj man . \n\n xxmaj certainly the film reviewed here is nowhere near as much fun as the other listed |
基于NLP构建迁移学习模型
基于NLP构建迁移学习模型
We can then put this in a learner object very easily with a model loaded with the pretrained weights. They’ll be downloaded the first time you’ll execute the following line and stored in ~/.fastai/models/ (or elsewhere if you specified different paths in your config file).
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3)
寻找最优学习率并画图
寻找最优学习率并画图
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot(skip_end=15)
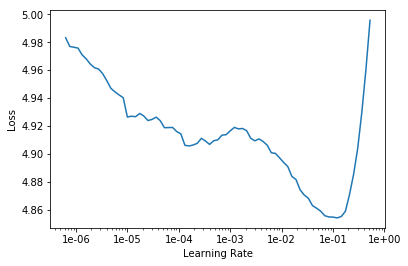
设置momentum来训练
设置momentum来训练
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
learn.save('fit_head')
加载模型,解冻,调节学习率继续训练
加载模型,解冻,调节学习率继续训练
learn.load('fit_head');
To complete the fine-tuning, we can then unfeeze and launch a new training.
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7))
learn.save('fine_tuned')
验证模型效果
验证模型效果
How good is our model? Well let’s try to see what it predicts after a few given words.
learn.load('fine_tuned');
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
I liked this movie because of the cool scenery and the high level of xxmaj british hunting . xxmaj the only thing this movie has going for it is the horrible acting and no script . xxmaj the movie was a big disappointment . xxmaj
I liked this movie because it was one of the few movies that made me laugh so hard i did n't like it . xxmaj it was a hilarious film and it was very entertaining .
xxmaj the acting was great , i 'm
保存encoder
保存encoder
We not only have to save the model, but also it’s encoder, the part that’s responsible for creating and updating the hidden state. For the next part, we don’t care about the part that tries to guess the next word.
learn.save_encoder('fine_tuned_enc')
Classifier
下载数据
下载数据
Now, we’ll create a new data object that only grabs the labelled data and keeps those labels. Again, this line takes a bit of time.
path = untar_data(URLs.IMDB)
生成Databunch并保存
生成Databunch并保存
data_clas = (TextList.from_folder(path, vocab=data_lm.vocab)
#grab all the text files in path
.split_by_folder(valid='test')
#split by train and valid folder
# (that only keeps 'train' and 'test' so no need to filter)
.label_from_folder(classes=['neg', 'pos'])
#label them all with their folders
.databunch(bs=bs))
data_clas.save('data_clas.pkl')
加载并展示数据
加载并展示数据
data_clas = load_data(path, 'data_clas.pkl', bs=bs)
data_clas.show_batch()
| text | target |
|---|---|
| xxbos xxmaj match 1 : xxmaj tag xxmaj team xxmaj table xxmaj match xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley vs xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley started things off with a xxmaj tag xxmaj team xxmaj table xxmaj match against xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit . xxmaj according to the rules | pos |
| xxbos xxmaj titanic directed by xxmaj james xxmaj cameron presents a fictional love story on the historical setting of the xxmaj titanic . xxmaj the plot is simple , xxunk , or not for those who love plots that twist and turn and keep you in suspense . xxmaj the end of the movie can be figured out within minutes of the start of the film , but the love | pos |
| xxbos xxmaj here are the matches . . . ( adv . = advantage ) \n\n xxmaj the xxmaj warriors ( xxmaj ultimate xxmaj warrior , xxmaj texas xxmaj tornado and xxmaj legion of xxmaj doom ) v xxmaj the xxmaj perfect xxmaj team ( xxmaj mr xxmaj perfect , xxmaj ax , xxmaj smash and xxmaj crush of xxmaj demolition ) : xxmaj ax is the first to go | neg |
| xxbos i felt duty bound to watch the 1983 xxmaj timothy xxmaj dalton / xxmaj zelah xxmaj clarke adaptation of " xxmaj jane xxmaj eyre , " because i 'd just written an article about the 2006 xxup bbc " xxmaj jane xxmaj eyre " for xxunk . \n\n xxmaj so , i approached watching this the way i 'd approach doing homework . \n\n i was irritated at first | pos |
| xxbos xxmaj no , this is n't a sequel to the fabulous xxup ova series , but rather a remake of the events that occurred after the death of xxmaj xxunk ( and the disappearance of xxmaj woodchuck ) . xxmaj it is also more accurate to the novels that inspired this wonderful series , which is why characters ( namely xxmaj orson and xxmaj xxunk ) are xxunk , | pos |
用迁移学习构建一个语言分类器
用迁移学习构建一个语言分类器
We can then create a model to classify those reviews and load the encoder we saved before.
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('fine_tuned_enc')
寻找最优学习率并作图
寻找最优学习率并作图
learn.lr_find()
learn.recorder.plot()
用momentum帮助训练
用momentum帮助训练
learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
learn.save('first')
加载模型,解冻,训练(slice, moms), 保存模型
加载模型,解冻,训练(slice, moms), 保存模型
learn.load('first');
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
learn.save('second')
加载模型,冰冻至倒数第三层,再训练
加载模型,冰冻至倒数第三层,再训练
learn.load('second');
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
learn.save('third')
加载模型,解冻,训练2次(slice,moms)
加载模型,解冻,训练2次(slice,moms)
learn.load('third');
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
预测
预测
learn.predict("I really loved that movie, it was awesome!")
(Category pos, tensor(1), tensor([7.5928e-04, 9.9924e-01]))
Multi-label prediction with Planet Amazon dataset
三行魔法代码
三行魔法代码
%reload_ext autoreload
%autoreload 2
%matplotlib inline
所需library
所需library
from fastai.vision import *
Getting the data
如何从Kaggle下载数据
如何从Kaggle下载数据
The planet dataset isn’t available on the fastai dataset page due to copyright restrictions. You can download it from Kaggle however. Let’s see how to do this by using the Kaggle API as it’s going to be pretty useful to you if you want to join a competition or use other Kaggle datasets later on.
First, install the Kaggle API by uncommenting the following line and executing it, or by executing it in your terminal (depending on your platform you may need to modify this slightly to either add source activate fastai or similar, or prefix pip with a path. Have a look at how conda install is called for your platform in the appropriate Returning to work section of https://course.fast.ai/. (Depending on your environment, you may also need to append “–user” to the command.)
# ! pip install kaggle --upgrade
Then you need to upload your credentials from Kaggle on your instance. Login to kaggle and click on your profile picture on the top left corner, then ‘My account’. Scroll down until you find a button named ‘Create New API Token’ and click on it. This will trigger the download of a file named ‘kaggle.json’.
Upload this file to the directory this notebook is running in, by clicking “Upload” on your main Jupyter page, then uncomment and execute the next two commands (or run them in a terminal). For Windows, uncomment the last two commands.
# ! mkdir -p ~/.kaggle/
# ! mv kaggle.json ~/.kaggle/
# For Windows, uncomment these two commands
# ! mkdir %userprofile%\.kaggle
# ! move kaggle.json %userprofile%\.kaggle
You’re all set to download the data from planet competition. You first need to go to its main page and accept its rules, and run the two cells below (uncomment the shell commands to download and unzip the data). If you get a 403 forbidden error it means you haven’t accepted the competition rules yet (you have to go to the competition page, click on Rules tab, and then scroll to the bottom to find the accept button).
path = Config.data_path()/'planet'
path.mkdir(parents=True, exist_ok=True)
path
PosixPath('/home/ubuntu/.fastai/data/planet')
# ! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train-jpg.tar.7z -p {path}
# ! kaggle competitions download -c planet-understanding-the-amazon-from-space -f train_v2.csv -p {path}
# ! unzip -q -n {path}/train_v2.csv.zip -d {path}
To extract the content of this file, we’ll need 7zip, so uncomment the following line if you need to install it (or run sudo apt install p7zip-full in your terminal).
# ! conda install -y -c haasad eidl7zip
And now we can unpack the data (uncomment to run - this might take a few minutes to complete).
# ! 7za -bd -y -so x {path}/train-jpg.tar.7z | tar xf - -C {path.as_posix()}
Multiclassification
查看CSV,一图多标注
查看CSV,一图多标注
Contrary to the pets dataset studied in last lesson, here each picture can have multiple labels. If we take a look at the csv file containing the labels (in ‘train_v2.csv’ here) we see that each ‘image_name’ is associated to several tags separated by spaces.
df = pd.read_csv(path/'train_v2.csv')
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| image_name | tags | |
|---|---|---|
| 0 | train_0 | haze primary |
| 1 | train_1 | agriculture clear primary water |
| 2 | train_2 | clear primary |
| 3 | train_3 | clear primary |
| 4 | train_4 | agriculture clear habitation primary road |
为什么用ImageList而非ImageDataBunch
为什么用ImageList而非ImageDataBunch
To put this in a DataBunch while using the data block API, we then need to using ImageList (and not ImageDataBunch). This will make sure the model created has the proper loss function to deal with the multiple classes.
设置变形细节
设置变形细节
tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
We use parentheses around the data block pipeline below, so that we can use a multiline statement without needing to add ‘\’.
用ImageList构建数据src,然后再建DataBunch
用ImageList构建数据src,然后再建DataBunch
np.random.seed(42)
src = (ImageList.from_csv(path, 'train_v2.csv', folder='train-jpg', suffix='.jpg')
.random_split_by_pct(0.2)
.label_from_df(label_delim=' '))
data = (src.transform(tfms, size=128)
.databunch().normalize(imagenet_stats))
查看数据
查看数据
show_batch still works, and show us the different labels separated by ;.
data.show_batch(rows=3, figsize=(12,9))

如何设计thresh_accuracy
如何设计thresh_accuracy
To create a Learner we use the same function as in lesson 1. Our base architecture is resnet34 again, but the metrics are a little bit differeent: we use accuracy_thresh instead of accuracy. In lesson 1, we determined the predicition for a given class by picking the final activation that was the biggest, but here, each activation can be 0. or 1. accuracy_thresh selects the ones that are above a certain threshold (0.5 by default) and compares them to the ground truth.
As for Fbeta, it’s the metric that was used by Kaggle on this competition. See here for more details.
挑选模型结构
挑选模型结构
arch = models.resnet50
设计含threshold的accuracy和F-score
设计含threshold的accuracy和F-score
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, thresh=0.2)
构建模型
构建模型
learn = create_cnn(data, arch, metrics=[acc_02, f_score])
Downloading: "https://download.pytorch.org/models/resnet50-19c8e357.pth" to /home/ubuntu/.torch/models/resnet50-19c8e357.pth
100%|██████████| 102502400/102502400 [00:01<00:00, 100859665.66it/s]
寻找学习率,作图,挑选最优值
寻找学习率,作图,挑选最优值
We use the LR Finder to pick a good learning rate.
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
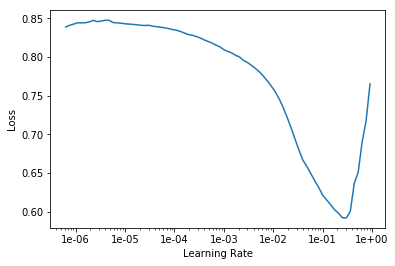
Then we can fit the head of our network.
lr = 0.01
训练模型
训练模型
learn.fit_one_cycle(5, slice(lr))
learn.save('stage-1-rn50')
解冻,再次寻找学习率,再训练
解冻,再次寻找学习率,再训练
…And fine-tune the whole model:
learn.unfreeze()
learn.lr_find()
learn.recorder.plot()
LR Finder complete, type {learner_name}.recorder.plot() to see the graph.
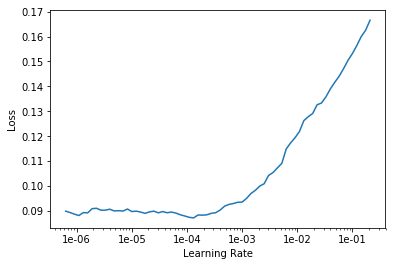
learn.fit_one_cycle(5, slice(1e-5, lr/5))
Total time: 04:00
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.097016 | 0.094868 | 0.952004 | 0.916215 |
| 2 | 0.095774 | 0.088899 | 0.954540 | 0.922340 |
| 3 | 0.090646 | 0.085958 | 0.959249 | 0.924921 |
| 4 | 0.085097 | 0.083291 | 0.958849 | 0.928195 |
| 5 | 0.079197 | 0.082855 | 0.958602 | 0.928259 |
learn.save('stage-2-rn50')
放大图片,生成新的Databunch
放大图片,生成新的Databunch
data = (src.transform(tfms, size=256)
.databunch().normalize(imagenet_stats))
learn.data = data
data.train_ds[0][0].shape
torch.Size([3, 256, 256])
封冻模型,只训练最后一层
封冻模型,只训练最后一层
learn.freeze()
寻找学习率,作图,选择最优值
寻找学习率,作图,选择最优值
learn.lr_find()
learn.recorder.plot()
LR Finder complete, type {learner_name}.recorder.plot() to see the graph.
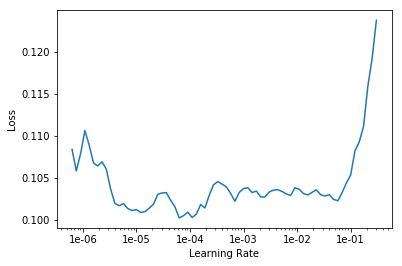
lr=1e-2/2
训练,保存
训练,保存
learn.fit_one_cycle(5, slice(lr))
Total time: 09:01
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.087761 | 0.085013 | 0.958006 | 0.926066 |
| 2 | 0.087641 | 0.083732 | 0.958260 | 0.927459 |
| 3 | 0.084250 | 0.082856 | 0.958485 | 0.928200 |
| 4 | 0.082347 | 0.081470 | 0.960091 | 0.929166 |
| 5 | 0.078463 | 0.080984 | 0.959249 | 0.930089 |
learn.save('stage-1-256-rn50')
解冻,调节学习效率,再训练
解冻,调节学习效率,再训练
learn.unfreeze()
learn.fit_one_cycle(5, slice(1e-5, lr/5))
Total time: 11:25
| epoch | train_loss | valid_loss | accuracy_thresh | fbeta |
|---|---|---|---|---|
| 1 | 0.082938 | 0.083548 | 0.957846 | 0.927756 |
| 2 | 0.086312 | 0.084802 | 0.958718 | 0.925416 |
| 3 | 0.084824 | 0.082339 | 0.959975 | 0.930054 |
| 4 | 0.078784 | 0.081425 | 0.959983 | 0.929634 |
| 5 | 0.074530 | 0.080791 | 0.960426 | 0.931257 |
画出训练中的损失值变化图
画出训练中的损失值变化图
learn.recorder.plot_losses()
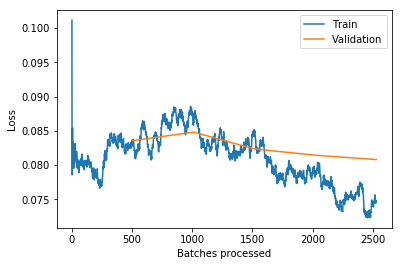
learn.save('stage-2-256-rn50')
Finish
生成预测值,上传Kaggle
生成预测值,上传Kaggle
You won’t really know how you’re going until you submit to Kaggle, since the leaderboard isn’t using the same subset as we have for training. But as a guide, 50th place (out of 938 teams) on the private leaderboard was a score of 0.930.
learn.export()
(This section will be covered in part 2 - please don’t ask about it just yet!  )
)
#! kaggle competitions download -c planet-understanding-the-amazon-from-space -f test-jpg.tar.7z -p {path}
#! 7za -bd -y -so x {path}/test-jpg.tar.7z | tar xf - -C {path}
#! kaggle competitions download -c planet-understanding-the-amazon-from-space -f test-jpg-additional.tar.7z -p {path}
#! 7za -bd -y -so x {path}/test-jpg-additional.tar.7z | tar xf - -C {path}
test = ImageList.from_folder(path/'test-jpg').add(ImageList.from_folder(path/'test-jpg-additional'))
len(test)
61191
learn = load_learner(path, test=test)
preds, _ = learn.get_preds(ds_type=DatasetType.Test)
thresh = 0.2
labelled_preds = [' '.join([learn.data.classes[i] for i,p in enumerate(pred) if p > thresh]) for pred in preds]
labelled_preds[:5]
['agriculture cultivation partly_cloudy primary road',
'clear haze primary water',
'agriculture clear cultivation primary',
'clear primary',
'partly_cloudy primary']
fnames = [f.name[:-4] for f in learn.data.test_ds.items]
df = pd.DataFrame({'image_name':fnames, 'tags':labelled_preds}, columns=['image_name', 'tags'])
df.to_csv(path/'submission.csv', index=False)
! kaggle competitions submit planet-understanding-the-amazon-from-space -f {path/'submission.csv'} -m "My submission"
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /home/ubuntu/.kaggle/kaggle.json'
100%|██████████████████████████████████████| 2.18M/2.18M [00:02<00:00, 1.05MB/s]
Successfully submitted to Planet: Understanding the Amazon from Space
Private Leaderboard score: 0.9296 (around 80th)
Collaborative Filtering on Movie Lens
所需library
所需library
from fastai.collab import *
from fastai.tabular import *
Collaborative filtering example
核心数据名称
核心数据名称
collab models use data in a DataFrame of user, items, and ratings.
user,item,title = 'userId','movieId','title'
下载数据
下载数据
path = untar_data(URLs.ML_SAMPLE)
path
PosixPath('/home/ubuntu/.fastai/data/movie_lens_sample')
查看CSV
查看CSV
ratings = pd.read_csv(path/'ratings.csv')
ratings.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 73 | 1097 | 4.0 | 1255504951 |
| 1 | 561 | 924 | 3.5 | 1172695223 |
| 2 | 157 | 260 | 3.5 | 1291598691 |
| 3 | 358 | 1210 | 5.0 | 957481884 |
| 4 | 130 | 316 | 2.0 | 1138999234 |
生成CollabDataBunch
生成CollabDataBunch
That’s all we need to create and train a model:
data = CollabDataBunch.from_df(ratings, seed=42)
设置y的区间,创建collab learner
设置y的区间,创建collab learner
y_range = [0,5.5]
learn = collab_learner(data, n_factors=50, y_range=y_range)
用lr=5e-3训练
用lr=5e-3训练
learn.fit_one_cycle(3, 5e-3)
Total time: 00:03
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 1.629454 | 0.982241 |
| 2 | 0.856353 | 0.678751 |
| 3 | 0.655987 | 0.669647 |
Movielens 100k
下载完整Movielens 100k数据集
下载完整Movielens 100k数据集
Let’s try with the full Movielens 100k data dataset, available from http://files.grouplens.org/datasets/movielens/ml-100k.zip
调取数据,查看CSV
调取数据,查看CSV
path=Config.data_path()/'ml-100k'
调取rating数据
调取rating数据
ratings = pd.read_csv(path/'u.data', delimiter='\t', header=None,
names=[user,item,'rating','timestamp'])
ratings.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 |
| 1 | 186 | 302 | 3 | 891717742 |
| 2 | 22 | 377 | 1 | 878887116 |
| 3 | 244 | 51 | 2 | 880606923 |
| 4 | 166 | 346 | 1 | 886397596 |
调取电影数据
调取电影数据
movies = pd.read_csv(path/'u.item', delimiter='|', encoding='latin-1', header=None,
names=[item, 'title', 'date', 'N', 'url', *[f'g{i}' for i in range(19)]])
movies.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| movieId | title | date | N | url | g0 | g1 | g2 | g3 | g4 | ... | g9 | g10 | g11 | g12 | g13 | g14 | g15 | g16 | g17 | g18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Toy%20Story%2... | 0 | 0 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | GoldenEye (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?GoldenEye%20(... | 0 | 1 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 3 | Four Rooms (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Four%20Rooms%... | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 4 | Get Shorty (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Get%20Shorty%... | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | Copycat (1995) | 01-Jan-1995 | NaN | http://us.imdb.com/M/title-exact?Copycat%20(1995) | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
5 rows × 24 columns
len(ratings)
100000
将rating和电影数据合并
将rating和电影数据合并
rating_movie = ratings.merge(movies[[item, title]])
rating_movie.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| userId | movieId | rating | timestamp | title | |
|---|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 | Kolya (1996) |
| 1 | 63 | 242 | 3 | 875747190 | Kolya (1996) |
| 2 | 226 | 242 | 5 | 883888671 | Kolya (1996) |
| 3 | 154 | 242 | 3 | 879138235 | Kolya (1996) |
| 4 | 306 | 242 | 5 | 876503793 | Kolya (1996) |
从合并的df中创建CollabDataBunch
从合并的df中创建CollabDataBunch
data = CollabDataBunch.from_df(rating_movie, seed=42, valid_pct=0.1, item_name=title)
data.show_batch()
| userId | title | target |
|---|---|---|
| 126 | Event Horizon (1997) | 1.0 |
| 44 | Young Frankenstein (1974) | 4.0 |
| 718 | Star Trek: First Contact (1996) | 4.0 |
| 506 | Magnificent Seven, The (1954) | 5.0 |
| 373 | Good, The Bad and The Ugly, The (1966) | 3.0 |
构建collab_learner
构建collab_learner
y_range = [0,5.5]
learn = collab_learner(data, n_factors=40, y_range=y_range, wd=1e-1)
寻找学习率,作图,选择最优值
寻找学习率,作图,选择最优值
learn.lr_find()
learn.recorder.plot(skip_end=15)
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
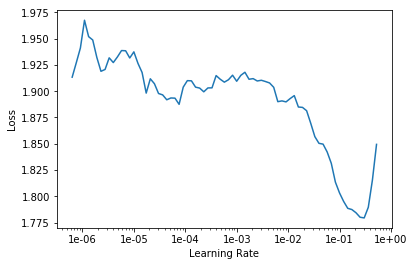
训练,保存
训练,保存
learn.fit_one_cycle(5, 5e-3)
Total time: 00:30
| epoch | train_loss | valid_loss |
|---|---|---|
| 1 | 0.923900 | 0.946068 |
| 2 | 0.865458 | 0.890646 |
| 3 | 0.783896 | 0.836753 |
| 4 | 0.638374 | 0.815428 |
| 5 | 0.561979 | 0.814652 |
learn.save('dotprod')
Here’s some benchmarks on the same dataset for the popular Librec system for collaborative filtering. They show best results based on RMSE of 0.91, which corresponds to an MSE of 0.91**2 = 0.83.
Interpretation 解读模型效果
加载模型
加载模型
learn.load('dotprod');
learn.model
EmbeddingDotBias(
(u_weight): Embedding(944, 40)
(i_weight): Embedding(1654, 40)
(u_bias): Embedding(944, 1)
(i_bias): Embedding(1654, 1)
)
获取每部影片的点评数量
获取每部影片的点评数量
g = rating_movie.groupby(title)['rating'].count()
从多到少排列前1000部电影,展示最高的10部
从多到少排列前1000部电影,展示最高的10部
top_movies = g.sort_values(ascending=False).index.values[:1000]
top_movies[:10]
array(['Star Wars (1977)', 'Contact (1997)', 'Fargo (1996)', 'Return of the Jedi (1983)', 'Liar Liar (1997)',
'English Patient, The (1996)', 'Scream (1996)', 'Toy Story (1995)', 'Air Force One (1997)',
'Independence Day (ID4) (1996)'], dtype=object)
Movie bias
如何获取movie bias
如何获取movie bias
movie_bias = learn.bias(top_movies, is_item=True)
movie_bias.shape
torch.Size([1000])
对每部电影评分取均值
对每部电影评分取均值
mean_ratings = rating_movie.groupby(title)['rating'].mean()
将movie_bias, title, 和评分均值排在一起
将movie_bias, title, 和评分均值排在一起
movie_ratings = [(b, i, mean_ratings.loc[i]) for i,b in zip(top_movies,movie_bias)]
将电影按movie_bias高低排列,从高到低,从低到高
将电影按movie_bias高低排列,从高到低,从低到高
item0 = lambda o:o[0]
sorted(movie_ratings, key=item0)[:15]
[(tensor(-0.3667),
'Children of the Corn: The Gathering (1996)',
1.3157894736842106),
(tensor(-0.3142),
'Lawnmower Man 2: Beyond Cyberspace (1996)',
1.7142857142857142),
(tensor(-0.2926), 'Mortal Kombat: Annihilation (1997)', 1.9534883720930232),
(tensor(-0.2708), 'Cable Guy, The (1996)', 2.339622641509434),
(tensor(-0.2669), 'Striptease (1996)', 2.2388059701492535),
(tensor(-0.2641), 'Free Willy 3: The Rescue (1997)', 1.7407407407407407),
(tensor(-0.2511), 'Beautician and the Beast, The (1997)', 2.313953488372093),
(tensor(-0.2418), 'Bio-Dome (1996)', 1.903225806451613),
(tensor(-0.2345), "Joe's Apartment (1996)", 2.2444444444444445),
(tensor(-0.2324), 'Island of Dr. Moreau, The (1996)', 2.1578947368421053),
(tensor(-0.2266), 'Barb Wire (1996)', 1.9333333333333333),
(tensor(-0.2219), 'Crow: City of Angels, The (1996)', 1.9487179487179487),
(tensor(-0.2208), 'Grease 2 (1982)', 2.0),
(tensor(-0.2151), 'Home Alone 3 (1997)', 1.894736842105263),
(tensor(-0.2089), "McHale's Navy (1997)", 2.1884057971014492)]
sorted(movie_ratings, key=lambda o: o[0], reverse=True)[:15]
[(tensor(0.5913), "Schindler's List (1993)", 4.466442953020135),
(tensor(0.5700), 'Titanic (1997)', 4.2457142857142856),
(tensor(0.5623), 'Shawshank Redemption, The (1994)', 4.445229681978798),
(tensor(0.5412), 'L.A. Confidential (1997)', 4.161616161616162),
(tensor(0.5368), 'Rear Window (1954)', 4.3875598086124405),
(tensor(0.5193), 'Star Wars (1977)', 4.3584905660377355),
(tensor(0.5149), 'As Good As It Gets (1997)', 4.196428571428571),
(tensor(0.5114), 'Silence of the Lambs, The (1991)', 4.28974358974359),
(tensor(0.5097), 'Good Will Hunting (1997)', 4.262626262626263),
(tensor(0.4946), 'Vertigo (1958)', 4.251396648044692),
(tensor(0.4899), 'Godfather, The (1972)', 4.283292978208232),
(tensor(0.4855), 'Boot, Das (1981)', 4.203980099502488),
(tensor(0.4769), 'Usual Suspects, The (1995)', 4.385767790262173),
(tensor(0.4743), 'Casablanca (1942)', 4.45679012345679),
(tensor(0.4665), 'Close Shave, A (1995)', 4.491071428571429)]
Movie weights
获取电影权重参数
获取电影权重参数
movie_w = learn.weight(top_movies, is_item=True)
movie_w.shape
torch.Size([1000, 40])
对电影参数matrix取PCA前3个特征值
对电影参数matrix取PCA前3个特征值
movie_pca = movie_w.pca(3)
movie_pca.shape
torch.Size([1000, 3])
将每部电影和它的第一特征值排在一起
将每部电影和它的第一特征值排在一起
fac0,fac1,fac2 = movie_pca.t()
movie_comp = [(f, i) for f,i in zip(fac0, top_movies)]
按第一特征值高低排序,从高到低,从低到高
按第一特征值高低排序,从高到低,从低到高
sorted(movie_comp, key=itemgetter(0), reverse=True)[:10]
[(tensor(1.2412), 'Home Alone 3 (1997)'),
(tensor(1.2072), 'Jungle2Jungle (1997)'),
(tensor(1.2000), 'Bio-Dome (1996)'),
(tensor(1.1883), 'Leave It to Beaver (1997)'),
(tensor(1.1570), 'Children of the Corn: The Gathering (1996)'),
(tensor(1.1309), "McHale's Navy (1997)"),
(tensor(1.1187), 'D3: The Mighty Ducks (1996)'),
(tensor(1.0956), 'Congo (1995)'),
(tensor(1.0950), 'Free Willy 3: The Rescue (1997)'),
(tensor(1.0524), 'Cutthroat Island (1995)')]
sorted(movie_comp, key=itemgetter(0))[:10]
[(tensor(-1.0692), 'Casablanca (1942)'),
(tensor(-1.0523), 'Close Shave, A (1995)'),
(tensor(-1.0142), 'When We Were Kings (1996)'),
(tensor(-1.0075), 'Lawrence of Arabia (1962)'),
(tensor(-1.0034), 'Wrong Trousers, The (1993)'),
(tensor(-0.9905), 'Chinatown (1974)'),
(tensor(-0.9692), 'Ran (1985)'),
(tensor(-0.9541), 'Apocalypse Now (1979)'),
(tensor(-0.9523), 'Wallace & Gromit: The Best of Aardman Animation (1996)'),
(tensor(-0.9369), 'Some Folks Call It a Sling Blade (1993)')]
同样方法,套用第二特征
同样方法,套用第二特征
movie_comp = [(f, i) for f,i in zip(fac1, top_movies)]
sorted(movie_comp, key=itemgetter(0), reverse=True)[:10]
[(tensor(0.8788), 'Ready to Wear (Pret-A-Porter) (1994)'),
(tensor(0.8263), 'Keys to Tulsa (1997)'),
(tensor(0.8066), 'Nosferatu (Nosferatu, eine Symphonie des Grauens) (1922)'),
(tensor(0.7730), 'Dead Man (1995)'),
(tensor(0.7513), 'Three Colors: Blue (1993)'),
(tensor(0.7492), 'Trainspotting (1996)'),
(tensor(0.7414), 'Cable Guy, The (1996)'),
(tensor(0.7330), 'Jude (1996)'),
(tensor(0.7246), 'Clockwork Orange, A (1971)'),
(tensor(0.7195), 'Stupids, The (1996)')]
sorted(movie_comp, key=itemgetter(0))[:10]
[(tensor(-1.2148), 'Braveheart (1995)'),
(tensor(-1.1153), 'Titanic (1997)'),
(tensor(-1.1148), 'Raiders of the Lost Ark (1981)'),
(tensor(-0.8795), "It's a Wonderful Life (1946)"),
(tensor(-0.8644), "Mr. Holland's Opus (1995)"),
(tensor(-0.8619), 'Star Wars (1977)'),
(tensor(-0.8558), 'Return of the Jedi (1983)'),
(tensor(-0.8526), 'Pretty Woman (1990)'),
(tensor(-0.8453), 'Independence Day (ID4) (1996)'),
(tensor(-0.8450), 'Forrest Gump (1994)')]
根据第一第三特征值的高低,将电影在平面上排列出来
根据第一第三特征值的高低,将电影在平面上排列出来
idxs = np.random.choice(len(top_movies), 50, replace=False)
idxs = list(range(50))
X = fac0[idxs]
Y = fac2[idxs]
plt.figure(figsize=(15,15))
plt.scatter(X, Y)
for i, x, y in zip(top_movies[idxs], X, Y):
plt.text(x,y,i, color=np.random.rand(3)*0.7, fontsize=11)
plt.show()
fastai part1 2019 中文版笔记视频的设想
为什么
- fast.ai是史上最务实最强大的深度学习课程
- 希望自己和更多国内小伙伴能因此受益
- 希望更多小伙伴参与到fast.ai深度学习的建设中来
是什么
- 课程知识点分解梳理+notebook 演示+中文讲解
目标
- 力争做到与英文课程内容高度一致和准确
- 作为精准贴切的中文字幕的另一种选择
效果
- 便捷搜索,方便复习的课程知识点集成
载体
- fast.ai 论坛, B站
难点
- 现在和未来能用来做视频的时间非常少
- 所以文字内容会多些,视频会留给特别内容和小伙伴邀请制作的内容。Thank you for your translation. I would like to ask if there is a Chinese communication group (QQ group or WeChat group). Some questions are convenient for communication. Thank you, the author, bother.
fast.ai 见闻
搜集在fast.ai世界里看到的值得关注的动态和见闻
insights from fastai team
interviews with DL heros
interview with Sylvain by Sanyam Bhutani thanks to @init_27
I simply copied the following Q&As from @init_27 's post above
How Sylvain got started with fastai?
I kind of forgot about it (neural net) until October 2017… I was curious to see how the field had progressed — of course, I had heard all the hype around it — so I followed the MOOC version 1…I instantly loved the top-down approach… I have a strong background in Math, but it’s my love for coding practical things that kept me going.
What is it like to work with Jeremy Howard?
We never sleep, but that’s mostly because we both have toddlers!..I’ve improved a lot as a coder and I keep on learning new things from him. Just seeing how he iterates through your code to refactor it in a simpler or more elegant way is always fascinating. And I really love how he is never satisfied with anything short of perfect, always pushing to polish this bit of code or this particular API until it’s as easy to use as possible.
Could you tell us more about your role at fast.ai and how does a day at fast.ai look like?
Since I am based in New York City, we mostly work in parallel. We chat a lot on Skype to coordinate and the rest of the time is spent coding or reviewing code, whether it’s to make the library better or try a new research idea.
As for my role, it’s a mix of reviewing the latest papers and see what we could use, as well as help Jeremy develop new functionality in the library and prepare the next course.
What more can we expect next from the awesome library?
we’ll try to make it easier to put fastai models into production, we’ll focus on the applications we didn’t have time to finalize during the first part of the course (object detection, translation, sequence labeling), we’ll find some way to deal with very big datasets that don’t always fit in RAM, and also play with some research ideas we didn’t get to investigate (training on rectangular images for instance).
How do you discover these ideas, what is the methodology of experimentation at fast.ai?
The methodology could be summarized into: “try blah!”, as Jeremy said in one of the courses. We try to have an intuitive understanding of what happens when training a given model, then we experiment all the ideas we think of to see if they work empirically.
Very often, research papers focus on the Math first and come with this one new theory that is going to revolutionize everything. When you try to apply it though, you often don’t get any good results. We’re more interested in things that work in practice.
How do you stay up to date with the cutting edge?
By experimenting a lot! The fastai library isn’t just a great tool for the beginner, its high flexibility makes it super easy when I want to implement a research article to see if its suggestion results in a significant improvement. The callbacks system or the data block API allow you to do pretty much anything with just a few lines of code.
any advice for the beginners?
Start a blog, where you explain what you have learned. Explaining things is often the best way to realize you hadn’t fully understood them; you may discover there were tons of small details you hadn’t dug enough into.
中文社区动态
meetups
上海meetup征集中, 2019.3.4开始的,thanks to @royam0820 ,上海的小伙伴有福气啊!meetup提供微信群和slack供大家交流。
开启GPU使用心得
技术应用
竞赛分享
JN 技巧分享
thanks to @stas tips and tricks
1 Like
You are welcome! What you want may be found in 中文社区动态 of the post below。