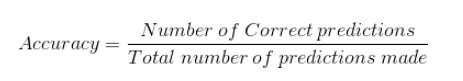I think that when you call learn.fine_tune(6) after having already run learn.fine_tune(3) the model will actually not retrain from scratch but start with the already fine-tuned weights. So unless you create the learner again, e.g. by calling learn = vision_learner(...) the model actually continues training.
Another question is what’s the best way to continue fine-tuning (how many epochs, which learning rate, how to handle learning rate schedule etc.). I am not 100% sure about what’s the answer to that, but you might want to try learn.fit_one_cycle(...) instead of learn.fine_tune(...) to continue training. I’m sure Jeremy will cover these concepts in detail in the upcoming lessons.
@jeremy
Thank you for your response, I didn’t know where to ask that question hence I asked it here.
do you have any document or reference that I can study this? I am hoping to work on this as my fast.ai project.
Or which thread do you want me to ask this question?
I’m not sure it’s an ideal project if you’re a beginner - it’s generally something I’d recommend after a year or so of deep learning study and practice. The problem I’ve seen with really bold starting projects is a see few students finishing them.
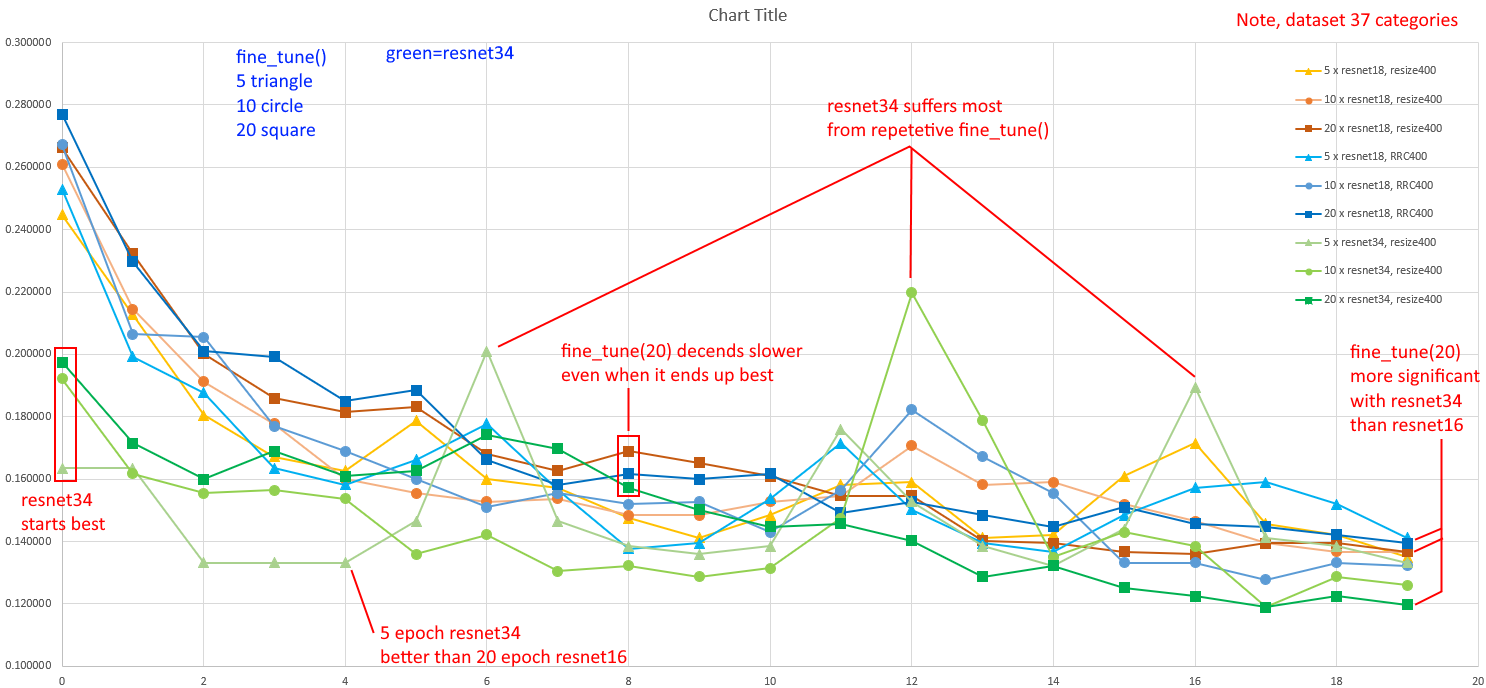
I did some experimenting with the hyper-parameters (if that is the correct terminology) of my Which Watersport project (code on kaggle) to develop my sense of their effect. While recognising this is a pinhole view from a single use case (a dataset with 37 categories), it examines:
successive application of multiple fine_tune_ing
comparing 4 x fine_tune(5), 2 x fine_tune(10), 1 x fine_tune(20)
comparing resnet16 versus resnet34
comparing resize(400) versus random_resize_crop(400)
The progressive epoch error is visualised in this chart, which I’ve annotated with a few features…
Raw data is in google sheet here. (Note, chart actually generated in Excel since it has a better charting tool) On thing that initially struck me as really bizzare is the great amount of six-decimal-place-numbers that are repeated. I’ve since speculated that the 20% size of the validation set means there are only some many combinations of fractions formed by this equation…
Another curious thing looking at the [resnet34 RRC150] tab, is that
RandomResizedCrop(150) with resnet18 performed much worse than the others.
I am wondering if the crop size might be too small, so too many irrelevant images containing only water are processed??
And that leads me to wondering… Lesson Three [20:48] indicates that the transformes done during training are repeated during inference processing. Is it possible that RandonResizedCrop is causing inferencing to be performed on crops containing only water, which would be really hard to classify to a pariticular sport??
I really like the Wes McKinney book mentioned by Jeremy and I’ve been trying to go through it along with Jake VanderPlas’s book. I really would like some resource that takes a dataset and goes through a project and during that process, it uses various features of these libraries to accomplish those tasks. The book is more a reference type book which describes various capabilities of the library quite well, but for beginners the problem is two fold: learning the moving parts of the library and applying that to a goal-oriented project type problem.
I remember taking the John’s Hopkins course on Data Science and I found it really helpful that I learned R while in the process of trying to do various class assignments. Their approach was to ask students to do small tasks using R and those tasks built up to a data product over the course of the few weeks as we progressed towards the final problem/project to be solved.
P.S. Daniel Chen has been doing some really great Pandas tutorial videos but for some reason most of these things quickly devolve into: “This function does this… to get the 0th axis you call this function” without telling me why the heck would I need to get the 0’th access to begin with and what problem should I apply this reference information to. Not knocking it, it’s just super difficult for experts to get back into the beginner mindset despite trying really hard to help beginners.
One of my favourite AI youtube channels Two Minute Papers
indicates Weights and Biases provides useful insight into NN training. Has anyone used this? (note, they are his sponsor)
btw, here is one of my all time favourite vids from the channel…
Hi! I am applying DL to clinical prediction research with x-ray and clinical data. As clinicians, we have to have more than one thing (x-ray, lab result, or clinical observation) to diagnose. I want to do the same with DL by adding the layer (layer may not be the right term… perhaps a different prediction model ensembled together) of prediction from clinical data and the layer from lab data onto the x-ray prediction. Is there any good example webpage where I can start understanding how to do this?
Thanks!!
We used matrix multiplication in our linear models and in Excel implementation as well.
However, in some literature I have encountered “dot product”. Are they the same for our use or are there any scenarios where one makes more sense than the other? I am a bit confused on this one. Should/can I just ignore “dot product” and use matmul everywhere?
Is there a way to resume training (say, fine-tuning) after a prescribed amount of epcohs? I’ve encountered a solution on the forum from the 2020 group mentioning using SaveModelCallback and saving (and then loading) the model. Is this the “right” way to do it?
Thanks!! So, a matmul is repeated dot products over all rows and columns!! Hah!! That’s why np.dot and @ operator both give the same answer for 1-D arrays.
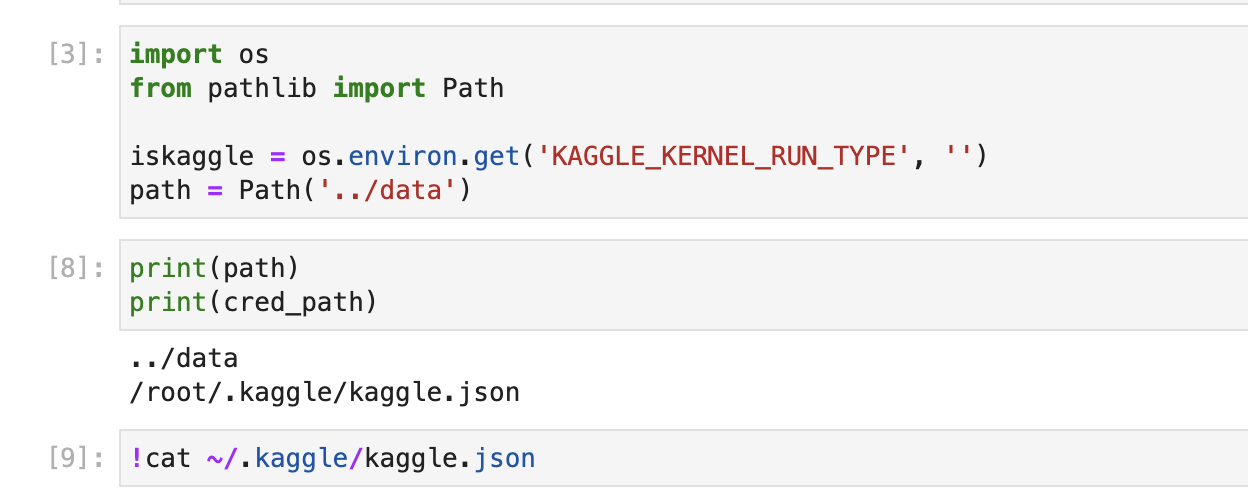
I am working with Paperpace Gradient and had previously been able to connect to Kaggle following the instructions here using the default fastbook repository in the Paperspace + Fastai recommendation.
Wanting to clone the course22 repo I created a new notebook pointing to the course22 repo on a different machine using the same Paperspace + Fastai image and attempted to follow the same process to load my Kaggle API key. I can see the .kaggle folder and cat into the json to confirm that it is there. When I run the following cells I see the contents of the json exactly matching my API key.
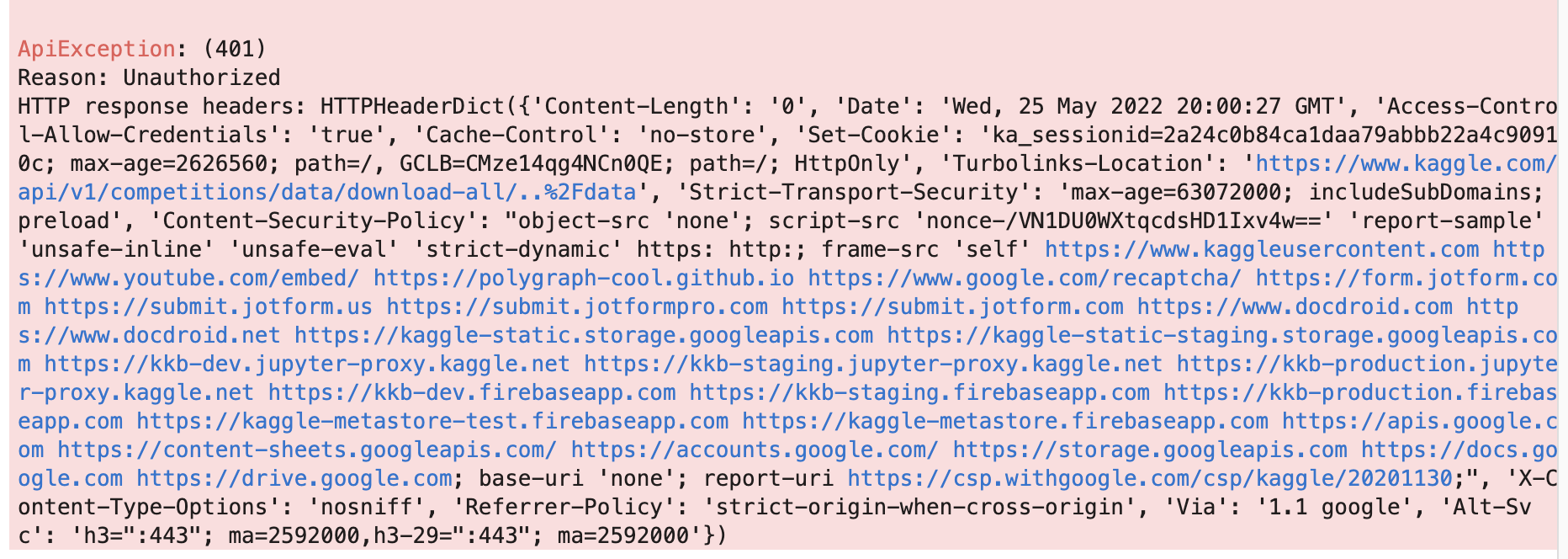
I’ve tried deleting the ~/.kaggle folder and repeating the process, restarting the kernel but still hitting this error. Not sure how to proceed from here so I would be grateful for any suggestions on things to try.
You’re setting path to ../data then converting it to a string and asking kaggle api to download it. Does a dataset name data.zip exist on the kaggle side?
in the notebook you linked to, path is set as follows:
Ok that set me straight. Thanks Mike! I just needed to read the actual code from the lecture and make some adjustments to the code I imported from the course22 git repo. I was using path and the cloned code blindly without thinking!
I made the same mistake actually. What confused me was that the path variable is used both for the path and the dataset name. Glad it worked out for you!