Hi, I have just started the course and am using jupyter notebook on my local machine.
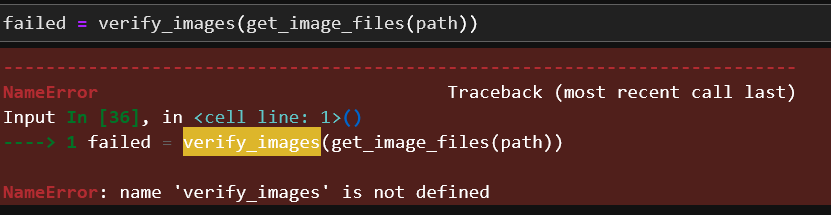
I am not able to use get_image_files and verify_images .
Whats the issue ?
Please guide. Thanks.
Hello bencoman, thank you for taking the time to answer my question. The search engine is duck-duck-go, but I’ve figured out what the error was. I was directly typing code from the 1st lecture video regarding “Is it a bird?”. The code cells in question turn out to be different from the actual notebook “Is it a bird? Creating a model from your own data”. First, the code from the lecture video:
!pip install -Uqq fastai
from fastcore.all import *
import timedef search_images(term, max_images=200):
url = ‘https://duckduckgo.com/’
res = urlread(url,data={‘q’:term})
searchObj = re.search(r’vqd=([\d-]+)&‘, res)
requestUrl = url + ‘i.js’
params = dict(l=‘us-en’, o=‘json’, q=term, vqd=searchObj.group(1), f=’,', p=‘1’, v7exp=‘a’)
urls,data = set(),{‘next’:1}
while len(urls)<max_images and ‘next’ in data:
data =urljson(requestUrl,data=params)
urls.update(L(data[‘results’]).itemgot(‘image’))
requestUrl = url + data[‘next’]
time.sleep(0.2)
return L(urls)[:max_images]<
However the code from the notebook has explicit install for duckduckgo_search and an explicit import for using duckduckgo as follows:
!pip install -Uqq fastai duckduckgo_search
and the function definition is different:
from duckduckgo_search import ddg_images
from fastcore.all import *def search_images(term, max_images=30):
print(f"Searching for ‘{term}’")
return L(ddg_images(term, max_results=max_images)).itemgot(‘image’).<
When I substitute that code instead into my local Jupyter notebook, the search for images works properly w/o throwing the HTTPS forbidden error 403. Wanted to post this if other folks end up finding the same errors for the web search step. Thanks again for your help!
1 Like
The issue is that you have not imported the library containing those functions.
Review what imports are used in the notebook you are copying from,
or try searching for: fastai import verify_images
2 Likes
I have a question. During the youtube videos, Jeremy has a “semaphore” where people can tell if they are getting by or getting lost - and also somewhere to make questions. What software is that?
i am running jupyter on windows 10, locally.
Why this code is not downloading the images in as per shown in the lecture 2 ?
(every code before this line is giving expected results)
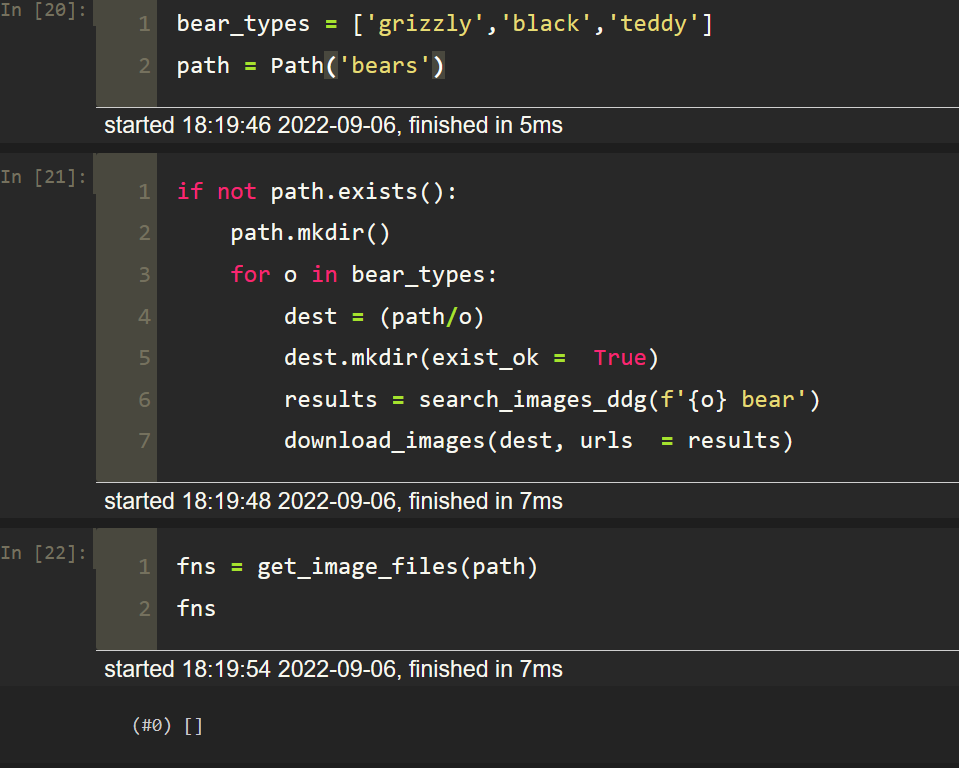
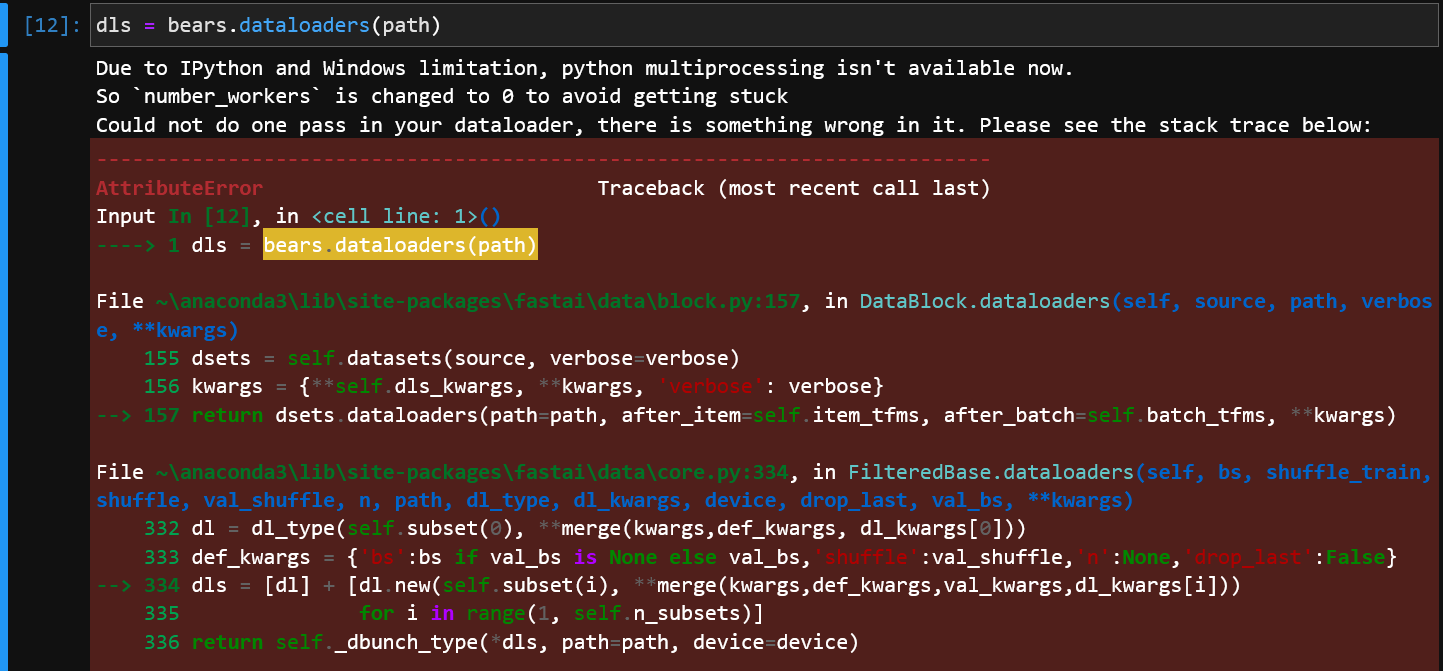
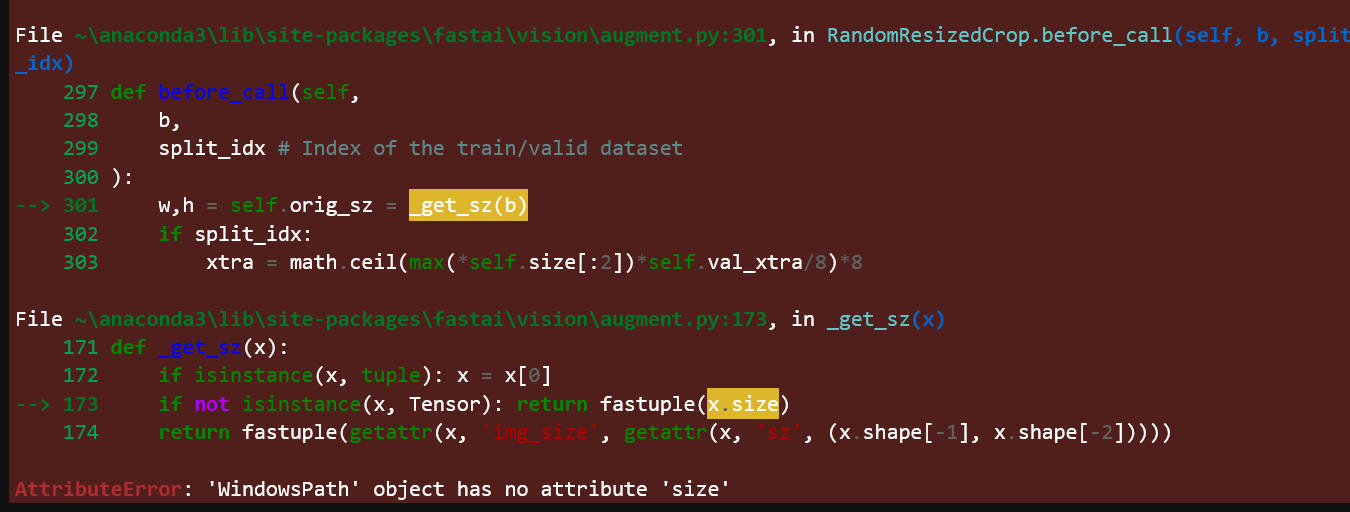
i am running on windows 10, jupyter, locally.
What should i do now, switch to colab?
And Can i do lesson 2 (production) while using colab?
It’s something that @radek wrote for us ![]()
Use WSL.
Sir, is there any alternative ?
I have win 10 , 1904 version , on which its hard to setup wsl and sustain .
i am trying to setup wsl for 7 hrs, still struck in issues…
Can i use colab for lesson 2,3 , etc ; as of now, i don’t wanna lose the flow of learning due to this.
please guide. Thankyou so much.
This is awesome! I love it! Thank you so much!
Is it open source? Can I fork and add some features?
Yes - use linux. Make a dual boot
@saurav2023 Can you link your full notebook and also the notebook you are copying from?
Hey everyone,
I am having issues while loading the learner for my new data loader. So here’s the code story:
I have trained my retinanet model on a MiDOG dataset which is an image dataset having 3 class labels 0-background 1 -hard negative 2- Hard positive, my model training is done and now I want the same model to be trained from my own dataset which has images and annotations in the same format (image format changed but that’s not an issue as openslide is able to load it perfectly), but the change here is that my own dataset has only 2 classes : 0 -background and 1: Hard positive, so when Itry to load the model using state_dict it throws me an error, The model was saved using torch.save_dict(PATH).
I saved this model using torch .save as follows:
torch.save(learn.model.state_dict(),PATH)
When I try to load this model for new data it shows an error:
learn.model.load_state_dict(torch.load(PATH))
Error:
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
1496 if len(error_msgs) > 0:
1497 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
-> 1498 self.__class__.__name__, "\n\t".join(error_msgs)))
1499 return _incompatibleKeys(missing_keys, unexpected_keys)
1500
RuntimeError: Error(s) in loading state_dict for RetinaNet:
size mismatch for classifier.3.weight: copying a param with shape torch.Size([3, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([2, 128, 3, 3]).
size mismatch for classifier.3.bias: copying a param with shape torch.Size([3]) from chec
Also, I tried a different approach for loading it using saving the whole model with torch.save(learner.model,PATH) and then loading it as follows:
learn.model=torch.load('PATH') #map_location=torch.device('cpu') without GPU
And now it loads without error, but then I try to do learn.fit it throws me index error:
THE CODE
max_learning_rate = 1e-3
cyc_len = 50
batch_size=16
learn.fit_one_cycle(cyc_len, max_learning_rate,callbacks=[SaveModelCallback(learn, monitor='train_loss',name='best_train')])
ERROR:
epoch train_loss valid_loss pascal_voc_metric BBloss focal_loss AP-Mitosis time
0.00% [0/3 00:00<?]
---------------------------------------------------------------------------
indexError Traceback (most recent call last)
<ipython-input-29-eb47d817d7bd> in <module>
4 print("\n Starting Training with n=",cyc_len,"epochs with batch_size=",batch_size,"\n")
5 learn.fit_one_cycle(cyc_len, max_learning_rate,callbacks=[SaveModelCallback(learn, monitor='train_loss',
----> 6 name='best_train_loss_bs64_GC_1500')])
7 frames
/usr/local/lib/python3.7/dist-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, final_div, wd, callbacks, tot_epochs, start_epoch)
21 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor, pct_start=pct_start,
22 final_div=final_div, tot_epochs=tot_epochs, start_epoch=start_epoch))
---> 23 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
24
25 def fit_fc(learn:Learner, tot_epochs:int=1, lr:float=defaults.lr, moms:Tuple[float,float]=(0.95,0.85), start_pct:float=0.72,
/usr/local/lib/python3.7/dist-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
198 else: self.opt.lr,self.opt.wd = lr,wd
199 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
--> 200 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
201
202 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/usr/local/lib/python3.7/dist-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
104 if not cb_handler.skip_validate and not learn.data.empty_val:
105 val_loss = validate(learn.model, learn.data.valid_dl, loss_func=learn.loss_func,
--> 106 cb_handler=cb_handler, pbar=pbar)
107 else: val_loss=None
108 if cb_handler.on_epoch_end(val_loss): break
/usr/local/lib/python3.7/dist-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
61 if not is_listy(yb): yb = [yb]
62 nums.append(first_el(yb).shape[0])
---> 63 if cb_handler and cb_handler.on_batch_end(val_losses[-1]): break
64 if n_batch and (len(nums)>=n_batch): break
65 nums = np.array(nums, dtype=np.float32)
/usr/local/lib/python3.7/dist-packages/fastai/callback.py in on_batch_end(self, loss)
306 "Handle end of processing one batch with `loss`."
307 self.state_dict['last_loss'] = loss
--> 308 self('batch_end', call_mets = not self.state_dict['train'])
309 if self.state_dict['train']:
310 self.state_dict['iteration'] += 1
/usr/local/lib/python3.7/dist-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
248 "Call through to all of the `CallbakHandler` functions."
249 if call_mets:
--> 250 for met in self.metrics: self._call_and_update(met, cb_name, **kwargs)
251 for cb in self.callbacks: self._call_and_update(cb, cb_name, **kwargs)
252
/usr/local/lib/python3.7/dist-packages/fastai/callback.py in _call_and_update(self, cb, cb_name, **kwargs)
239 def _call_and_update(self, cb, cb_name, **kwargs)->None:
240 "Call `cb_name` on `cb` and update the inner state."
--> 241 new = ifnone(getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs), dict())
242 for k,v in new.items():
243 if k not in self.state_dict:
/usr/local/lib/python3.7/dist-packages/object_detection_fastai/callbacks/callbacks.py in on_batch_end(self, last_output, last_target, **kwargs)
153 num_boxes = len(bbox_gt) * 3
154 for box, cla, scor in list(zip(bbox_pred, preds, scores))[:num_boxes]:
--> 155 temp = BoundingBox(imageName=str(self.imageCounter), classid=self.metric_names_original[cla], x=box[0], y=box[1],
156 w=box[2], h=box[3], typeCoordinates=CoordinatesType.Absolute, classConfidence=scor,
157 bbType=BBType.Detected, format=BBFormat.XYWH, imgSize=(self.size, self.size))
indexError: list index out of range
NOTE: The dataset is smaller as compared to the previous dataset on which the model is trained (nearly 100 images, 3k images before), so because of that I have also kept the batch size small :16).
Please guide me on how I can train my already trained model on my new dataset, should I save the image data bunch and try reloading the dataset on the older notebook where the MIDOG dataset was trained, and see if it can be reloaded, or is there any way to load the learner so that I can start my training.
INFERENCE WORKS FINE ON THE CURRENT MODEL WITH NEW DATASET
Any kind of resource : notebook, code snippet, would be beneficial.
Thanks for this wonderful forum.
Harshit
DATASET LINK:
https://imig.science/midog2021/download-dataset/
This is my notebook. i am using fastbook’s lesson 2 code ,line by line .
But just to perform imagescrapping i am using a library (jmd_imagecraper)
which i got from this blog:
Hi I’ve been reading Chapter 12 of the fastai book. I am really struggling to understand the logic of the the LMModule1 class. In the Book the code is given as:
class LMModel1(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = F.relu(self.h_h(self.i_h(x[:,0])))
h = h + self.i_h(x[:,1])
h = F.relu(self.h_h(h))
h = h + self.i_h(x[:,2])
h = F.relu(self.h_h(h))
return self.h_o(h)
However, based on Figure 12-3, I would have thought the code should read:
def forward(self, x):
h = F.relu(self.i_h(x[:,0]))
h = self.h_h(h) + self.i_h(x[:,1])
h = F.relu(h)
h = self.h_h(h) + self.i_h(x[:,2])
h = F.relu(h)
return self.h_o(h)
I basically don’t understand why self.h_h is being applied to the sum of inputs to the hidden layer rather than just the hidden layer output from the previous step.
@wing1328 I almost lost my sanity using GIMP, but maybe this helps to make sense (left out self. to keep it shorter):
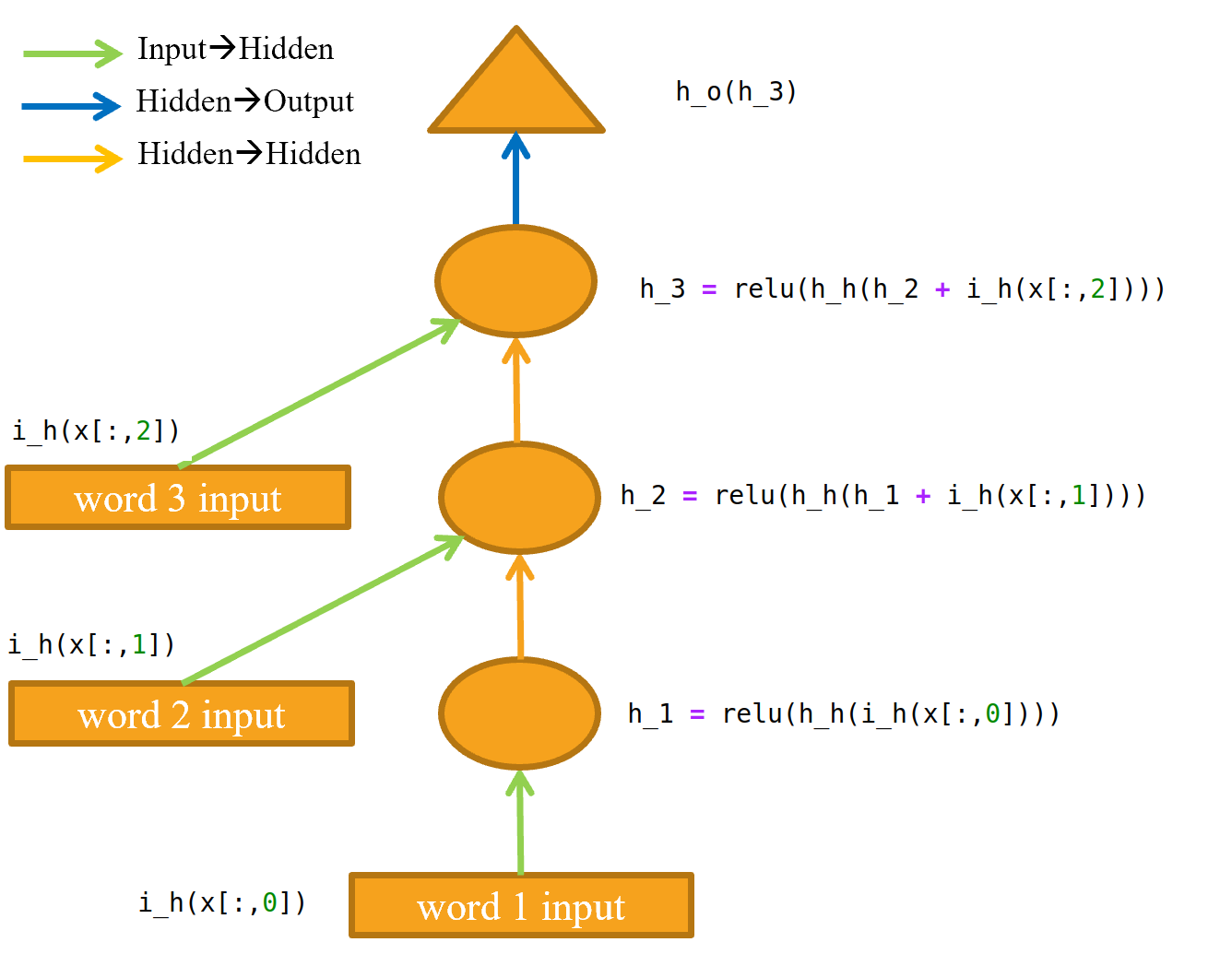
I think the main difference to your implementation is that you put the relu at the wrong a different place (it should be after applying the hidden layers self.h_h(…), also, if you remove all F.relus from both code snippets they are almost the same) and that you are missing one last hidden layer.
Let me know if there is still something missing for you ![]()
1 Like
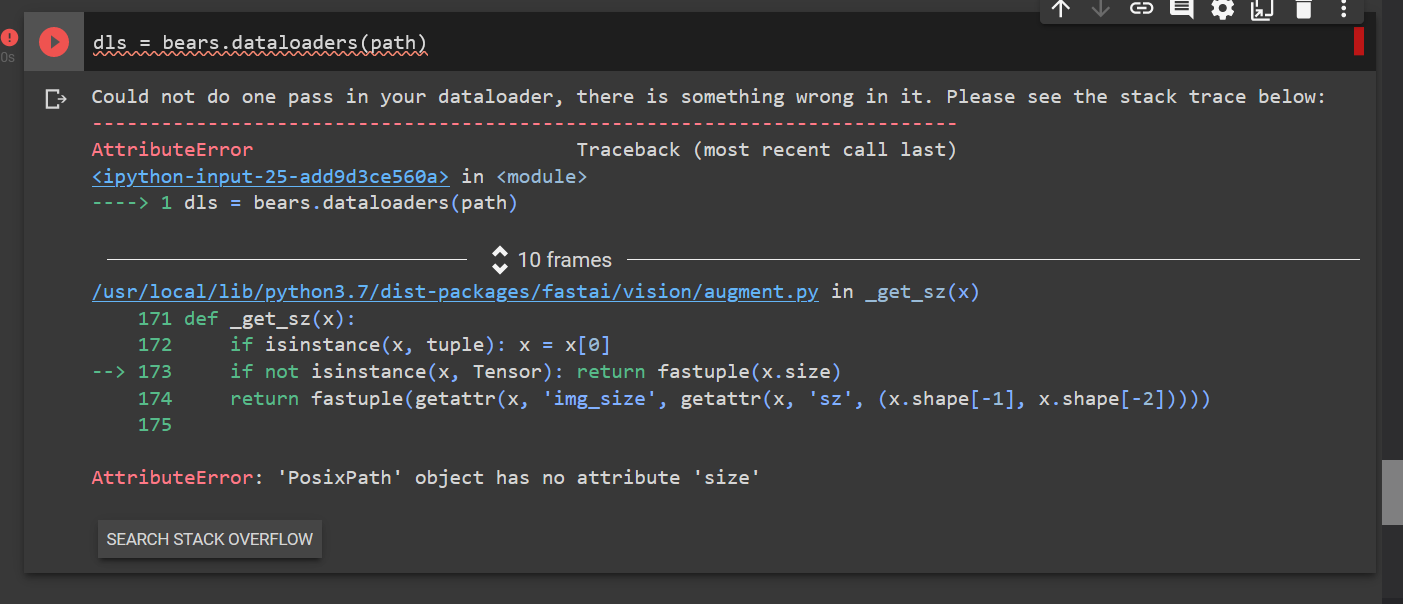
I ran your code and could reproduce your problem.
I noticed you incorrectly copied the datablock definition…
Here is the original…
animals=DataBlock(
blocks=(ImageBlock,CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2,seed=42),#splits the dataset into a training set and validation set
get_y=parent_label,
item_tfms=RandomResizedCrop(224, min_scale=0.5),
batch_tfms=aug_transforms())
Here is your code…
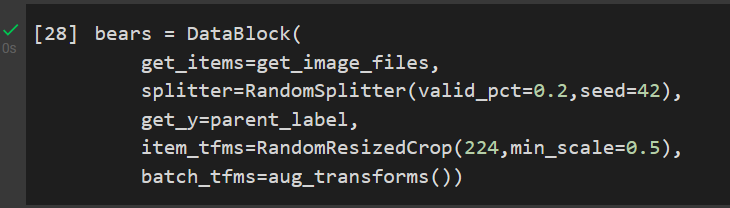
bears = DataBlock(
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2,seed=42),
get_y=parent_label,
item_tfms=RandomResizedCrop(224,min_scale=0.5),
batch_tfms=aug_transforms())
Notice anything different?
You set one less parameter.
Thus I will impart some general advice… you seem to be adapting the original code to your needs as you go - in one step. That is fine until you hit a problem. When you hit a problem, you need to step back and do it in two separate steps.
- Exactly reproduce the sample code.
- Only after Step 1 is working, adapt it to your needs.
When you start with something that works, its easier to notice when you break it, easier to backtrack to when it works, and so easier to iterate around the breakage.
1 Like
Thank you so much for the effort you made on the figure. My confusion lies with how I interrupted the figure.
I had assumed that the application h_h was represented by the orange arrow and since there are only two orange arrows h_h should be applied twice during a run through the network. I also had assumed that ovals only represented the application of the relu. But I can see from your diagram that the oval represents the application of both h_h and relu.