You shouldn’t be doing anything with opencv. Use fastai. Otherwise you won’t get the same processing. See the book for examples (e.g ch1 has an example of predicting from an image.)
1 Like
Thanks, Jeremy, will keep that in mind. Using the example from ch1, the input images are of arbitrary sizes which are then resized
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
I assumed that the example image used to test the prediction has a close enough shape (250,157), and hence it seems to work well. I did some further testing on this model by using extremely large images as inputs ((1500, 2500) without any resizing), and it seemed to predict just as well again!
Hence, I was wondering why such a discrepancy exists? Is it because one is trained for classification, whereas the other (the one from ch6) is essentially a regression model (and outputs definite x and y coordinates) and is more dependent on input image size?
Sorry what discrepancy are you referring to exactly?
Apologies, perhaps discrepancy was the wrong word to use there. What I’m referring to is that:
The model in ch1 seems to be able to make predictions on an image (of a much larger size) accurately even though the files used for training have been resized to smaller images.
The model in ch6 is trained similarly (i.e. the images used for training have been resized), but the visible accuracy (i.e. when the dot indicating the head_center is overlayed on the input image) is off by quite a bit if the input image size does not match the size of the images used for training.
Upon pondering on that a bit further it makes sense that the later model is trained to predict an (x,y) coordinate with respect to its (training image) size, hence failing when a larger image is passed to it. I presume the predicted (x,y) can be corrected possibly by scaling the prediction proportionally by the change in the size of the input image to that of the training image.
Using a terminal on Paperspace, I have hidden lines at the bottom of the terminal that I can’t access.
For example, here I entered the number 1 to 13, but the terminal didn’t scroll until 13 was entered, which remains offscreen. I’ve tried F11 to full-screen chrome, and also dragging the divider higher. These helped adding some lines, but not enough. Is there anything else I can do to see the bottom of the terminal?
p.s. What is annoying is the wasted space above the terminal.
1 Like
Don’t use the Paperspace IDE thingie. Use JupyterLab. Bottom button on far-left of screen.
2 Likes
Ah! My misconception was that JupyterLab was just for the Python stuff, and Terminals were common for PaperSpace IDE and JupyterLab. Lately while doing just terminal work I had stopped booting into JupyterLab. If you have an ear at Paperspace, perhaps there could be a setting at Instance Creation to boot straight into JupyterLab, or something we can do in our pre-run.sh to JupyterLab the default.
I notice this at the bottom of /run.sh…
jupyter lab --allow-root --ip=0.0.0.0 --no-browser --ServerApp.trust_xheaders=True --ServerApp.disable_check_xsrf=False --ServerApp.allow_remote_access=True --ServerApp.allow_origin='*' --ServerApp.allow_credentials=True
1 Like
I (and many others) have tried to explain to them that we’re not fond of their GUI, but they seem to be pretty convinced that we ought to be, and it’s just a matter of time until we see the light…
3 Likes
I’m curious about resamples parameter of class Resize, when is it beneficial to use a different algorithm for pillow image and for mask?
I can only hazard a guess… that the mask doesn’t need so much detail as the image, so NEAREST is sufficient and cheaper.
Segmentation masks need to be integers, and using NEAREST is a good way to ensure that.
(FYI this isn’t a beginner question (it’s not covered in the course).)
1 Like
I’m doing some binary segmentation with unet_learner based on @muellerzr awesome notebook here: walkwithfastai.github.io/04_Segmentation.ipynb at master · walkwithfastai/walkwithfastai.github.io · GitHub
I added a similar accuracy metric, however some of the images have only Void for the mask which is resulting my code getting a NaN.
I changed it to return nan_to_num, however I am unsure what the correct value would be in that case? Should I be going to 0 or 1, if there are predictions and its empty thats a perfect score so it should be a 1 right?
def get_metrics(void_code: int = 0) -> List:
def acc_dfu(inp, targ):
targ = targ.squeeze(1)
mask = targ != void_code
result = (inp.argmax(dim=1)[mask]==targ[mask]).float().mean()
return result.nan_to_num()
return [acc_dfu, Dice]
Also, is this accuracy metric a bit useless given I am also using Dice? Should I just stick with Dice?
Also this is the lr_find im seeing, what do people suggest I use and should I use a slice or use a single lr and ReduceLROnPlateau with SaveModelCallback or EarlyStoppingCallback instead?
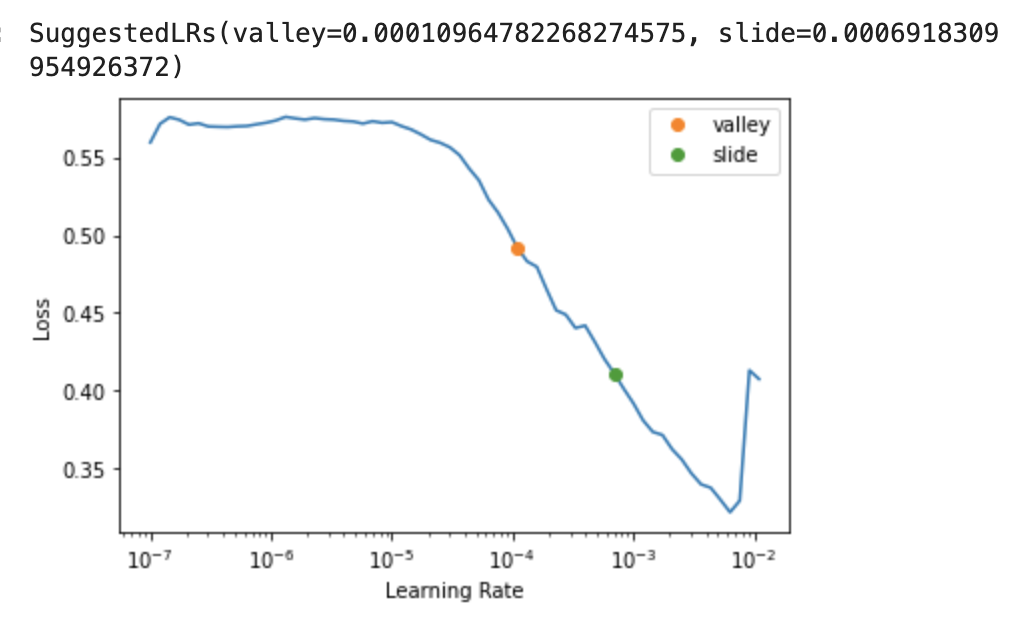
I get the impression that once your model has started to overfit (valid_loss going back up), there isn’t really any way to go back, so its best to use an earlier snapshot or try again?
I found a question in the public forum that I found interesting and on the cusp of being able to answer. Could someone with more experience follow up my response to this post…
In the Kaggle leaderboard I see a very few lines with the angle brackets I’ve boxed in red.
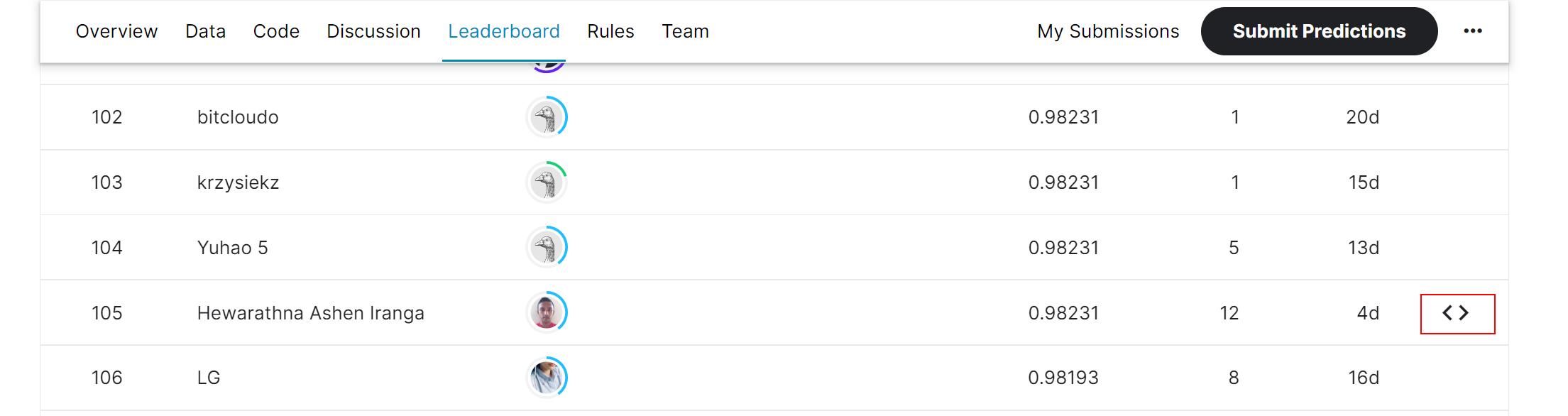
I’m curious where this comes from. Hovering over it looks like this…
1 Like
I think they are submissions from a notebook.
1 Like
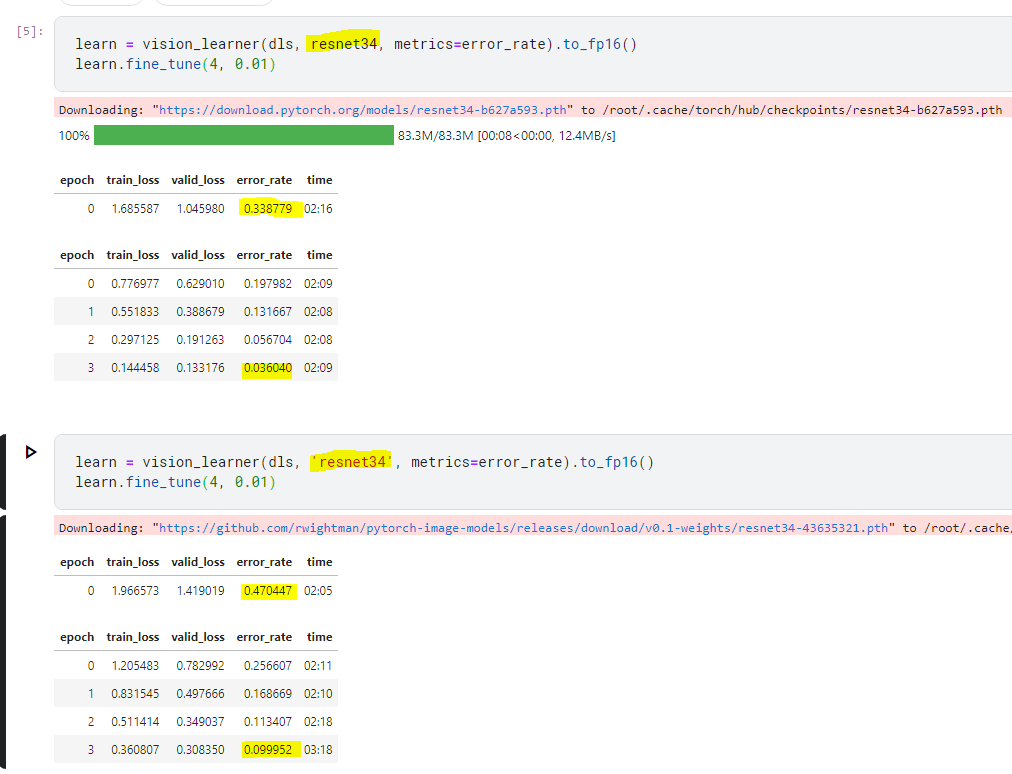
I have been noticing some considerable differences in accuracy between passing 'resnet34' and resnet34 to the vision_leaner.
Each of the options downloads the model from different repositories:
-
resnet34
Downloading: “https://download.pytorch.org/models/resnet34-b627a593.pth” -
'resnet34'
Downloading: “https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/resnet34-43635321.pth”
Shouldn’t both of them be the same model?
Thanks
1 Like
No, if you use a string, you are using timm models, whereas without the string you’re getting a torchvision model.
2 Likes
Hi, I need advice on how to handle large image files. I thought it’d be fun to try training a vision model with the data from this Kaggle competition: Mayo Clinic Strip AI. However, I am unable to do anything with the images without getting this error on my Kaggle notebook: “Your notebook tried to allocate more memory than is available.”
The images are high-resolution pathology slides (provided in TIFF format) ranging in size from 7 - 2829 MB. I have tried creating a DataBlock with a Resize method and using resize_image() to first save a a set of smaller images. I also tried using the following function to no avail:
def resize_and_save_images(filepath):
img = PILImage.create(filepath)
w, h = resize_to(img, 512)
img_resized = img.resize((w,h), resample=Image.Resampling.LANCZOS)
filename = filepath.stem + '.jpg'
img_resized.save(filename)
I run out of memory and my notebook gets restarted every time. Any tips would be appreciated!
Pathology slides are so large that they not always can be opened with regular tools. By the way, if you resize to 512, you loose almost all microscopic information. The typical pipeline involves transforming the slide to (a lot of) tiles, sized appropriately for further processing, and then reconstructing from predictions.
1 Like
Hello colleagues.
Need some help with rather broad question. I have some sample data in a form of files. They are categorized in two category - [‘benign’, ‘malicious’]. To prepare the data for Resnet learner I apply some basic function which turns contents of a file into 64x16 tensor of digits:

So. i have all set:
db = DataBlock(
blocks=(RegressionBlock, CategoryBlock),
get_items=get_train_files,
splitter=RandomSplitter(),
get_y=label_func,
get_x=extract_features
)
db.summary seems to say me everything is OK.
Setting-up type transforms pipelines
Collecting items from /mnt/ramdisk/data
Found 90000 items
2 datasets of sizes 72000,18000
Setting up Pipeline: extract_features -> RegressionSetup -- {'c': None}
Setting up Pipeline: label_func -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
Building one sample
Pipeline: extract_features -> RegressionSetup -- {'c': None}
starting from
/mnt/ramdisk/data/malicious_files/training/82c5b186a102632fb40c2bf89e9f0c68b229768d6e5e11e7fc0827171589a56f.utf8
applying extract_features gives
Tensor of size 16x64
applying RegressionSetup -- {'c': None} gives
Tensor of size 16x64
Pipeline: label_func -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
starting from
/mnt/ramdisk/data/malicious_files/training/82c5b186a102632fb40c2bf89e9f0c68b229768d6e5e11e7fc0827171589a56f.utf8
applying label_func gives
malicious
applying Categorize -- {'vocab': None, 'sort': True, 'add_na': False} gives
TensorCategory(1)
Final sample: (tensor([[0., 1., 0., ..., 0., 1., 1.],
[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 1., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]), TensorCategory(1))
Collecting items from /mnt/ramdisk/data
Found 90000 items
2 datasets of sizes 72000,18000
Setting up Pipeline: extract_features -> RegressionSetup -- {'c': None}
Setting up Pipeline: label_func -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
Setting up after_item: Pipeline: ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline:
Building one batch
Applying item_tfms to the first sample:
Pipeline: ToTensor
starting from
(Tensor of size 16x64, TensorCategory(1))
applying ToTensor gives
(Tensor of size 16x64, TensorCategory(1))
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
No batch_tfms to apply
But when I launch actual training I receive some exception which is beyond my understading.
learn = vision_learner(test, resnet18, metrics=error_rate)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [24], in <cell line: 1>()
----> 1 learn = vision_learner(test, resnet18, metrics=error_rate)
2 learn.fine_tune(1)
File ~/.local/lib/python3.9/site-packages/fastai/vision/learner.py:225, in vision_learner(dls, arch, normalize, n_out, pretrained, loss_func, opt_func, lr, splitter, cbs, metrics, path, model_dir, wd, wd_bn_bias, train_bn, moms, cut, init, custom_head, concat_pool, pool, lin_ftrs, ps, first_bn, bn_final, lin_first, y_range, **kwargs)
223 else:
224 if normalize: _add_norm(dls, meta, pretrained)
--> 225 model = create_vision_model(arch, n_out, pretrained=pretrained, **model_args)
227 splitter=ifnone(splitter, meta['split'])
228 learn = Learner(dls=dls, model=model, loss_func=loss_func, opt_func=opt_func, lr=lr, splitter=splitter, cbs=cbs,
229 metrics=metrics, path=path, model_dir=model_dir, wd=wd, wd_bn_bias=wd_bn_bias, train_bn=train_bn, moms=moms)
File ~/.local/lib/python3.9/site-packages/fastai/vision/learner.py:167, in create_vision_model(arch, n_out, pretrained, cut, n_in, init, custom_head, concat_pool, pool, lin_ftrs, ps, first_bn, bn_final, lin_first, y_range)
165 body = create_body(model, n_in, pretrained, ifnone(cut, meta['cut']))
166 nf = num_features_model(nn.Sequential(*body.children())) if custom_head is None else None
--> 167 return add_head(body, nf, n_out, init=init, head=custom_head, concat_pool=concat_pool, pool=pool,
168 lin_ftrs=lin_ftrs, ps=ps, first_bn=first_bn, bn_final=bn_final, lin_first=lin_first, y_range=y_range)
File ~/.local/lib/python3.9/site-packages/fastai/vision/learner.py:153, in add_head(body, nf, n_out, init, head, concat_pool, pool, lin_ftrs, ps, first_bn, bn_final, lin_first, y_range)
151 "Add a head to a vision body"
152 if head is None:
--> 153 head = create_head(nf, n_out, concat_pool=concat_pool, pool=pool,
154 lin_ftrs=lin_ftrs, ps=ps, first_bn=first_bn, bn_final=bn_final, lin_first=lin_first, y_range=y_range)
155 model = nn.Sequential(body, head)
156 if init is not None: apply_init(model[1], init)
File ~/.local/lib/python3.9/site-packages/fastai/vision/learner.py:100, in create_head(nf, n_out, lin_ftrs, ps, pool, concat_pool, first_bn, bn_final, lin_first, y_range)
98 if lin_first: layers.append(nn.Dropout(ps.pop(0)))
99 for ni,no,bn,p,actn in zip(lin_ftrs[:-1], lin_ftrs[1:], bns, ps, actns):
--> 100 layers += LinBnDrop(ni, no, bn=bn, p=p, act=actn, lin_first=lin_first)
101 if lin_first: layers.append(nn.Linear(lin_ftrs[-2], n_out))
102 if bn_final: layers.append(nn.BatchNorm1d(lin_ftrs[-1], momentum=0.01))
File ~/.local/lib/python3.9/site-packages/fastai/layers.py:179, in LinBnDrop.__init__(self, n_in, n_out, bn, p, act, lin_first)
177 layers = [BatchNorm(n_out if lin_first else n_in, ndim=1)] if bn else []
178 if p != 0: layers.append(nn.Dropout(p))
--> 179 lin = [nn.Linear(n_in, n_out, bias=not bn)]
180 if act is not None: lin.append(act)
181 layers = lin+layers if lin_first else layers+lin
File ~/.local/lib/python3.9/site-packages/torch/nn/modules/linear.py:85, in Linear.__init__(self, in_features, out_features, bias, device, dtype)
83 self.in_features = in_features
84 self.out_features = out_features
---> 85 self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
86 if bias:
87 self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
TypeError: empty() received an invalid combination of arguments - got (tuple, dtype=NoneType, device=NoneType), but expected one of:
* (tuple of ints size, *, tuple of names names, torch.memory_format memory_format, torch.dtype dtype, torch.layout layout, torch.device device, bool pin_memory, bool requires_grad)
* (tuple of ints size, *, torch.memory_format memory_format, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool pin_memory, bool requires_grad)
Help please.
1 Like
Something telling me this is due to data size of 16X64, but have no idea what to do with it.