Looking to build, and then share, a recommendation system on this forum using the collaborative filtering packages available in fastai. However, I’m seeking your help to collect the necessary data.
The purpose of the recommendation system is to recommend travel destinations based on individual user profiles. The drive to develop such a model stems from the fact that my fiance and I are getting married at the end of the year, and we’re unsure where we’d like to go for our honey moon. The recommendation system will therefore provide a list of country recommendations based on our individual user profiles.
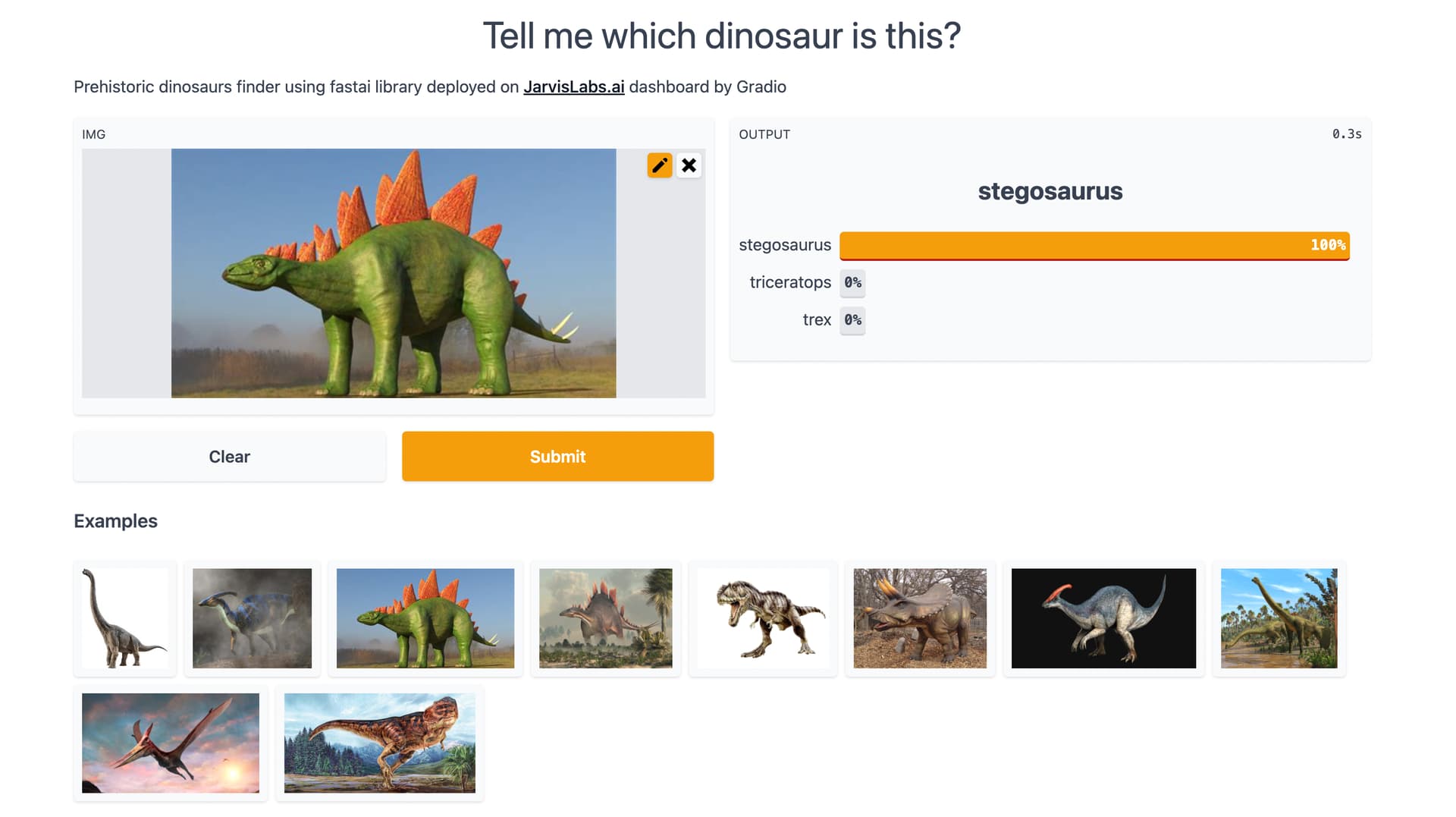
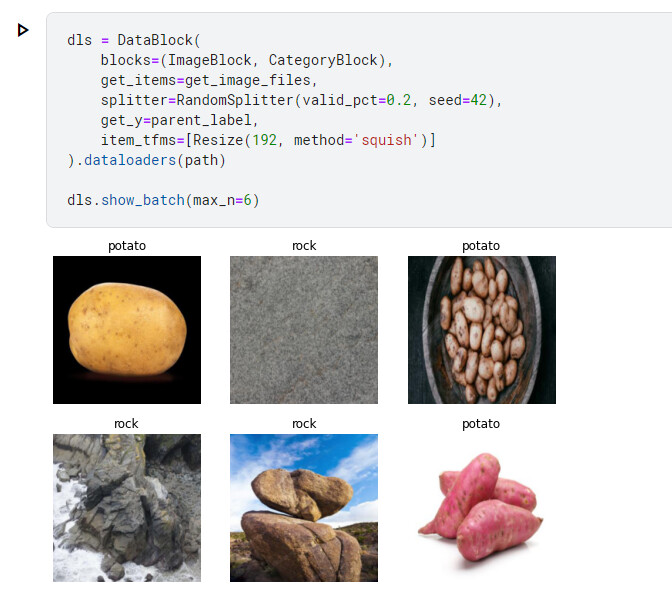
My kid and I keep on surfing the internet for various dinosaurs and their features and habitats and nesting patterns.
He also builds dinos from his lego blocks and building blocks, occasionally does drawing of them.
Recently he is working on building a Jurassic world with all his toys.
I thought it will be fun to build a prehistoric dinosaur identifier for this week’s homework for him to play around with.
I used seresnext50 model and fine-tuned it for 20 epochs.
I was able to achieve 0.248869 error rate. Blog post for more detailed analysis is under construction.
Had to look up what that is. That’s an interesting idea. No idea how I’d implement that with fastai, however. From what I remember of the course and the library, there are some helper functions built into fastai that will at least allow me to determine which examples it found hardest to determine. That might be a start in this general direction of looking under the hood.
I trained a model to detect emotions in a Kaggle notebook. I found getting good images of emotions through DDG search tricky, so I used an existing dataset, a sample of AffectNet with 500 images per class. This data is also pretty noisy, but resnet34 got an error rate around 30% with 5 classes.
Inspired by the Javascript Interface thread I made a little Javascript adventure game that uses the emotion classifier to move between rooms. I pushed it to github and deployed it on github pages.
The game could use a lot of polish, especially around making it easier to capture images from a camera and resize the images before uploading. Currently it requires having some images with facial expressions downloaded and uploading them from a file browser; but it works reasonably well.
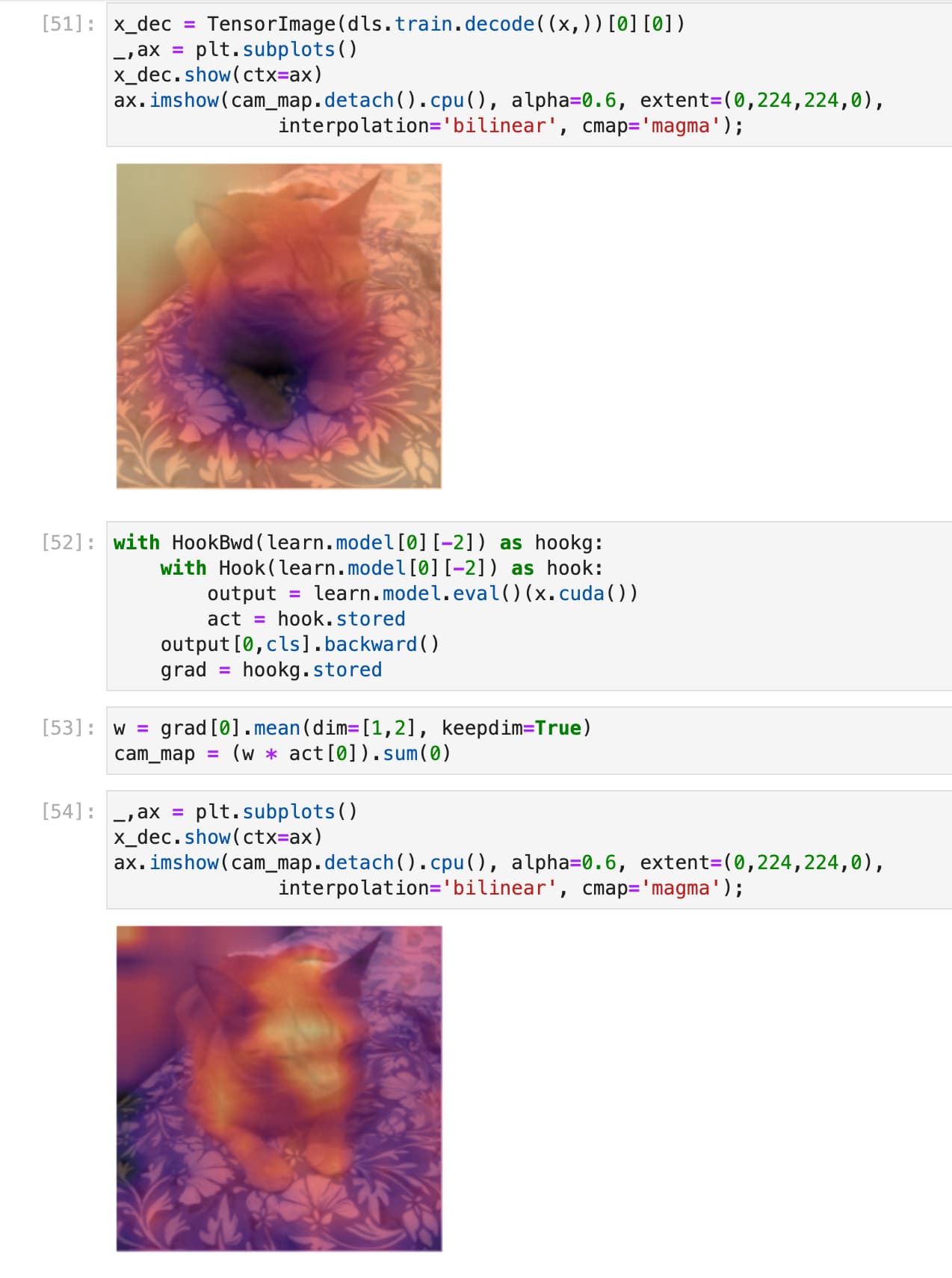
Well, that was a journey! I have relatively little idea of what all this means (chapter 18!), but at least it does seem that the model is activating (if that’s the right word / phrasing) on Mr Blupus and not the pillow or the background.
Thanks for the nudge to try that out. I would never have dared, otherwise, and it gives a bit of extra motivation to do the work to get to the point where I understand all the layers of what’s going on here.
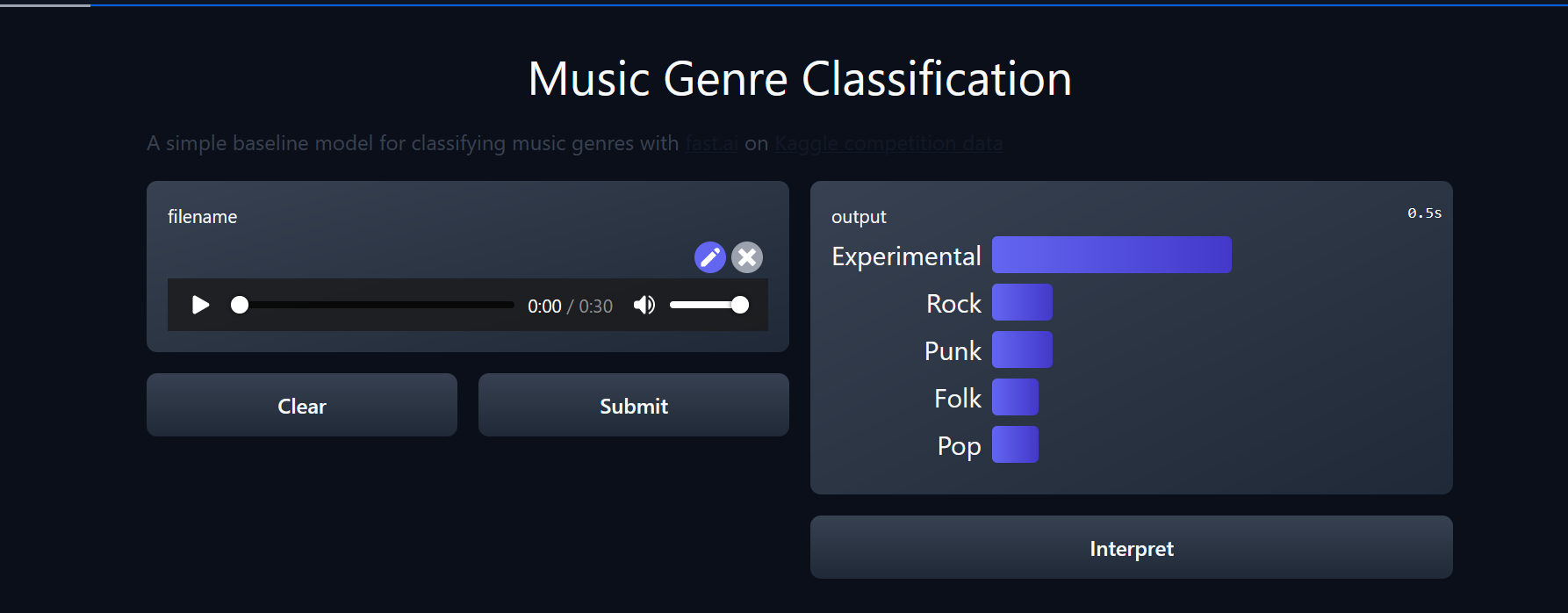
You can check out the model here and thanks for @suvash for explaining how to make hugging-face spaces work and explaining his code during delft-fastai meetup.
Pretty neat that you have the audio → image(spectrogram) right in the inference code, and I see that you’re also using the huggingface+fastai integration functions.
Did you include this in your notebook? If so … please do
Kind of amazing is that this is considered an advanced technique and waits for folks at the end of the book … and yet you figured out how to implement it after the first session of the course. Top > down learning works!
Thanks @suvash for the inspiration to explore Gradio and Huggingface Spaces.
Thanks @strickvl for hosting the delft-fastai study group, and good work using class activation maps to check how your model is working, I will definitely have to give this a go as well!
I took an idea I had when tinkering with a smart home around “private” computer vision - can I use images with detail stripped out and still build a model that can drive certain smart home tasks (ie. lights on/off when someone enters/exits a room). With limited time and using pretty much the standard set of hyperparameters that fastai suggests, I was able to get 85-90% accuracy in a simple multi-class classification using two different types of proxy camera filters.
The background and next steps for anyone interested can be found in this notebook, but the lesson here is that with models that are clearly not optimized for this task can still get good results in a couple hours of time.
This fastai/DL stuff is like magic - but unlike magicians, the fastai team actually reveal their secrets
BTW - I tried to host my notebook on Kaggle but I was encountering an error. Will repost there if I can resolve
Yeah, I kind of figured out the pipeline looking at notebooks made by @dhoa and played around with gradio audio inputs. It worked pretty smooth with the integration.
Yet one thing I noticed was two of the three gradio demos showing audio feature were having some issues.