If you’ve got a beginner question but aren’t sure where else to post it, pop it in here!
I have a question about using the Jupyter notebook / Kaggle notebooks for running and trying multiple algorithms on same data.
For example, I did try the first problem like “Classifying Objects” Now I see that with resnet18 my model is giving lets say 50% accuracy and then now I want to try each model like resent50d or 34d and few more.
Question: Should I use same jupyter notebook and create a new cell below it and do the same block of code again like below:
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
learn = vision_learner(dls, resnet50d, metrics=error_rate)
learn.fine_tune(3)
Or should I just replace the algorithm name in the first piece of code and use it. Or should replicate the notebook for every algorithm try. The reason I am asking this because, I want to track the data. My first model is giving me 36% accuracy. So, I think over a period of trying different algorithms I might loose the sight of results.
Notebook reference: Classifying Planetary Objects | Kaggle
Sorry if it’s a silly question?
There are no silly questions 
My recommendation would be to add them as cells underneath, because I think it’s helpful to maintain a log of what you’ve tried and what the results were.
3 Likes
Okay thank you Jeremy. I am little late so trying out and reading the first 2 lessons.
In my case I am getting only 35% accuracy and as I am trying alternatives, it is going further down, I guess the data is the issue. I tried manually checking the data, there is lot of invalid images as well coming in the data that are classified as planets etc. I think it needs a lot if preprocessing. I am not sure if we have any future lessons that cover this topic. But I want to now try more techniques from lesson 2. Any suggestions on data cleanup?
1 Like
For data cleanup I suggest using the approach I showed in lesson 2.
1 Like
I have a couple of questions about the fastai docs
-
Where are the notebooks for the tutorials in docs.fast.ai . For example the Tabular tutorial. Would it be possible to put the link to the notebook in the tutorial on the docs website (it’s quite possible I have missed this)
EDIT- NVM I just saw the “open in colab” button doh!!! -
What is the fastai/dev_nbs/course part of the repo for?
1 Like
Click “open in Colab” at the top of that page to open the notebook. Here it is in the repo: fastai/nbs/44_tutorial.tabular.ipynb at master · fastai/fastai · GitHub
That’s an old version of the course that used fastai1 – @sgugger translated those notebooks to fastai2 both for testing and to help students transition.
2 Likes
For those of you using Kaggle, is it possible to save the downloaded data (from download_images) in the session to make your own dataset? I’ve tried committing my notebook and I don’t see any exported data.
Notebook link:
Can you share a link to your public notebook so we can take a look?
Yup. Just added that to my post. I would expect it to populate with data here similar to what it does when you export a model.
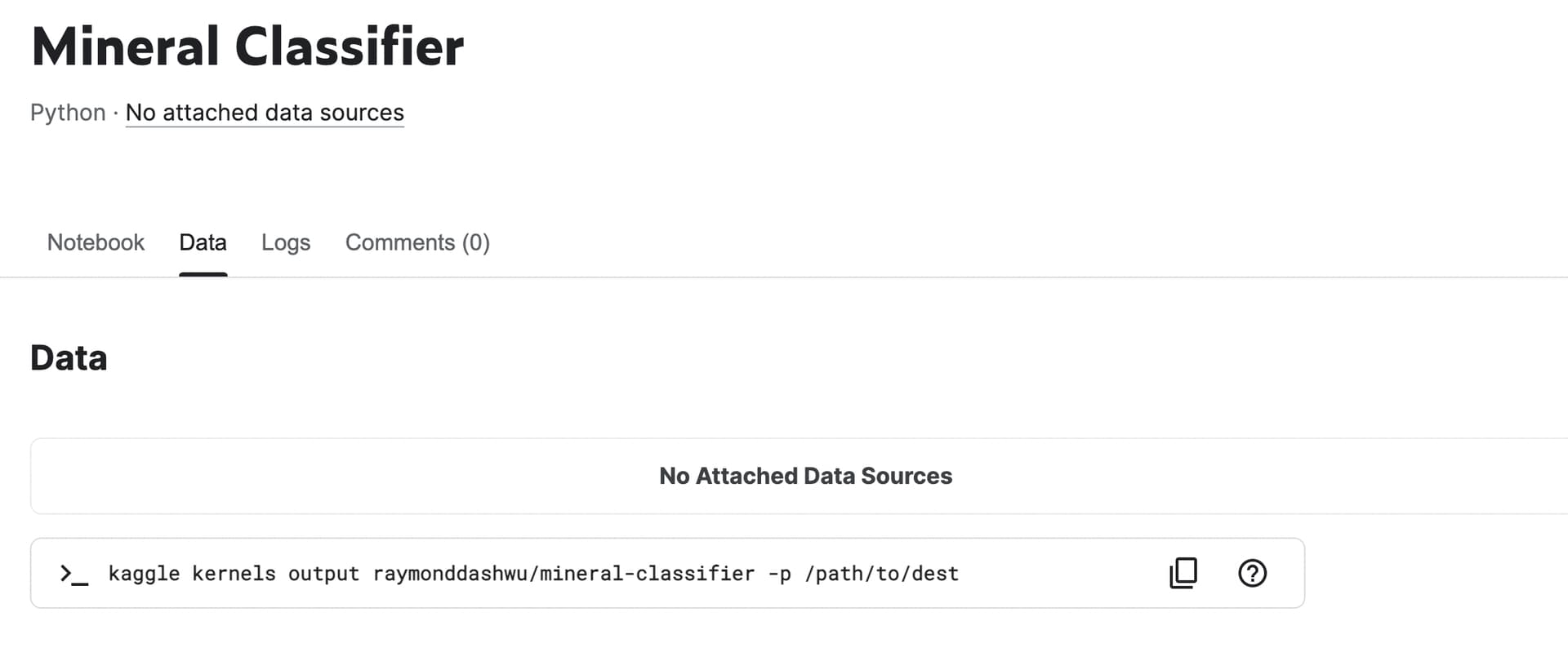
I’m guessing you turned off the option which re-runs the notebook when you save. Therefore nothing has been run – it says at the top of your notebook it was run in 5.7s, which suggests to me the code didn’t run at all.
Oh that’s a good point. I forgot I was testing out Kaggle’s new (to me) quick save option. Will try a “Save & Run All” and see if that fixes it.
1 Like
If your downloaded directory is : /kaggle/working/mydata you can do it like this:
#zip it up
!zip -r mydata.zip /kaggle/working/mydata
# see if the file is there
!ls -lrt | tail
# get a link to it
from IPython.display import FileLink
FileLink(r'mydata.zip')
The last cell will print an html link in the output, click on it, it will download to your desktop.
2 Likes
Thank you Jeremy.
On 02_production.ipyth notebook, I want to download images from using the Bing image search. I have a MS azure account already, but when I try to create a Bing search resource, the pricing tier shows “no available items”. Is there another way for getting my Azure search key?
Thanks!
Please don’t use azure you can download from duck duck go which doesn’t require a key. if you search for image_search_ddg on the forums you’ll find the code to do that
HTH
Below is from Jeremy’s Bird detector example on Kaggle (he demo’d it in the lecture)
from fastcore.all import *
import time
def search_images(term, max_images=200):
url = 'https://duckduckgo.com/'
res = urlread(url,data={'q':term})
searchObj = re.search(r'vqd=([\d-]+)\&', res)
requestUrl = url + 'i.js'
params = dict(l='us-en', o='json', q=term, vqd=searchObj.group(1), f=',,,', p='1', v7exp='a')
urls,data = set(),{'next':1}
while len(urls)<max_images and 'next' in data:
data = urljson(requestUrl,data=params)
urls.update(L(data['results']).itemgot('image'))
requestUrl = url + data['next']
time.sleep(0.2)
return L(urls)[:max_images]
1 Like
3 posts were merged into an existing topic: Non-Beginner Discussion
Thanks Mike for the help! I was searching for that too.
1 Like
If I’ve done learn.fine_tune(3)
and then looking error_rate decide I want to do a few more epochs of training,
is there a way to continue from where that finished… i.e. learn.fine_tune_more(3)
rather than needing a full restart, like… learn.fine_tune(6).
Hi team, how would transcription engine works? I assumed they grab audio, and use something to get spectrogram maybe something like librosa and then some how converting each sound to an image, then run it through a model to predict a letter from the image.
maybe using a different model to create word based on the letter and pauses.
I know this is not 100% AI question ![]() sorry about that.
sorry about that.
I did lots of research on that which ended up no where.
Will someone be able to put me in the right direction? Thanks