Hello,
I recently tried to recognize digits from from power meter readings. For this task I used the RetinaNet from @Bronzi88’s great notebook.
I got mediocre result, where seemingly more difficult digits are recognized and obvious ones not at all.
My question is, if RetinaNet is not the right approach to his problem?
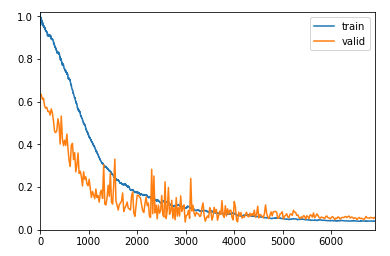
This is the loss after 300 epochs of training at 1e-4 learning rate, looks fairly ok to me.
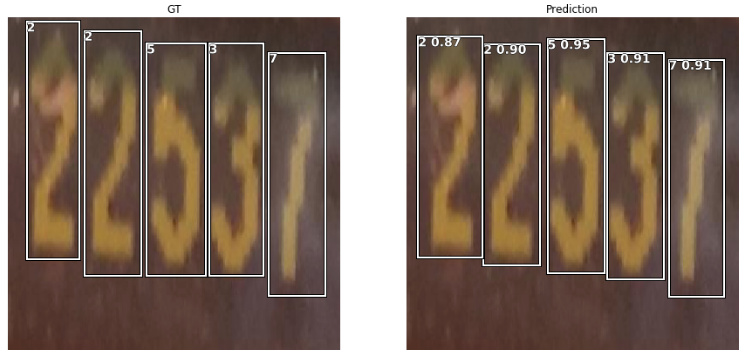
Here are some weird examples of detected and undetected digits.



Very blurry digits are recognized with above 0.9 probability, whereas very clear digits as seen in the first example are not detected at all.