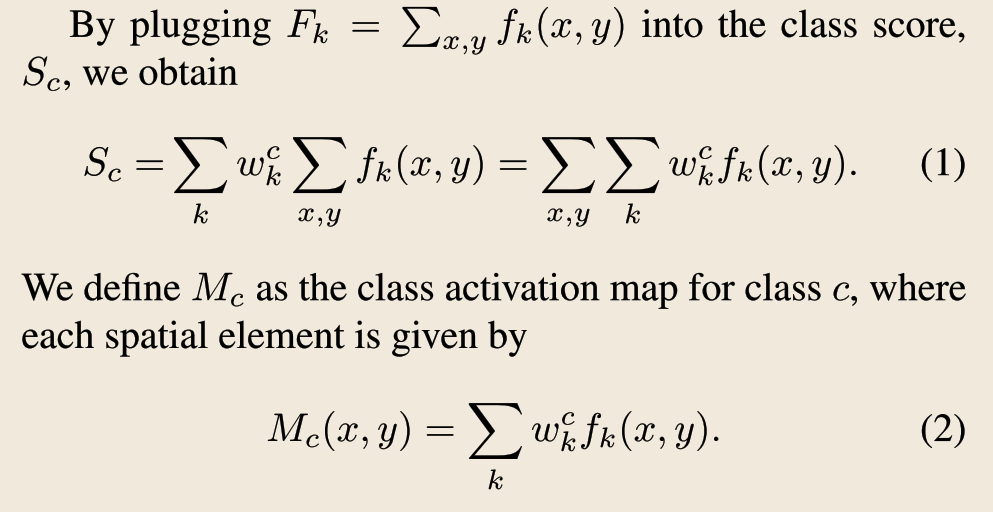@MicPie, @KarlH . I’m reading the Hooks callbacks also but it’s quite hard to understand. Do you know where is this part in the dev nb ?
More specifically, in the class Hooks.
class Hook():
"Create a hook."
def __init__(self, m:nn.Module, hook_func:HookFunc, is_forward:bool=True):
self.hook_func,self.stored = hook_func,None
f = m.register_forward_hook if is_forward else m.register_backward_hook
self.hook = f(self.hook_fn)
self.removed = False
def hook_fn(self, module:nn.Module, input:Tensors, output:Tensors):
input = (o.detach() for o in input ) if is_listy(input ) else input.detach()
output = (o.detach() for o in output) if is_listy(output) else output.detach()
self.stored = self.hook_func(module, input, output)
def remove(self):
if not self.removed:
self.hook.remove()
self.removed=True
Why do we have self.hook_func = hook_func but also defining def hook_fn() . what is the purpose of these 2 ? they have the same name. Sorry because it took me a while to really understand this part so I’m appreciated if someone can help me on it.
After asking the question, I searched a little bit and have a simple answer.
The dev nb for hook is in 005a_interpretation. But it doesn’t have many information
To undertand how hook works in pure Pytorch: pls find here the example - hook
The hook_fn(self, module:nn.Module, input:Tensors, output:Tensors) is just the syntax to use hook in Pytorch. The real function we define in hook_func:HookFunc
I will continue to read about this part, always appreciated if someone can show me good resources about this Thank you in advance
p/s: Actually, after reading the PCA technique to explain the last layer nodes (in Share your work), I think about an experiment. I will try to put zero each node in the last layers, finding it will affect which categories in the results. Then we can understand what this node represent. How do you think about this ?
Then I populate a list with SaveFeatures objects for each layer in the model I want activations from
sfs = [SaveFeatures(m[i]) for i in range(len(m))]
Then when you run something through m like p = m(x), each element in sfs is populated with activations from its corresponding layer.
One thing to note is that sometimes you need to get fancy with indexing because models are not always structured linearly. For example the model used in Lesson 1 has two layer groups accessible by indexing - one layer for the resnet34 backbone and one layer for the custom head. If you want to get activations from the resnet block you need to specifically index into it.
sfs = [SaveFeatures(children(m)[0][i]) for i in range(len(children(m)[0]))]
It is the signature of hook in pytorch. I found this in the description.
The hook will be called every time after :func:`forward` has computed an output.
It should have the following signature::
hook(module, input, output) -> None
So we don’t call it directly but the hook function. At each forward, it will extract the model, input, output and put in this function.
With the flatten_model function it is easy to get the layers of interest and the hook gets installed by calling hook_outputs(layers).
Where did you find the flatten_model and the other parts of the code snippet so I can dive a little deeper into this topic?
I guess the callback is not needed for getting the activations and is for more advanced operations or am I wrong?
If somebody has more information/sample code/etc. on this topic I would be very interested.
The source code of flatten_model is : flatten_model = lambda m: sum(map(flatten_model,m.children()),[]) if num_children(m) else [m]
And I found it by looking at the hooks.py in /fastai class HookCallback(LearnerCallback):
def on_train_begin(self, **kwargs):
if not self.modules:
self.modules = [m for m in flatten_model(self.learn.model)
if hasattr(m, 'weight')]
self.hooks = Hooks(self.modules, self.hook)
It indicates that if modules are not specified then choose all the modules which have weight in the model. So for yours interest, you just need to choose the last linear layer. I got familiar with these things by playing around with the ActivationStats and model_sizes in hooks.py
I think for getting just the activations, you don’t need callback. The hook_outputs is enough. Actually, I haven’t played with the callback yet still not familiar yet with the the method in callback.
I’m very appreciated if someone can give more examples of this topic too
Thanks Jeremy. Can i add the callback after the model have already trained ? Because in this case I train the model first then try to get the activation in the validation set
Hey, if useful I implemented Grad-CAM using fastai 1.0; allows to see which parts of the image are “used” by the network to make a prediction. It’s a variation on CAM using averaging with gradients.
This might also be interesting to some of you because it has gradient/backward hooks as well as the output_hooks.
Thank you for your great and instructive notebook!
I incorporated it into my lung tissue pet-project.
While running the code several times I sometimes encountered a strange bug that I was able to fix by setting the model in evaluation mode with learn.model.eval().
Poor resolution is inevitable - the output of the “bottleneck” units in resnet are 7x7 feature mapsz so all the CAM methods are going to be constrained by this.
I’m not really sure about state of the art (and it’s probably hard to define?) - especially for satellites, I did the PCA/tsne on the last later vectors and it’s apparent that the network is distinguishing “twisty roads” from “grid cities” and “big blocks” vs “lots of little houses”. There’s also a huge color component; beiges and ocres from Mediterranean citiess, …
So I’m thinking to try out a bunch of things and see what sticks
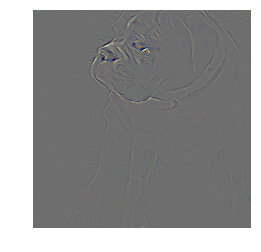
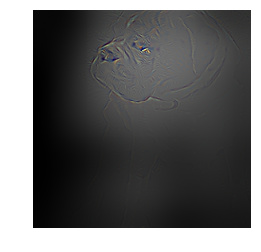
Hi - added Guided Backprop and Grad-CAM guided backprop to the notebook. Literally three lines of code using fastai Hooks . . .
The idea is to determine the importance of each pixel to the prediction that is made by the network. To avoid interference, the backprop is clipped to positive gradient contributions. This was introduced in Striving for Simplicity: the All Convolutional Net paper.
Example output:
Element-wise multiplication with grad-cam:
And here is the notebook, also showing what happens when you just plot the gradients, without doing guided backprop.
I’m not catching the exact role of global average pooling in CAM. If you read the paper, one of the major points the authors of CAM insist upon is the ability of Global Average Pooled CNNs to extract features and indentify objects even if they are not specifically trained to do so.
By GAP-CNNs they mean a CNNs which is bestowed with a GAP layer just between the last convolutional and the final fully connected classifier.
The equation to look upon is (2), since it defines every spatial element of the CAM. In this way they get a tensor which has the same dimensions of the last feature map outputted by the last conv layer. Then, typically one upsamples such map and visualize it in overlay with the original image Like @henripal did, to ‘see what the cnn considers important for classifying such image’.
My question is:
The authors insist a lot about the importance of Global Average Pooling, but in the end, the define their CAMs in a way that does not consider the GAP layer at all. Written as such, it’s like the Dense layer is directly connected with the last conv. On the other hand, if plug in the GAP, you just obtain a vector whose dimesion corresponds to the number of classes, quite useless for visualization purposes.
Can someone shed a bit of light about that? Thanks!
 Thank you in advance
Thank you in advance