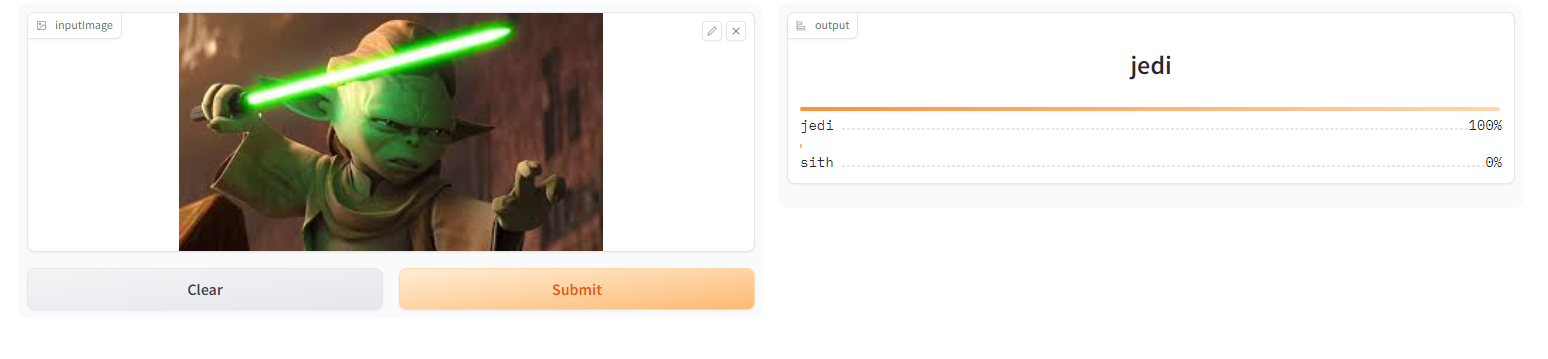
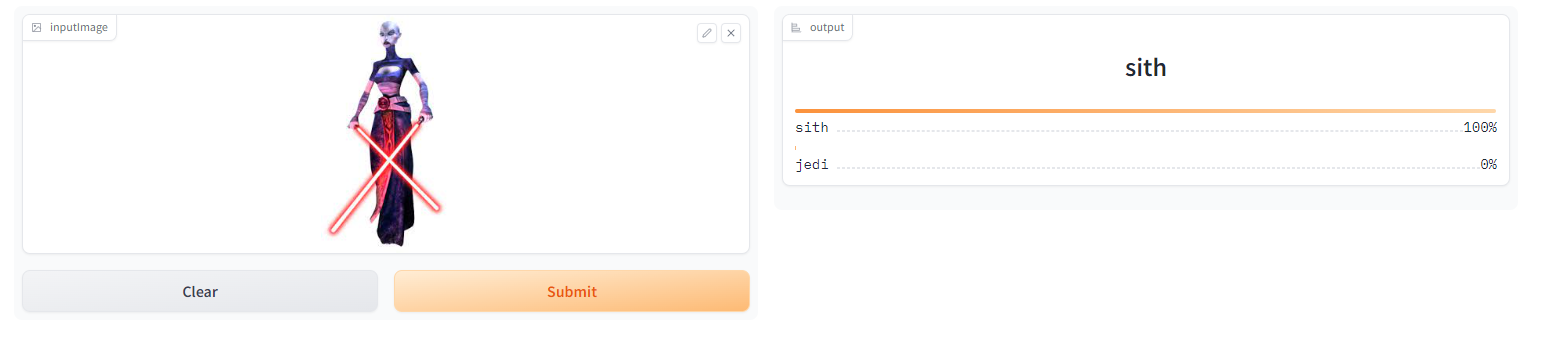
After 2 lessons I created Jedi/Sith detector. The model isn’t that great, because it sometimes thinks images with a dark background are Sith and images with a light background are Jedi. I need to train it with more diverse images.
So, after watching the 1st lecture and implementing an image classifier model for different objects (other than birds) I thought why not help my college mates and get their hands dirty with deep learning. I created a blog using Quarto (coz fastpages is deprecated? ig) and I posted this tutorial.
Also, can someone please suggest python libraries to search and download images? The DuckDuckGo one seems to be hit and miss for me since a few days.
P.S.: This course is just
I recently watched the first lesson and as suggested I tried building a binary image classification model. I do not yet completely understand the code and how it works but I hope as I go through this course, I will develop a better understanding of how all this works.
I tried to classify healthy plant leaves from diseased plant leaves, and the model does a pretty well job at it. I made it on Google Colab and reuploaded it on Kaggle.
Here is the link to the Kaggle Notebook:
I’ve just completed my first session coding (is it a bird or not)
actually I have so problem with downloading the images (list was empty).
I’ve solved it by making changes in search_images function .
this is my notebook in Kaggle.
As a homework for the Lesson 1, I tried to put a twist in the exercise of comparing two things, and allow the user to compare any two things based on their input. Also, I wanted to persist the trained learners between sessions, so the program save them in a SQLite database. Besides creating a new learner, at any time you can test the saved learners with (presumably) new photos.
I realy like the playlists by Jeremy. Recently I do this little prompt engineering course and I thought that it could be usefull to have video transcription textes as prompts and organize it in collections. For this I wrote a little code snippet that you can run in a colab notebook (all you need is a google account - if you have an openai-account you can use extra features).
It manage collections of playlists (examples with some playlists by Jeremy are inside) with its videos, takes transcriptions (bilingual) to:
Great course. I am already finding great value to the tools and the lessons. I just finished Lesson 1.
I built an image categorizer for identifying risks in the aftermath of a hurricane in tropical climates:
I am part of a non-profit that developed an app in the aftermath of Hurricane Maria to crowdsource outages.
One of the challenges we had in PR after Hurricane Maria was the ability to quickly identify the type of damagedscause by the hurricane, specifically damage done to the power lines. Having trees blocking the streets was also a challenge since it delayed the recovery efforts to parts of the island that needed energy back the most urgent. I changed the model Jeremy shared to identify the four categories:
Power line blocking a street
Tree Blocking a street
Power line sparking
power line and tree blocking a street
The model needs a little refinement and I plan on doing that for Lesson 2, but it shows promising results.
I am thinking a model like this can be used to categorize and geolocate user submitted photos of what is causing an outage, independent of the atmospheric event. This could help save lives and expedite the community-led recovery effort.
Suppose you got a video of animals in the Savannah or sprinters in a race and you’d want to group the faces of the people or faces. I used traditional ML, k-means clustering, to be able to cluster a group of extracted faces from any video of your choice.
I found the lesson 2 of the course amazing, so I tried to deploy a waste sorter that will tell you in which trash bin you should throw which item, following the recommendations of the city of Strasbourg, France => link to the notebook
The process of training the model first and use it to clean the data was actually quite fun, and it’s very stimulating to see the confusion matrix get better after each iteration and tweaking the dataset to be representative of the domain.
I found out during this phase that I needed to add more pictures in certain categories (especially between blue and green) in order to help the model differentiate better, I don’t know if that’s bad or not actually (to have a category more represented in the dataset when the confusion is higher on this category)…
I then exported the model, just as the lesson 2 says, and I tried to deploy it on a serverless container on GCP Cloud Run; during this part, it was hard to dockerize the stack, and I finally resorted to use a fastai image in which I installed/re installed some dependencies so that they match the ones used by the learner in the environment of my laptop.
The solution is functional, but the response times are quite slow, I guess this is because the image is so huge (more than 2GB) so startup times for serverless containers slow down the process I guess. Anyway it was a fascinating experience ! I opened a few issues to enhance this application =>
Thank you Jeremy Howard for the deep learning course. I have been kaggling on my own and really enjoyed your first lesson. I used my own portrait dataset to vary the task. Kaggle(FREE one) was extremely slow and inconsistent.
street.jpg===>This is a: street.
Probability it’s a portrait: 0.0001
portrait.png===> This is a: portrait.
Probability it’s a portrait: 1.0000
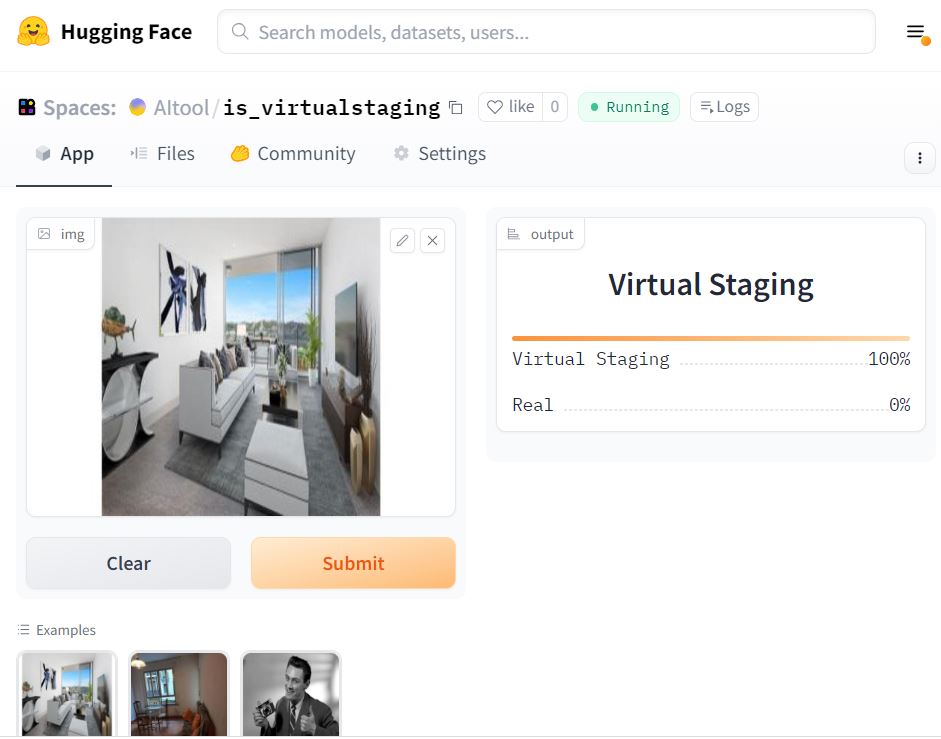
Thank you Jeremy. After lesson 2 I created my first Hugging Face model that detects if an image property image is a virtual staging image or a real image.
Thanks for course! I followed the lessons to create an insect classifier and posted to hugging face. 130133 images over 2000 species using ResNet18. Not enough images for many of the classes (as low as 25), but it does a pretty good job where more images were given. It’s pretty good at detecting classes that had fingers in the training images
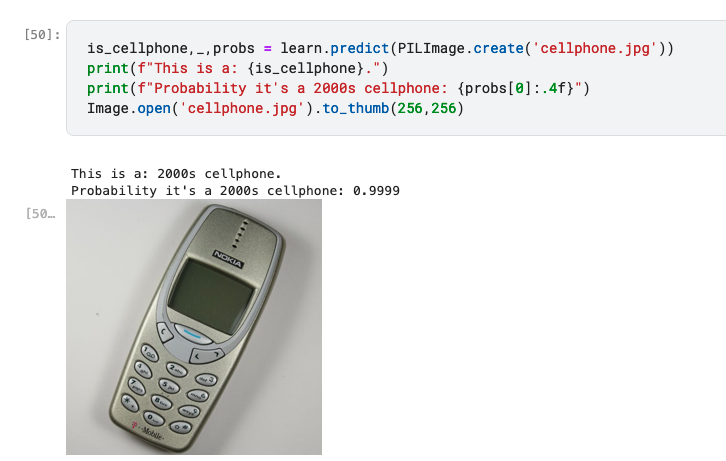
Trained an image classifier to distinguish “brick”-cellphones from the 2000s and smartphones.
Works fairly well.
Noteably, its unsure with blackberries (learns the keyboards, i guess). But also with early iphone iterations. So the model is not only learning keyboard vs touchscreen as features but maybe also other variables depending on the era photo was taken in.
I’ve also build a second classifier to distinguish Midjourney and Stable Diffusion Images. Turns out, you can do this fairly well at a 15% error rate.
Following Lesson 5, I re-created Jeremy’s Linear model and neural net from scratch notebook with my own narration.
It follows the pattern that Jeremy’s does, but I wrote it to improve my understanding of creating a neural net and linear model, and it also includes some tips that absolute beginners should not miss.
Plus, it even contains a section that shows, by coding, why accuracy cannot be used as the loss function in a neural net.
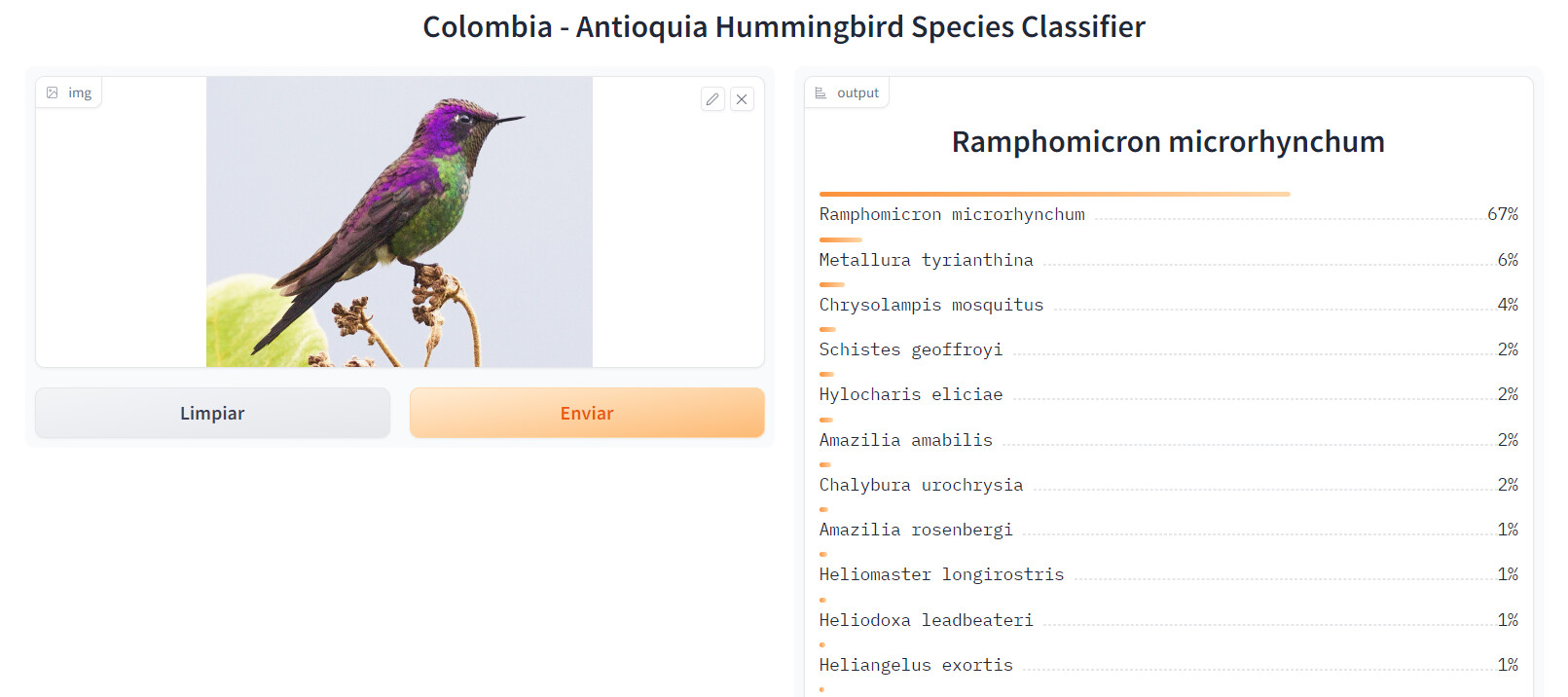
For my first project, I wanted to do something practical for all the bird watchers in my region (I’m from Antioquia, Colombia). Therefore, I made an image recognizer for hummingbird species, an astonishing type of bird, the subject of admiration by many biologists, and admirers of nature.
For the model, I built a dataset of 2800 pictures, containing 50 images of each of the 56 species present in the region. The pictures were downloaded from the internet using ddg API as shown in the course.
I plan to add more species in the future, as well as include other forms of identification such as using the sound of the bird to identify it.