Currently I´m trying to train a model for OCR with fastai. I´ve read most of the posts in the forum but couldnt´t find anything for my problem. I´ve created the dataset myself from a dictionary and I´m using a csv-file to save the labels. The text will always be horizontal and easy to read and will be passed as an image file, containing just the text, so nothing to fancy is needed.
Here’s what I’ve got so far:
!pip install -Uqq fastbook
import os
os.environ[‘CUDA_LAUNCH_BLOCKING’] = “1”
import fastbook
import shutil
fastbook.setup_book()
from fastbook import *
from fastai.vision.all import *
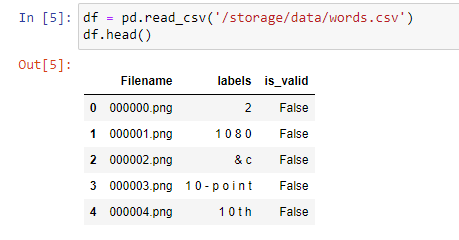
So the problem is, that the labels get switched to alphabetical order and multiples get deleted. Is there a way to change this with Datablocks? Or do I need a completely different way of doing it?
I found a post where someone had a similar problem and seemed to have fixed it but I believe this doesn’t work anymore with current fastai versions.
It would be amazing if someone had any ideas and could help me. Thank you!
Isn’t this an object localization problem instead of multi-label classification? As far as I know, MultiCategoryBlock only allows classification whether a category is present in the picture or not, it cannot provide the location or the number of occurrences of a category.
I haven’t tried any of this myself, but maybe you can check out RetinaNet or CRNNs or fastai’s bounding boxes. However, I don’t know how these approaches expect your training data to be labeled, manually providing bounding boxes for each letter seems to be a lot of work
My partially informed opinion is that what you want to do is beyond the techniques that the fastai course covers. You already found the problems with trying to fit OCR into a multi-label recognition problem and @johannesstutz identified the issues with the bounding box approach.
What you want ideally is to have the input as text images and the labels simply be the text contents. I have seen this done in my outside reading using image-to-seq models with attention. You might want to research the published approaches to machine-learning-based OCR to find the ones that have worked. Googles’s house number recognition and “image captioning” would also provide places to start. In sum though, this not a beginner project and would use techniques not covered in the fastai course.
@johannesstutz@Pomo
Thank you both for your tipps. So it seams like fastai is not the way to go for this problem. I thaught there would be a way to make this work with MultiCategoryBlocks, because in the linked post@sgugger recommended MultiCategoryLists, which i thaught were a predecessor to the Blocks API.
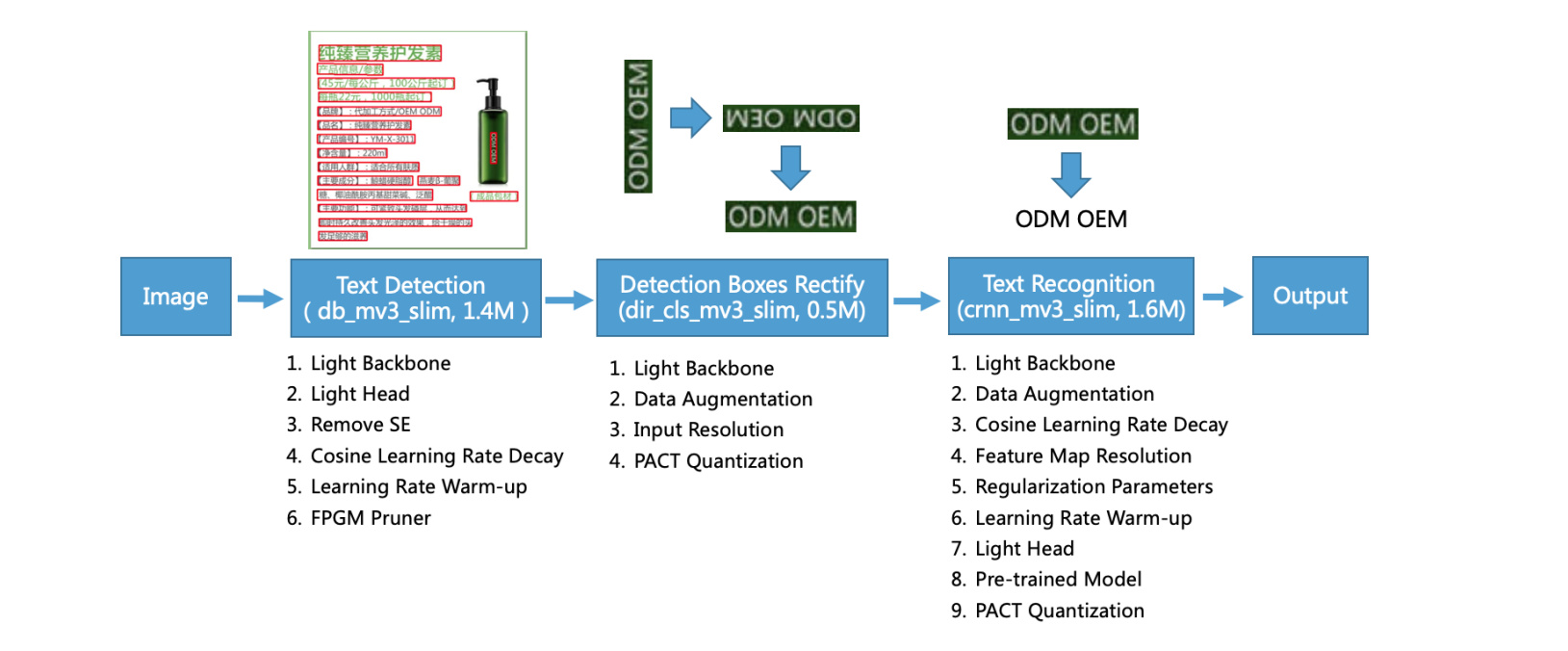
There is an interesting (very recent) paper from some BAIDU researcher about a lightweight OCR: PP-OCR: A Practical Ultra Lightweight OCR System. It describes the different steps involved in their OCR Deep Learning Solution. The paper also has a good list of references in this field.
1 - One for Text Detection
2 - One for correcting the text orientation to have a horizontal text
3 - One to transform the text image into characters
You can ignore the Quantization and Pruner parts. Those are related to weights compression which is another topic especially at the beginning of an OCR project since you will be mostly interested in training your model and not compressing the weights.
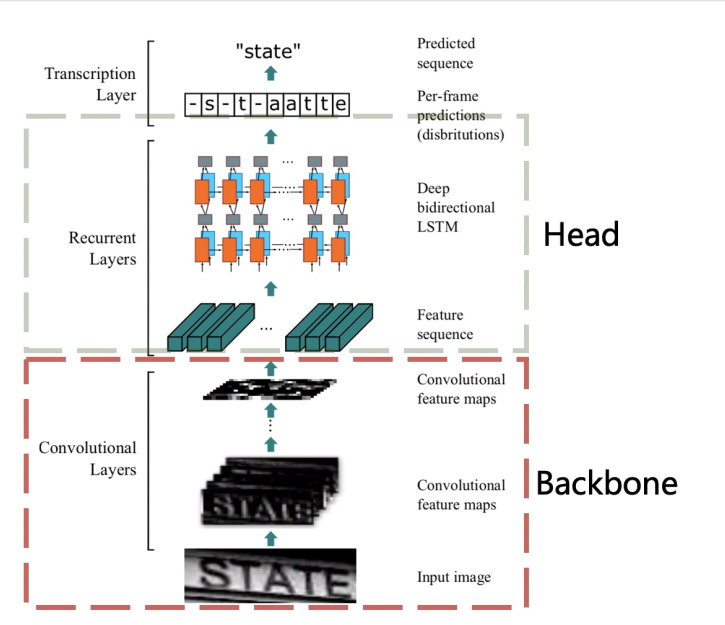
Based on the images that you provided here above, you can just jump to the third neural network. For that part, they use a CRNN which basically take an image, pass it through a convolutional neural network to extract its features, feed those features into an LSTM to spit out the corresponding characters (text).
There are many pytorch implementations for CRNN. You might check out one of them, and you might find a way to adapt it to fastai. You can google “CRNN pytorch”. I’m not familiar with those implementations so I cannot refer one.
I think fastai’s data handling would be fine for this problem, input: image/target: text string. Also the training process within a Learner. The hard part will be designing the model.
Thank you! Yes you’re right it’s the third step I’m working on, I already have a model for detection and correction won’t be necessary. The article/pictures look very interesting and I’ll look into that next week!