I am working on an OCR model using fastai. I was able to train on IAM dataset using tensorflow and was able to get 65% accuracy. I’m hoping to get better results using pytorch/fastai…
For now I want to solve it step by step using v3 API…
Here’s my understanding -
Create a databunch where the datasets return <vision.Image.Image, torch.tensor (containing the text in image)>
Create a pytorch model - this should be normal
Create a new stepper to compute batch target lengths that are fed into CTC loss function
Create a learner using above 3 and train.
Am I correct with above assumptions? Can anyone advise me if I’m missing something or if I should do anything differently?
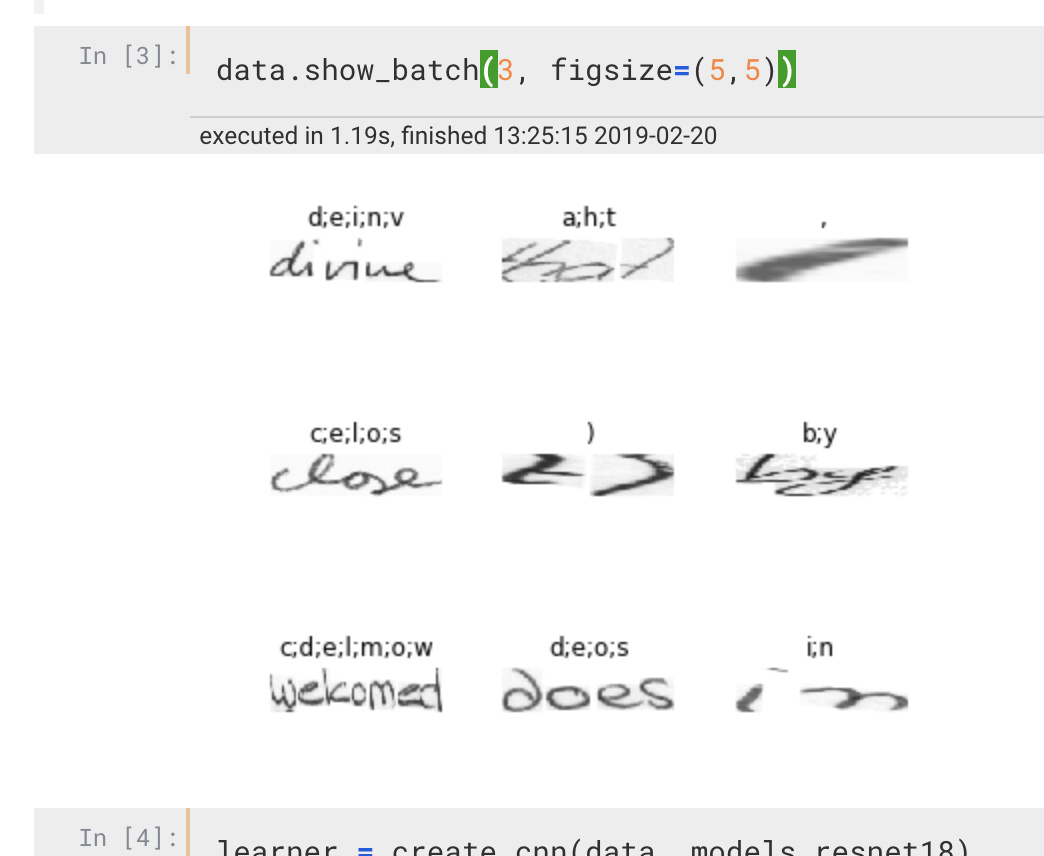
So far… I could load all images into a data-bunch as below image with following code
%%time
with open('words.txt', 'r') as f:
data = f.readlines()[18:]
data = [l.strip().split() for l in data]
data = {l[0]:l[-1] for l in data}
def label(fpath)->'LabelList':
"Give a label to each filename depending on."
return list(data[fpath.stem]) # for now we are losing on the order
deg = 5
tr_tfm = [perspective_warp(magnitude=(-0.,0.)), rotate(degrees=(-deg,deg))]
val_tfm = [perspective_warp(magnitude=(-0.,0.)), rotate(degrees=(-deg,deg))]
data = (ImageItemList.from_folder('words')
.random_split_by_pct()
.label_from_func(label)
.transform((tr_tfm, val_tfm), size=(32, 128), resize_method=ResizeMethod.SQUISH)
.databunch())
The targets are not in order, what needs to be changed for them to be in order? Is this because I am returning a list of outputs in the label function?
How to ensure that the images’ aspect ratio is maintained (i.e., not stretched?). I have tried ResizeMethod.PAD but there’s an error in concatenating the dataset since the transformed images don’t have the same shape…
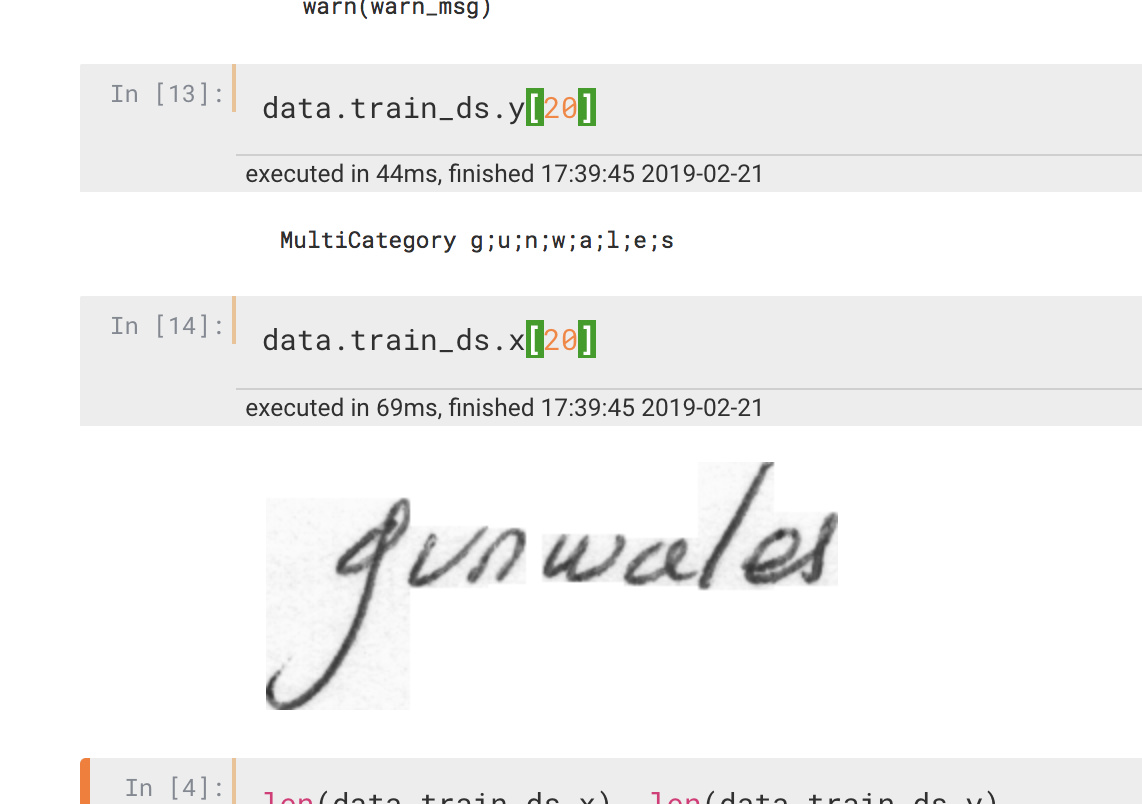
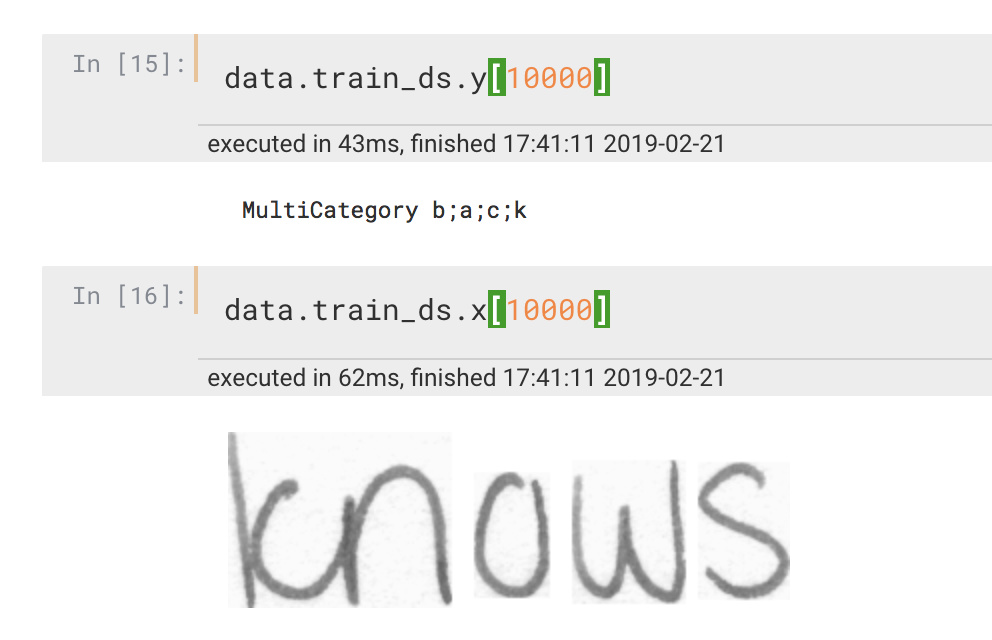
I think you need to use MultiCategoryList for your labels, the easiest way would be to make your label function return a string with the letters separed by a char (like and then pass label_delim = ‘;’ when you call label_from_func
For the aspect ratio, try without any transform first, to check it doesn’t come from the warping or the rotation.
I modified it that way to return ';'.join(list(data[fpath.stem])) and added label_delim in label_from_func as you suggested. But now fastai shows a warning like follows on databunch creation -
UserWarning: There seems to be something wrong with your dataset, can't access these elements in self.train_ds: 44595,73249,57586,49432,60372...
and throws an index error on calling data.show_batch
IndexError: index 59178 is out of bounds for axis 0 with size 43886
I guess the error is coming from not able to load strings which have a single character… But I can’t confirm it since I checked the source code and can’t seem to find label_from_func using label_delim anywhere. Could you let me know what portion of source code would help me out?!?
It is quite daunting to read source-code when you don’t know where to look.
I’ve just started with the writing the code and there’s a long way to go. Thank you for helping me @sgugger
But what do you have in data.train_ds.y.items[0] for instance, and what is data.train_ds.y.__class__ (if it’s not MultiCategoryList, the bug is there). Then if you cna load the index 0 or 1, what appends when you try to load in data.train_ds.y.items the indices where it tells you there is a problem?
I can load indices and the output seems to be as expected. __class__ returns MultiCategoryList, and data.train_ds.y.items is returning a list of lists of integers.
@yesh@sgugger I’m also interested in this problem but i find it difficult to create a databunch in fastai. All my images are saved in file h5 because there are too many, can’t put it all in one folder.
All I have is a file image.h5 which saves all images (type numpy array) and a dataframe which links filename of image with its label (text)
Could you please give me an insight what can I do to create a databunch from it?
Not really, I was occupied with other work. If people are interested, I can create a github project with access to a sample dataset of 20000 images of large numbers (like captcha) and the preliminary pytorch code that I have written that is giving around 60% word accuracy. Please let me know so I can add the interested people as collaborators.
Hello, I got interested in using fastai to create an image to LaTeX converter. I suppose the question would be similar to using fastai for OCR? I am aware of the proposal to use MultiCatogoryList, but the dataset im2latex does not have convenient delimiters to easily apply label_delim. Just wondering if you have made progress in your problem.
 and then pass label_delim = ‘;’ when you call
and then pass label_delim = ‘;’ when you call