Hi everyone,
I’m excited to share new developments on segmentation & classification of buildings from drone/aerial imagery in Zanzibar, Tanzania:
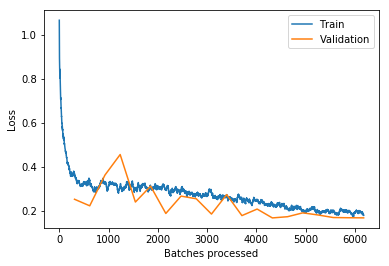
Updated building classifier to work with fastai v1.0.28 and trained the model to >94% accuracy. Looking at train/val loss, could keep training to get even better accuracy. Almost every top-loss prediction error is because of mislabeled ground truth data so some ImageCleaner action would definitely help:


Added Grad-CAM code from @henripal (much thanks for the discussion & notebooks!) to aid in model diagnostics and interpretability. Exploring under the hood to see what insights and ideas for improvement we can get about the model’s behavior.
Here’s looking at individual feature map channels ranked in importance as the sum of gradients for that channel calculated by back-propagating from the one-hot-encoded class prediction (a “Complete” building in this case). In other words, what specific feature maps (out of 2048 channels in my case) are most important to classifying this image as “Complete” and what are they looking at (activating on):


I’ve also created a new segmentation model based on lesson-3 camvid which handles the first part of the overall task (segment every pixel as building or not building). As mentioned in my 1st post, I originally used the old fastai v0.7 library so I’m bringing everything up to v1 now. Performance is not up to that of my old model yet but I’m haven’t done any optimizations. Off-the-shelf fastai v1.0.28 for binary segmentation using a pretrained resnet34 encoder already gives pretty satisfying results (pixel-wise accuracy > 0.98, dice score > 0.85):



Here are both notebooks:
- Classifier notebook: https://nbviewer.jupyter.org/github/daveluo/zanzibar-aerial-mapping/blob/master/znz-classify-buildings-20181119.ipynb
- Segmentation notebook: https://nbviewer.jupyter.org/github/daveluo/zanzibar-aerial-mapping/blob/master/znz-segment-buildingfootprint-20181119.ipynb
I’ve also open-sourced my pre-processed training data for both models so anyone who wants to work with these notebooks can have ready-to-train data without going through the somewhat-niche data prep to convert geoJSON polygons into binary masks or crop individual buildings into images. For anyone interested in those steps, I will post them as well in future notebooks. Data download links and more info at the repo here:
Much thanks to the Commission for Lands, Govt. of Zanzibar and WeRobotics via the Open AI Tanzania competition for the original drone imagery and training labels. They are made available under Creative Commons Attribution 4.0 International license.
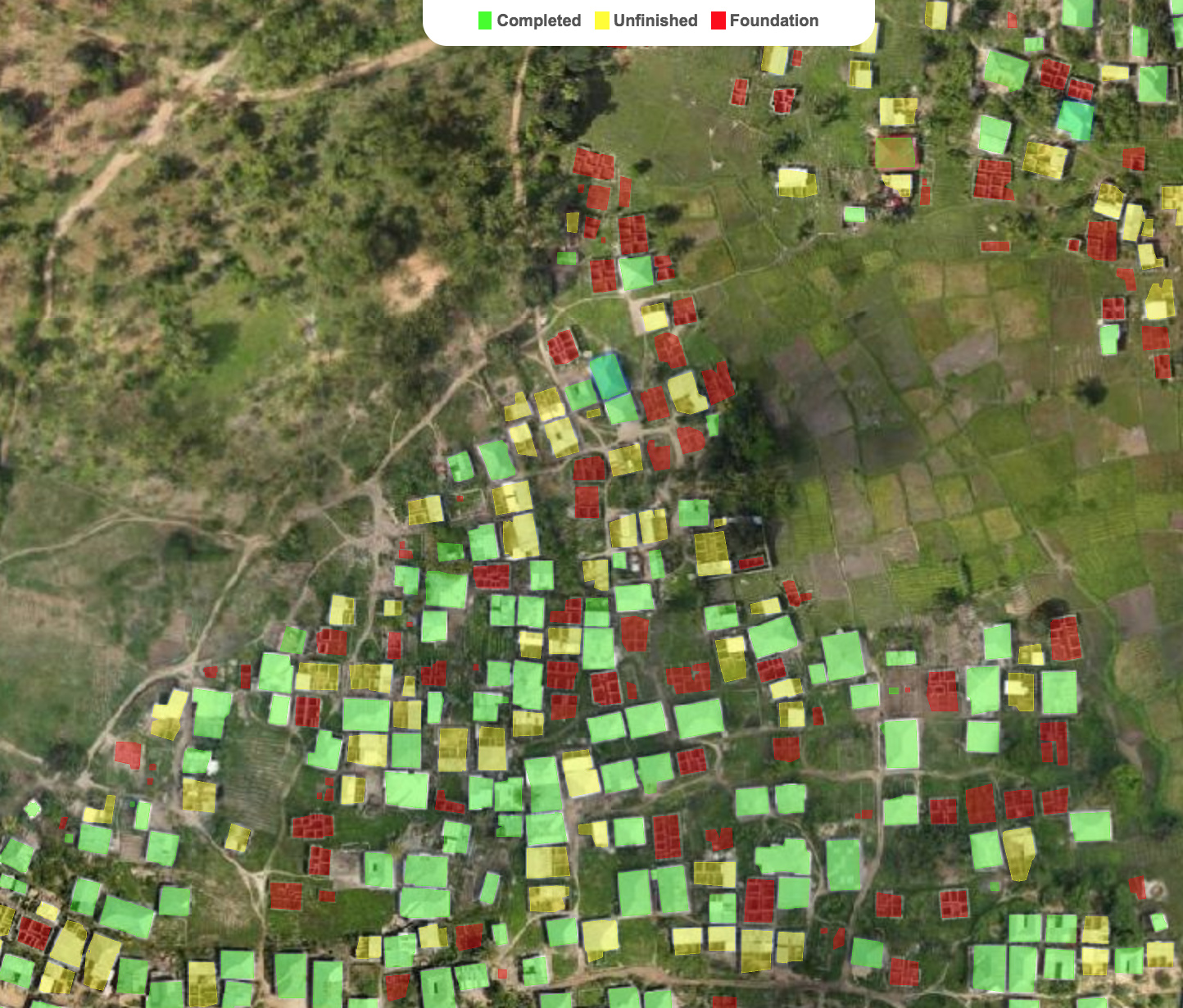
My overall project goal is to keep improving these models and publish notebooks showing the DL model development as well as all the intermediary geospatial data processing steps to make this:
Interactive demo link: http://alpha.anthropo.co/znz-119
Dave