I do think you are on the right track with your assumption about the size of the data being the problem. The default resnet18() can not handle a batch of size 16x64. Additionally, the default resnet18() expects a three dimensional image.
If you were to ensure that the input sample had the dimensions of [batch_size, 3, 16, 64] – the forward pass on the model should work just fine. You can confirm this by trying to run the few lines below:
model = resnet18()
x = torch.ones(1, 3, 16, 64) #batch_size of 1
model(x).shape
I’ll leave it to you to determine how to modify your dataloader to ensure the batch is the correct (expected) size for the model you are trying to use*.
*You could conversely try to instantiate a model that expects 1-D images:
m = resnet18()
m.conv1 = nn.Conv2d(1, 64, 7, 2, 3) #batch_size of 1
x = torch.ones(1,1,16,64)
m(x).shape
This way might be preferred – because it will allow you to continue to use 1-D samples.
I’d look into using libraries like openslide and libvips/pyvips for dealing with very large image files. I believe the discussion on the competition already has some pretty good explainers on how to deal with these files.
Our image recognition software is already good enough to solve CAPTCHAs, it’s part of the reason why the CAPTCHAs themselves have gotten harder (though AI have blown past that as well).
It’s also probably true that CAPTCHA data itself has been used to train models out there.
I think (emphasis on the think, this is speculation) part of the reason why you still see CAPTCHAs being used is that for the most part, there’s not too many bot hacks out there, and significantly fewer using AI to recognize CAPTCHA images (which is only a small part of a wider security system). The data that companies get from real human responses is probably valuable in some aspect as well. But again that’s just my speculation.
Hi Mike, I’m unable to download more than 35 images from Bing (the default). I’ve tried to use the max_count parameter, as I saw it equals to count. But still can’t get more than 35 images (not even trying more than 150). Any advice? Thanks!
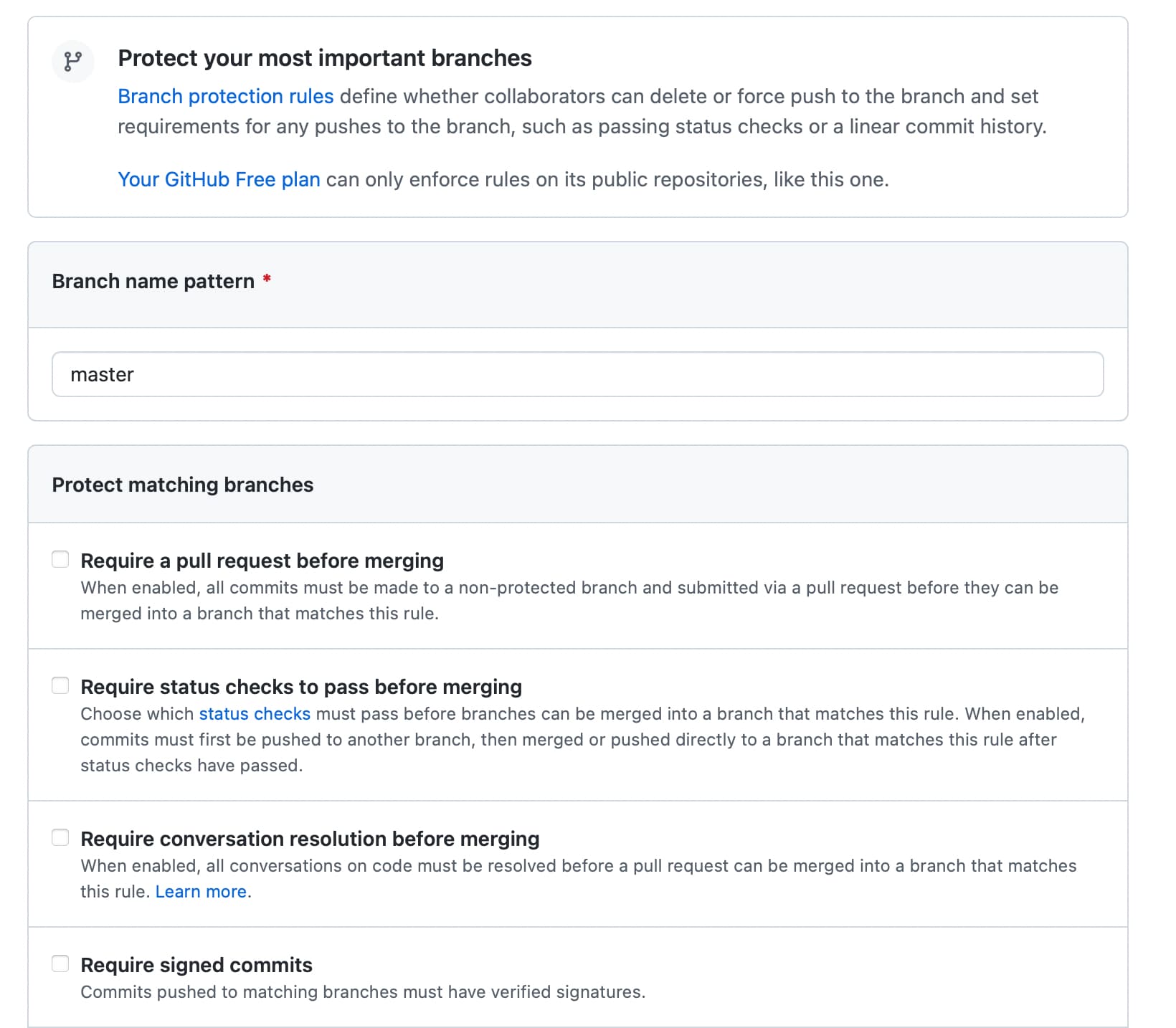
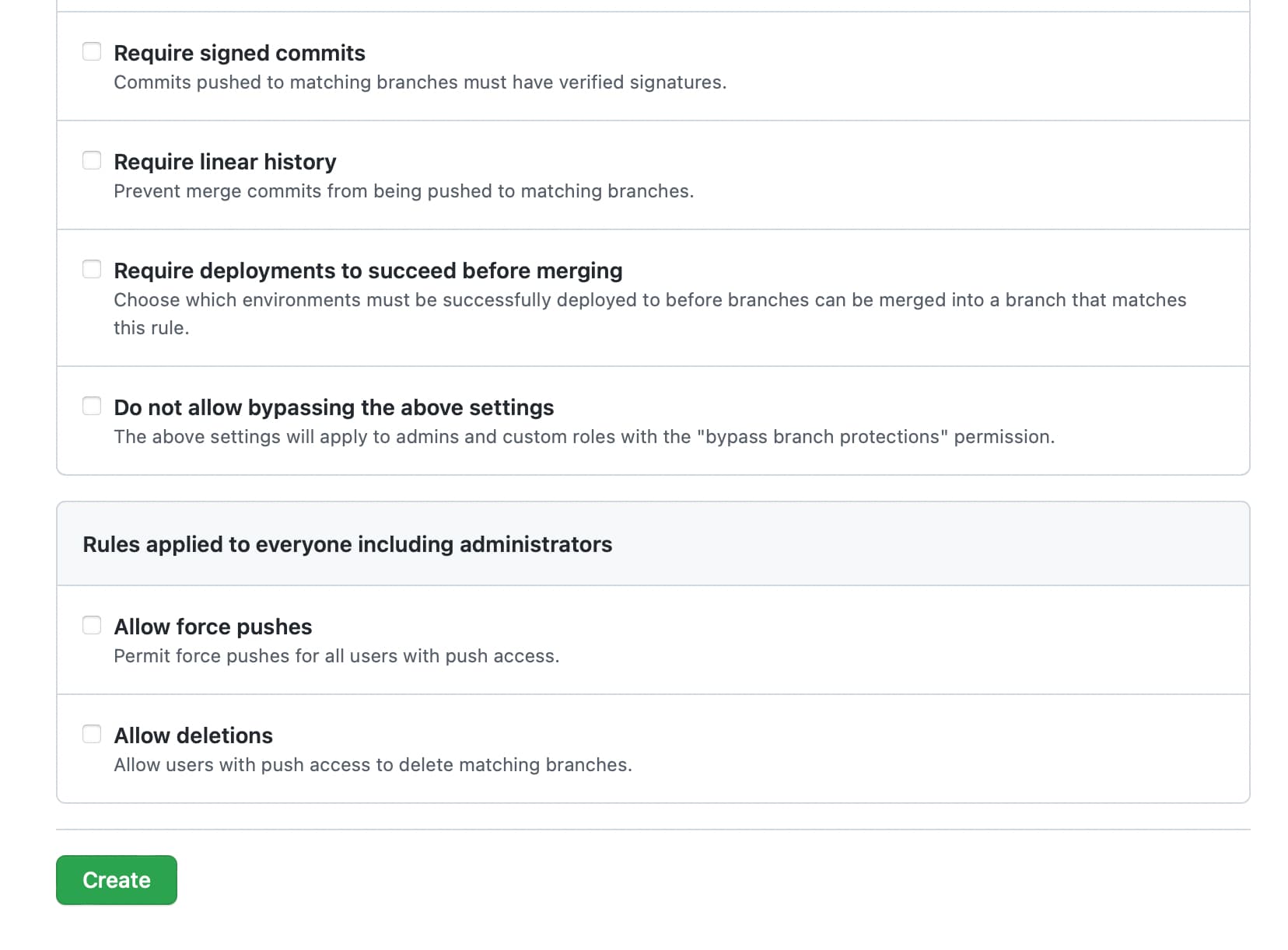
Which one do I click if I want no one to put any pull request
Which one do I click if I want other send pull request but I need to approve them to approve the change?
Hi, would someone explain to me please the following? I cannot really grasp how do training data relate to NN model parameters. Parameters are (notional) these a,b and c variables from the very basic quadratic equation example or in other words are wights of a links between layers right? But what are training data here? For exanple MNIST 28x28 BW image. Where do we feed this matrix to optimize parameters?
Great question Roman. In your example equation, the training data are various input data for x; minimizing the loss of the output of equation over various input passes lets us figure out the a, b & c parameters; now do this over plenty of input data to figure out plenty of parameters which in effect is the training process.
Since you brought up the MNIST example, I’d very much recommend following through the Chapter 4 in the book, also available as a notebook here. It really walks through the example from scratch.
im quite new in this topic (ai, cnn, ml, …) and for my project I am searching for some keywords to look for some tutorials or lessons. I will try to describe my intend.
My aim is to generate a thresholded image (with the correct threshold value) from an original image. Therefore I want to input a database with two images (or image pair, original image and the manually thresholded image) and train my neural network on these. After the nn is trained, I want to input a new (quite) similar image and my desired output is a thresholded image of this.
The main reason why I want to do this, is because the light settings/environment differs quite a little every time I capture new pictures. I couldnt solve this by simple image processing scripts in python fully automated. I wrote a script to do most of the steps automated but it still requires manual interfere.
I am conceive of the possibility to do it with the help of cnns/ai and see this project as a learning process for my self.
I am just not sure, where to start or better said what methods/keywords to look for. I really hope I could describe my intend and would be thankful for every pointer what to look for.
For my practical exercises I’ve picked up the topic of recognizing malware files. I follow the code presented in the “Malware Data Science” book (if someone is interested), but refactoring the code to use with PyTorch and fast.ai instead of Scikit. In chapter 11 the author offers some very basic example of a deep NN which, in short accepts a 1024 tensor of features. The feature generation function is rather “visual” than “tabular”. I.e. the exact position of each feature has no any explicit meaning. So we could think of these 1024 tensors as 32x32 pixel image of some binary data.
Proposed model architecture is as follows. 1024 inputs convolutes to 512 neurons of hidden layer with ReLU which in turn boils down to a single neuron with nn.Sigmoid activation.
Now the question. After watching several times Jeremie’s lectures (especially about Titanic dataset) I came to conclusion the NN model is totally not suitable for such kind of data, because linear models are more suitable for unified tabular data. And i have to apply some visual models. Am i right? In case I am, do i have to focus on some ready model or it is required to compose my own? What is the ultimate simplest pattern recognition model then (just for the sake of exercise) ?
Hi, I’ve started the course and am typing the notebook cells into Jupyter notebook on my local machine instead of running from kaggle. The first part of this exercise retrieves bird images, i.e.:
Upon attempting to run this, I get a HTTP403ForbiddenError which googling says is a rejection of host sites to avoid bots, something encountered with web scraping. I’ve found a potential remedy by declaring headers={"User-Agent": "Mozilla/5.0"}) but it’s unclear how to modify the search_images definition driving the web scraping as I’m a neophyte at web scraping w/ Python. I’m going to continue hacking away at a fix but was hoping a quick suggestion might be at hand to allow focusing on the course instead of needing to learn web scraping concurrently. I have of course deviated by not running from w/in kaggle, but why would kaggle not have this problem too? Thanks very much -Ron
the exact position of each feature has no any explicit meaning
So rearranging to a 32x32 input for a CNN won’t really help because the CNN is looking for “spacial information” - e.g. relationships of small patches of pixels. Since we have none its hard for the model to learn.
It shouldn’t matter whether you doing it on Kaggle or local. The “search_images()” function will be operating on a search service like duck-duck-go or bing. Do you know which service you are using?
Can you clarify which notebook you are copying from?