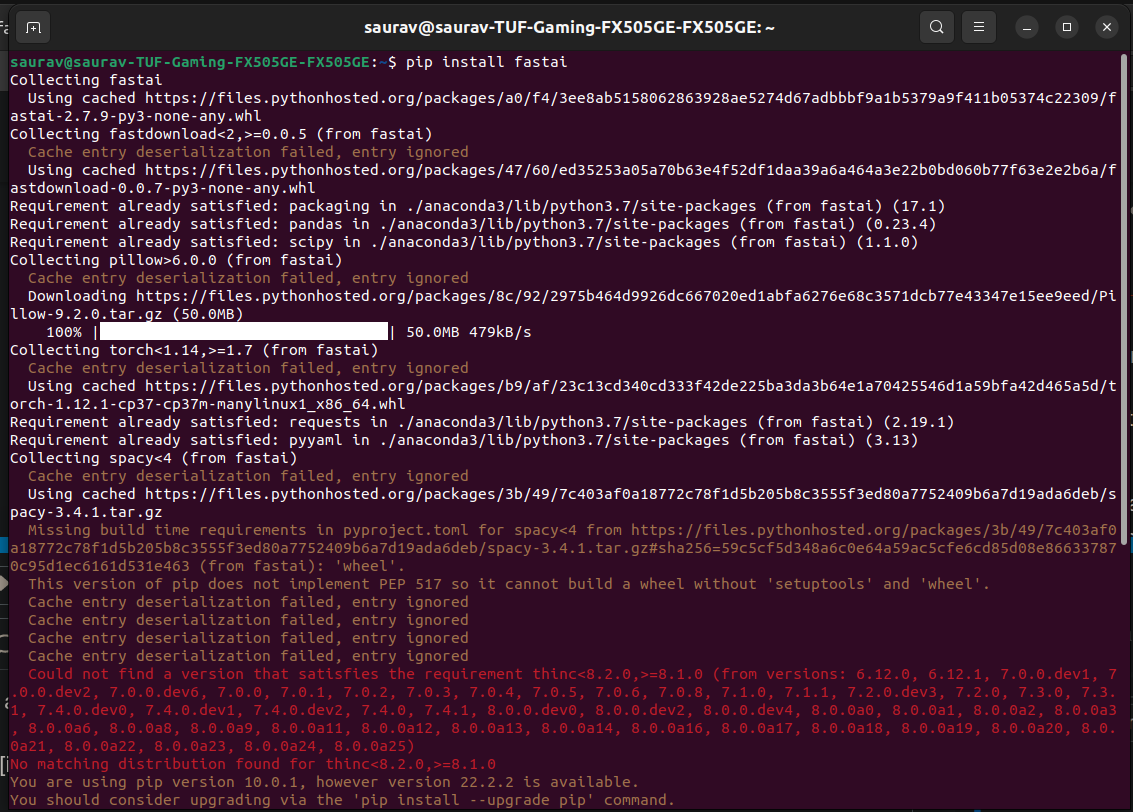
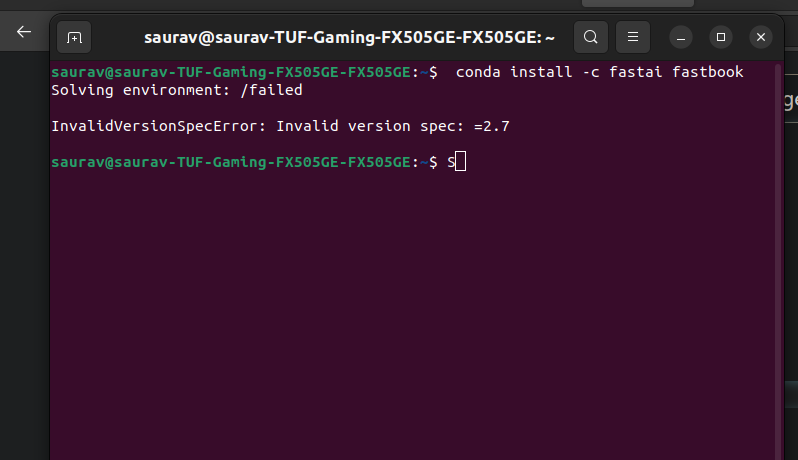
i am unable to install fastbook or fastai in my ubuntu 22.04 local machine .
What should i do? Please help. Thankyou.
Currently going through Chapter 6 of the book, where Datasets are built from a Pandas Dataframe.
dblock = DataBlock()
dsets = dblock.datasets(df)
This automatically splits the train and validation sets properly, I’m guessing based on the is_valid column in the DataFrame. I’m trying to locate where this split happens in the source code.
Edit: Nevermind, the answer is later in the book ![]()
The split was actually random, and the proper way to split is detailed
1 Like
Can you link to which installation instructions you are following?
Hello, I am quite new with AI. I would like to develop an AI that calculates the probability of matching 2 data records.
Example:
I have 2 person profiles with different data, like name, first name, alias, date of birth, city of residence, email address, address, hobbies, etc . Not all records contain all data, but some details are of course more meaningful for a comparison than others.
Is there a possibility to design an algorithm that takes 2 of these records and then tells me what is the probability (or similarity) that it is the same person?
Can you guys give me a hint as to the best place to start?
Thank you all so much.
1 Like
I tried many ways , Sir.
here are the links
-
Jeremy Sir’s 2nd lecture code:
-
I tried these 2 codes also.
Fastai :: Anaconda.org
https://anaconda.org/fastai/fastbook
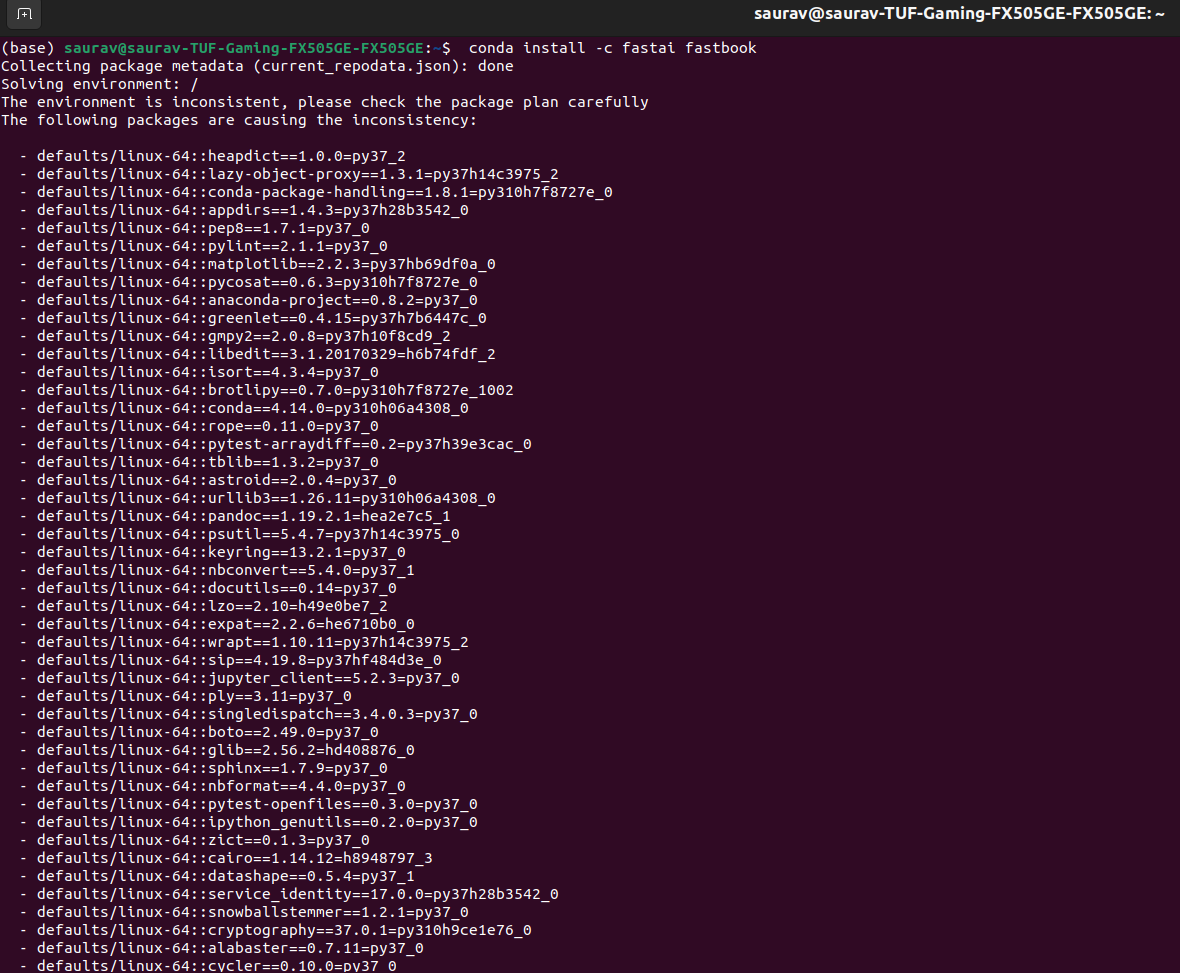

this code → conda install -c fastchan fastai anaconda
AND, i used this method to install anaconda 3 on my ubuntu 22.04
and updated anaconda successfully using:
→ conda update conda
Hi,
I have a question. Is there any way we can change the port that we use nbdev_preview? I want to change port 3000 as a default. I tried to make a change in _quarto.yml but nothing changed. Can you suggest how I can change the port? Thank you so much
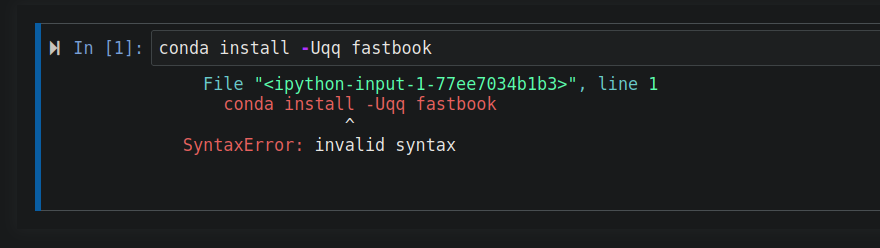
where did you see conda install -Uqq? That’s not a valid command so if you see that somewhere, it’s wrong.
Also, note that you can’t use linux commands like this in your notebook. You use them in the terminal.
Please, can you provide a link to the timecode in Jeremy’s video where you took that snapshot?
- I tried these 2 codes also.
Fastai | Anaconda.org
I presume you’ve search: conda environment is inconsistent please check the package
There seem several good answers. Which of these didn’t work for you?
Whoops, I missed that you were running those in your notebook. As Jeremy said, these are shell commands, not notebook code.
You can run shell commands from your notebook by using a leading “!” as described here… https://www.youtube.com/watch?v=FsSVOiJOn3w
but troubleshooting is probably easier with “shell commands run in a shell”,
rather than “shell commands run in a notebook”.
- updated anaconda successfully using:
→ conda update conda
Did you take any action after this?
I have trained 2 vision models with fastai, which respectively reported error rates of 10% and 6% after the last training epoch on Kaggle.
I exported both, and reloaded them locally.
Then I used learn.get_preds on each valid DataLoaders, and compared the predictions against the labels inside each valid Dataset. This way, I get error rates of 17% and 10% respectively
Can anyone help me understand why?
EDIT: Running a learn.predict() loop on each item from the valid dataset reports the same error rates as in Kaggle, of 10% and 6%
Hi all,
After lesson 3, I’ve been playing with the Titanic dataset, trying to build a nn classification model in fastai.
First, I wrote a very basic model, just to get myself going:
https://www.kaggle.com/code/gal064/titanic
But there are a few things that are weird, which makes me believe I’m doing something wrong:
- The fitting process reach 0.601124 accuracy in the first epoch, but that never improves on subsequent rounds
- The model and data can be improved a lot, but even with this very basic notebook, 0.60 acc seems too low. For comparison, I wrote the exact same steps in R and used a nn package and got 80% accuracy.
I feel like I’m missing something here no and I’m using fastai wrong, but can’t figure out what is the problem?
One thing I noticed is that it seems you dropped the ‘Fare’ column.
Also, looking at the final table row#1, 3 and 5, the survived column doesn’t match the prediction value. Add this in your dls:
y_block = CategoryBlock()
In the course notebook, removing it gives the same non-improving accuracy issue
At any rate, Jeremy goes through this exact problem from scratch and using fastai in lesson 5. He gets around 82% accuracy, you should be able to compare with yours in more details.
See notebooks 5 (from scratch) and 6 (fastai) here
1 Like
Perfect. Setting y_block = CategoryBlock() did the trick. I thought the predictions are probabilities, so I didn’t realize it’s a regression.
Thanks for the help!
1 Like
Hi Jeremy, im starting the new 2022 course and was wondering if there was a paperspace updated setup for the new notebooks, the book itself is still on paperspace but was wondering how to install the new stuff into my work space
thanks
Hi Team, can you help me to download Lesson 10’s Jupyter Notebook code? Spent some time trying it but couldn’t find where to download it from.
Hi Everyone,
I’m currently reading the Fastbook 04_mnist_basics.ipynb and I am having trouble understanding the mnist_loss function for the following scenario:
Suppose that the target was a 3 but the machine has a high 0.9 confidence that it’s a 7.
That would mean
trgt = tensor([1])
prds = tensor([0.9])
Using the current mnist_loss function:
Wouldn’t torch.where(trgts==1, 1-prds, prds)
return the loss as 0.1 which I think is wrong because the loss should be 0.9 since it incorrectly guessed the wrong number with a high degree of confidence.
Can someone please let me know if I’ve misunderstood it? It would be greatly appreciated.
My thoughts are that the predicted value + confidence level + actual value should be used to determine the mnist_loss.
The way it works is: any prediction > 0.5 is considered a 3 and any prediction < 0.5 is considered a 7.
The example given in the text is
So, for instance, suppose we had three images which we knew were a 3, a 7, and a 3. And suppose our model predicted with high confidence (`0.9`) that the first was a 3, with slight confidence (`0.4`) that the second was a 7, and with fair confidence (`0.2`), but incorrectly, that the last was a 7.
indicating that a 0.2 prediction means the model thinks it’s a 7.
2 Likes
I see. So basically low confidence score indicates not 3 and since we are classifying only 3s and 7s then it’s probably a 7. TY giggs!!
Careful, do not confuse a prediction and the confidence!
The prediction is just a value between 0 and 1, where any number in [0, 0.5) is 7 and any number in (0.5, 1] is 3.
What determines the confidence is how close the prediction is to each target.
0.9 is > 0.5 so it’s a 3, and it’s very close to 1, so it’s a high confidence of a 3.
0.2 is < 0.5 so it’s a 7, and it’s fairly close to 0, so it’s a fair confidence of a 7.
0.6 is > 0.5 so it’s a 3, but it’s pretty far from 1, so it’s a low confidence of a 3.
0.4 is < 0.5 so it’s a 7, but it’s pretty far from 0, so it’s a low confidence of a 7.
1 Like
Check out the NLP lesson in the course. That has something similar.
1 Like