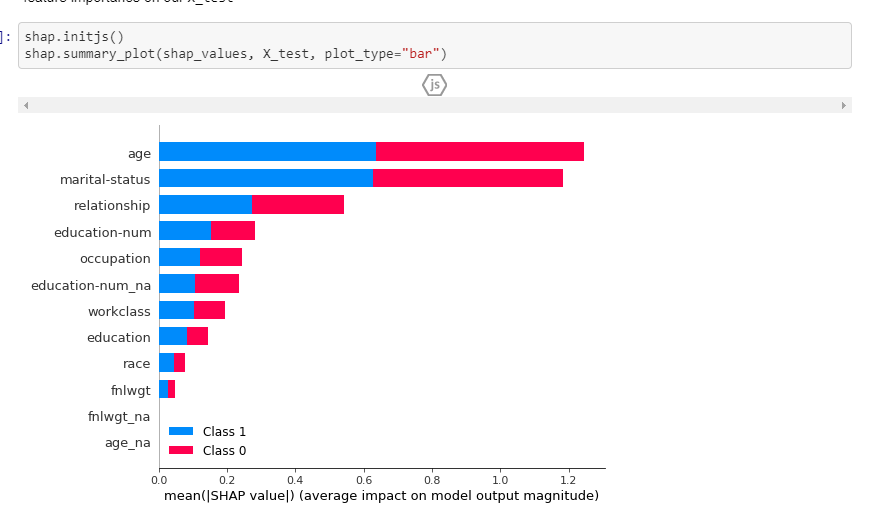
Just finished week 2 lesson and wanted to try something myself.
I have trained a guitar (acoustic or electric) classifier with images from google search and got a respectable 96% accuracy.
Then I proceeded to deploy it on a server with a basic frontend.
Some gotchas along the way:
Data cleaning is really important if your source is not very reliable (mislabeling, irrelevant images).
Got a ~5% increase in accuracy just by doing that.
Following the first point, even with the great widgets included in the Lesson 2 notebook, cleaning is time consuming expecially with a large dataset.
When deploying remember to use the CPU only version of PyTorch if it’s only used for inference.
Dropped its size from 700MB to 100MB, useful for environments with limited resources.
Found a useful and powerful library in FastAPI, based on Starlette, as it’s easy to setup and uses async/await.
I’ve spent the last month or so exploring GANs (generative adverserial networks), and decided to write a detailed tutorial on training a GAN from scratch in PyTorch. It’s basically an annotated version of this script, to which I’ve added visualizations, explanation and a nifty little animation showing how the model improves over time.
Thanks a lot for sharing this @JoshVarty!
The blog post and repo you’ve shared are excellent!
You’ve very clearly explained and demoed how you can use self-supervised learning using fastai v2. Great job!
There are still lots of questions to be answered, so please, keep sharing your insights.
Hey guys!
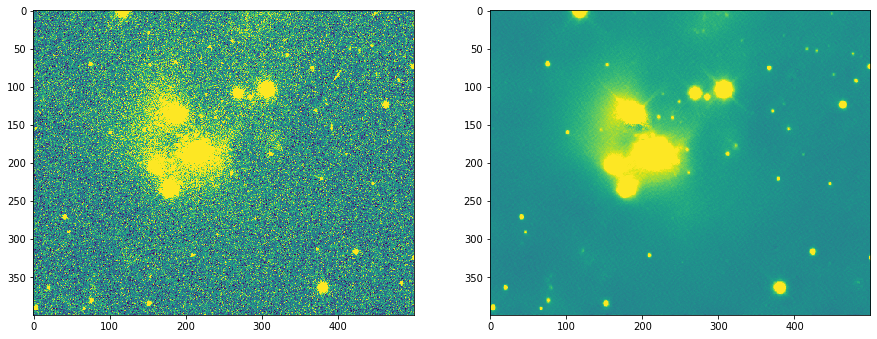
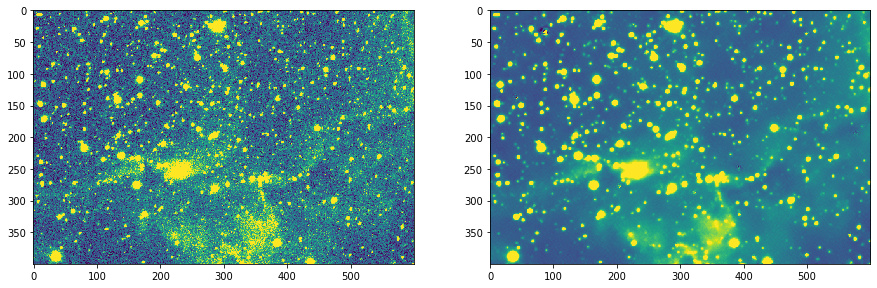
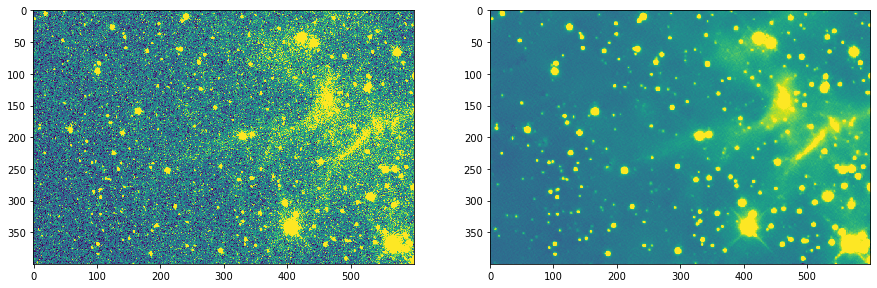
I’ve been working on a project that was an intersection of two of my hobbies: astrophotography and deep learning. Specifically on denoising astropictures. And even more specifically on the so-called photon noise. This is a poisson distributed noise which is a dominant type of noise in light-starved astroimages.
I don’t have a presentable notebook yet, but the results I’m getting make me really excited. So for now please accept my verbal explanation
My model is very close to plain vanilla UNET with pre-activations and some other tricks that seem to work well for image processing tasks (rather than classification). Mish activations and Spectral norm instead of bachnorm.
I used perceptual loss based on VGG but was taking activations before RELU for loss calculation purposes. This helped to remove large portion of grid artifacts
The model was trained on images from a single telescope/single camera combination with images from R,G and B filters. I wish I had much more diverse set of images, but even such limited dataset seems to be working for other telescope-camera combinations as well (though not as well).
The trck in training wasnot to use any augmentations on raw images as this will break down real noice characteristics of individual pixels. So I used only random crops. The train set was created by creating pair of images: raw unprocessed image from a CCD camera and a corresponding stacked image. Stacking multiple images reduces noise and improves S/N ratio. Then raw and stacked images were aligned by moving rotating the stacked image but having raw imaged untouched to preserve its characteristics.
Attached are three images
First one is an image from the same camera/telescope but taken through Ha filter (deep red, cuts light pollution, brings nebulas)
Second and third are from a different telescope/camera combination taken through Sulfur filter (very low information at this wavelength and S/N is pretty terrible).
I’m really happy with how it turned out.
Limitations:
This work has limited scientific applicability. It was designed to produce visually pleasing images, rather than scientifically usable ones.
The stars on second and third images look swollen compared to original. This is because the train dataset had oversampled images (stars spanning 3+ pixels in diameter), while the test dataset was on undesampled images (<3 pix FWHM). Expanding the trainset beyond one telescope/camera should help to alleviate problem to a some degree.
I hope this makes sense. Please forgive my grammar/spelling.
Just trained it in few hours. It is a Natural Disaster detector by satellite and does an evaluation on how much the damage in color and detector the damaged house on the map. Different color means different level of damage. Color box is the damaged house location. One interesting is 1 is no damaged and 0 is un-classified. And my model has no issue with defining un-classified houses and no damaged house.
I wanted to incorporate some of the fastai v2 audio library into this, but I wasn’t sure how best to do it.
The dataset I’m using is from the LifeCLEF 2018 Bird dataset, and I re-implemented the BirdCLEF baseline system into Jupyter notebooks with some refactoring done along the way with the fastai v2 library.
The basic idea of what I did was:
Take the dataset, and use the baseline system’s methodology of extracting spectrograms to get a large amount of spectrograms for each of the 1500 classes of bird species.
From there, I did the classic transfer learning technique of training my model against the spectrogram images, on a ResNet model pretrained on ImageNet. I got down to about a 27% error rate!
I just wanted to post this now as I begin to tie it up to see if anyone had any feedback or questions. I’m going to be presenting my work at Localhost, a talk in NYC on February 25th if anyone is around! I’ll be presenting fastai v2 and the audio library to a big audience, so hopefully it will get more people interested in the library
I’m going to cross-post this in the deep learning audio thread as well. If anyone has any feedback or advice or is in need of more clarification please let me know! I wanted to post it to the community early to have a conversation around it as I developed it more
FastAI beats academic research performance in Indoor Scene Recognition?
For Lesson 01, I took the indoorCVPR dataset (A. Quattoni, and A.Torralba. Recognizing Indoor Scenes. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.) which tries to classify among 67 indoor scenes.
This is my first time reading through an academic research paper on this topic. But it looks like their best performance was 73.4% accuracy. After applying the Lesson 01, I was able to get an accuracy of 77.0%! If I’m misinterpreting the paper, please let me know!
I posted my notebook on GitHub and I would greatly appreciate any peer-review with how I set it up. I would be grateful to learn from your experience!
Also, although I was happy that the performance was better than the reported performance in the paper, I was a bit disappointed that I was not able to achieve the same type of accuracy as Jeremy showed in the lecture. I really wanted the error_rate to be in the single digits percentage. But looking at the error_rate plot, it seems to start to level out around 0.2. I suppose this is due to the nature of the dataset. However, if you notice anything that I can improve on, I would be happy to hear!
Well, it’s better, but you are comparing with a 2009 paper, before the spread of CNNs, which gave a general boost to classification performance. To have an idea of the state-of-the-art, I would search for more recent papers citing this one. E.g., in https://arxiv.org/pdf/1801.06867.pdf 86% is reached, however you have to read details to understand if it is fully comparable with the original paper.
Improved version but not enough.
It is recoloring image from black and white.
Input Black and White,----------------------------Output color,----------------------------Correct Color
Below is before imrpoving, so we can see it solved the fuzz eyes problem. (or it can be fixed by training with more epos, I am not sure. If it can, plz tell me because I can only train with very few epos on colab)
In addition, if you look below, it can not recolor those bow-knot and
hair accessories before improvement. Or I don’t call a improvement. It should be a trick from a dum guy.
Before I try to improve it with no large data set it can not color hair accessories, bow-knot, and more. But now it can improve bow-knot. It seems it does not really need to use larger data set to color smaller items. I can select what object to be colored. But it is still unable to recognize many objects other than people.
I think I will stop this project for a monument because I won’t have time for this.
Just wanted to share a blog post about an app my team members and I worked on at a hackathon this past weekend. Our project uses fastai to detect whether or not you are getting distracted while studying using your webcam feed.
Badminton or Tennis Image Classification with 50 images
Hi Friends!
I have made an image dataset by collecting 50 images each of Tennis & Badminton game in action by downloading images from google and created an image classification model using chapter 1. The accuracy of my classification model is 85%.
The images which it did not predict correctly are as below:
I created a classifier to classify between a passenger aircraft and fighter jet following lesson-2 notebook and deployed it to azure container instance.
Only able to get it to 80% accuracy, and fine tuning does not improve the score, but still, this is pretty good since a human wouldn’t be able to do it this well.