I found an Auto Close Brackets setting you can change but would be nice for this to be automatic (probably others prefer it this way…)
3 Likes
Yeah classic Jupyter Notebooks works this way. Much nicer IMO
1 Like
That’s called a “multi-modal” model. It’s not the kind of thing you can learn from a single web-page – but it is something we should get to in the course (in part 2). You’ll need to, at a minimum, have finished reading the book to have the prerequisite knowledge to work on this, so keep reading a practicing!
3 Likes
Hello all,
I’m having trouble with my latest image classification model. I’m trying to classify if an image has an ev charger or bike rack in the photo. It’s typically dash cam images so the actual classes are a small part of the photo. It scores very well when it comes to training. However, when I test it on an image from the actual dataset (last part of the notebook) it doesn’t work! Any advice?
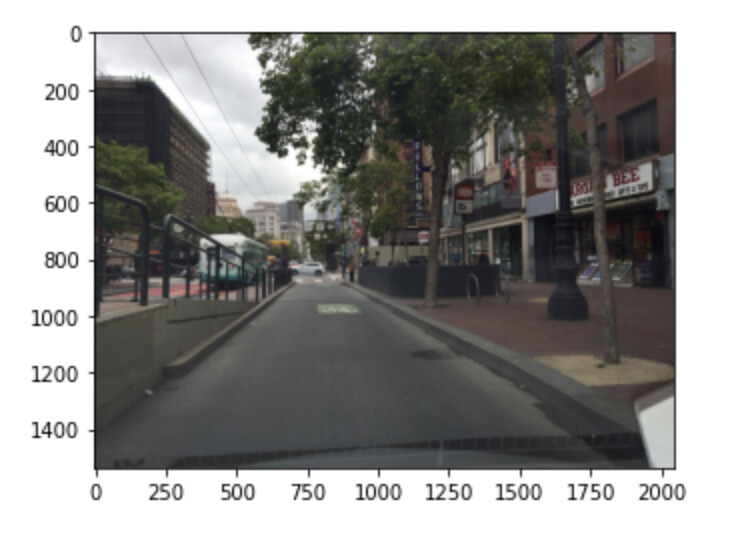
Honestly, I’m having trouble figuring out what the last two pictures are. I mean, I see a Nissan EV in the 2nd pic, but it could just be a parking spot. The 3rd one just seems to be the picture of a street.
In most animal vision, I think there’ a huge component that is attention. When we get the scene in our head, we probably have lots of circuits which filter things out and “attend to” the object we’re searching for. In a scene this large, I’m not sure if the network would be able to figure out if anything resembling a an ev charger or a bike rack is present. I for one can’t figure out (in pic 3).
dependes on the use case though. If the use case is to classify dashcam images, then I’d build my data set in such a way that those types of images are present in the training/validation data. And maybe collect more data too.
1 Like
Hey, I’m using Paperspace and I’m looking for a keyboard shortcut for entering code below or anything of the sort. Any idea how to use PaperSpace more smoothly? Thanks
Try watching the walkthru 3 video, and then let us know if that doesn’t answer your question.
1 Like
Images 1 and 3 are of bike racks. It’s easily viewable (in my opinion) on the full size image. I can understand it being hard to distinguish at the size in the notebook. My understanding is that I’m calling learn.predict on the full sized image as I’m not doing anything to resize it. If that assumption is incorrect, please let me know.
Otherwise I’ll try again with more data. I wasn’t able to find a dash cam dataset with those labels (checked COCO, cityscapes, KITI) so I’ll likely have to make my own
You’re doing preprocessing on the test image that you’re not doing on the training images. You need to use the exact same steps for each.
1 Like
I’m not 100% sure what that refers to. I think you’re talking about my most recent version where I have a full sized image and then manually cut out the bike rack?

If that’s the case, that was just to test the hypothesis that mike presented. It seemed to give a better result and increased confidence. I’d love to use the heatmap feature that was in previous iterations of the course to make sure. However, I can’t seem to find it in the documentation anymore so I’m guessing it got deprecated?
Due to a lack of a better dataset (surprisingly bike racks aren’t a class in COCO, Cityscapes, BDD, or KITTI), segmentation masks, etc. I’m just going to naively split each image into parts and do inference on each. That way it’ll be close to the type of images I’m using in my training data. Something like this:
1 Like
No, I’m referring to this code:
img = np.array(Image.fromarray((img * 255).astype(np.uint8)).resize((2048, 1536)).convert('RGB'))
You don’t use that approach to process the input images for your model, so you shouldn’t use it at inference time.
Your model is already very accurate. You can see that from the error rate on the validation set when training. Assuming that the dataset your using has similar images to the test images, you should get the same result when doing inference. So I’m guessing that you’re not getting good results because of the processing step above.
OTOH, if your training images are actually very different to what you’re testing on, then you need to change your training set such that includes the same kind of images you want to use for inference.
2 Likes
Ah, I hadn’t even thought about my code here. I just modified it because there was a shape error with one of the images I had been using.
I think the issue is more that my training images are substantially different than my test images rather than the line of code above. Unfortunately I can’t find a good way to search for dash cam footage featuring a bike rack or EV charger so I’m probably going to lean on my naive split I mentioned earlier. That’ll hopefully get an image where the majority of it will feature one of my classes when it comes time to do a prediction.
1 Like
Thank you, Jeremy! I hope I can still tag along (will do my best!).
It’s a very important problem to solve, and I’m sure you’ll get there. It might take 6-12 months of study to build up the expertise required, which I’m sure will be worth it. Hope you stick with the course/book through to the end so we can see what you build! ![]()
1 Like
I need some help.
- In a first project, I could segment a really small structure of the inner ear (the utricular macula), based on one MR sequence and got decent results with a DCS of 0.76 on the validation set.
- Now I would like to segment adenomas of the parathyroid glands, where I have to first label the pathology in more than one MR Sequences, one sequence will be a dynamic one(the most important one). The sequences will have different orientations, resolution etc.
Now I feel a little bit lost where to start, how to handle the different sequences etc. A little guidance is more than welcome;-).
Hello, is anybody else having major issues with setting up images on Paperspace? It’s been stuck on “setting up machine” for 15 minutes now… and the only other option that’s working for me is completely deleting the server and starting a new one from scratch (been doing that for a few days now). I can’t seem to shut it down either.
Yup had the same problem yesterday. Seems like they had an outage. I’ve emailed them to see what’s up.
2 Likes
[quote="jeremy, post:76, topic:96284]
You don’t use that approach to process the input images for your model, so you shouldn’t use it at inference time.
[/quote]
I’m a bit confused with this statement in regards to passing images to a Dataloader object and prediction.
For instance, I was working through fastbook: chapter 6, in which the following block of code is used to create the Dataloader
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name==‘13’),
batch_tfms=aug_transforms(size=(240,320)),
)
The model trains well (as seen in the book), however, it fails to predict correctly when testing it out on say an image of myself taken from my laptop webcam (closely resembling the images seen in the training test). The following code was used during prediction
img = cv2.imread(‘my_image.jpg’)
dim = (320,240)
frame = cv2.resize(frame, dim, interpolation = cv2.INTER_AREA)
model_export = load_learner(‘headmodel.pkl’,cpu=False)
p = tensor(frame)
headloc,_,probs = model_export.predict(p)
headloc = np.array(headloc)
headloc = (int(headloc[0][0]),int(headloc[0][1]))
frame = cv2.circle(frame, headloc, 1, color, thickness)
My question is, should I be resizing my image? If yes should it be to that of the original dataset (original training image dimensions), or to the size of the aug_transforms (implying that the size in this case should be (240,320)) ?
Hi @Rkap , are the two dimensions functionally equivalent? ie (240,320) in (1) same as (320,240) in (2) ???
i.e., does 240 in (1) represent the same dimension it does in (2) ?? looks like they are flipped but that may be because of the order in which the two different functions accept their arguments.
Yes, they essentially represent the same image, i.e. I made sure the length matches up with the length passed in aug_transforms, and the height matches up with the height.