Hi everyone, I have enjoyed following lesson 1 and learning from the python code.
I made some quick modifications to the “Is it a bird?” kaggle notebook.
I was inspired by this clip by Stephen Colbert to answer the question:

Uploading: image.png…
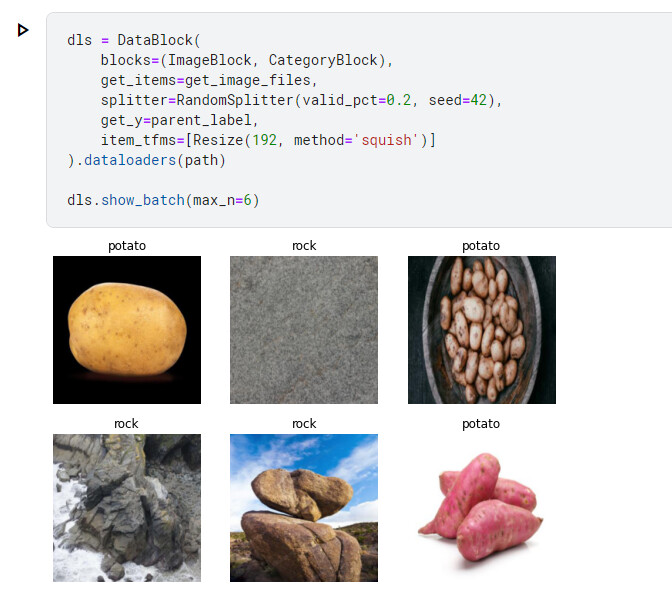
I also liked this one because some potato images look similar to rock from the image search.
There were some issues with this example becuase there were images of the “The Rock”.
Looking forward to meeting up with the other members of the Australia Study Group before today’s talk.