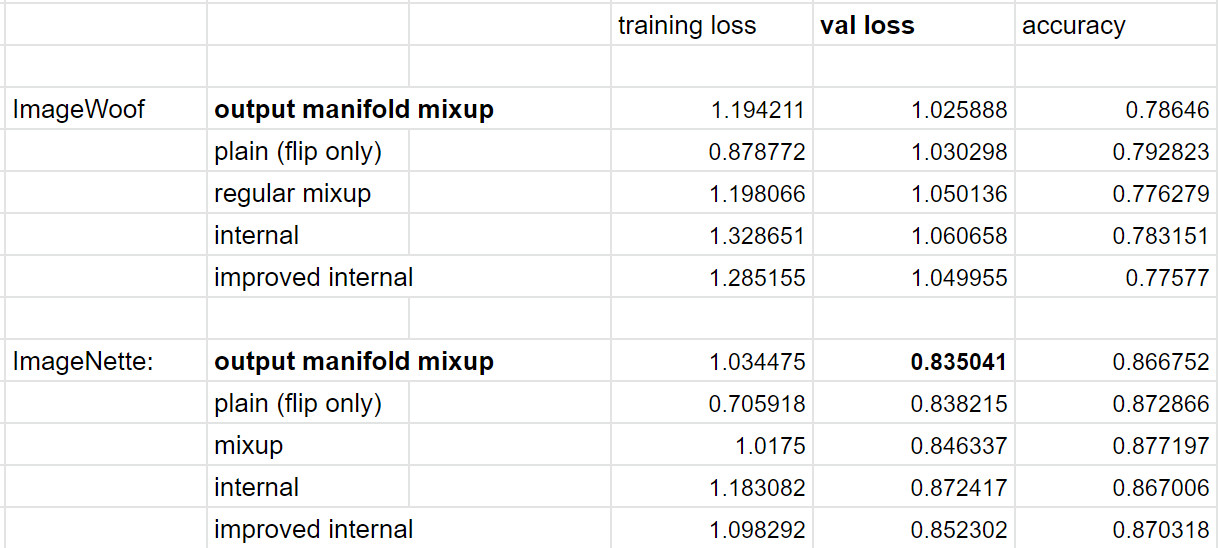
First results!
1 - The ‘improved internal’ consistently outperforms the original version.
2 - In general it now outperforms ‘regular or input’ mixup (vs before it did not).
3 - The output mixup still performs best so far (Woof, Nette, private med database).
4 - Works great on EfficientNet 
Big thank you for your work @nestorDemeure!