Yes I would be happy to setup and test on both ImageWoof/Nette and a medical dataset I am working with for my current work.
I can hopefully get this done tomorrow and will update here.
Very excited to see this is available and also hope we can get it running in FA2 in the future, but let’s make sure it’s proving out with v1 in terms of results :).
If the method proves worthwhile I could probably work on a fastai V2 port next weekend (I have yet to install V2 as I would prefer to wait for the official release date).
I am personaly interested in both the possibility to easily use mixup on arbitrary inputs (which is there even if it does no better than input mixup) and improved calibration of the predictions (which I will measure on a personnal dataset in the next few days).
Awesome! For what it’s worth - I switched my work from V1 to V2 last week and V2 has been quite stable…
I’m just tweaking a few augmentations (brightness, etc) and need to get BatchLossFilter (from @oguiza’s outstanding work) into v2 but I’ll be running v2 going forward.
Thus at least from my experience, v2 is looking pretty solid at least in terms of vision work at this point.
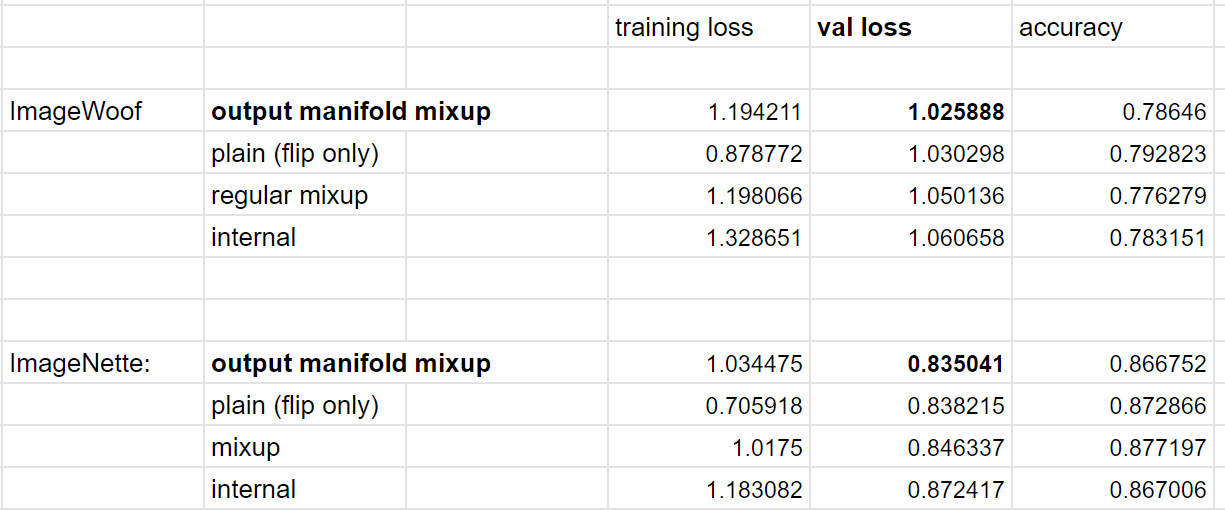
Great work @nestorDemeure - I was able to test both version of manifold today and in every case (all three datasets) output_manifold produced the best validation loss.
For my own work, it smashed the best validation loss I’ve had to date by a large margin (output_manifold + standard augmentation).
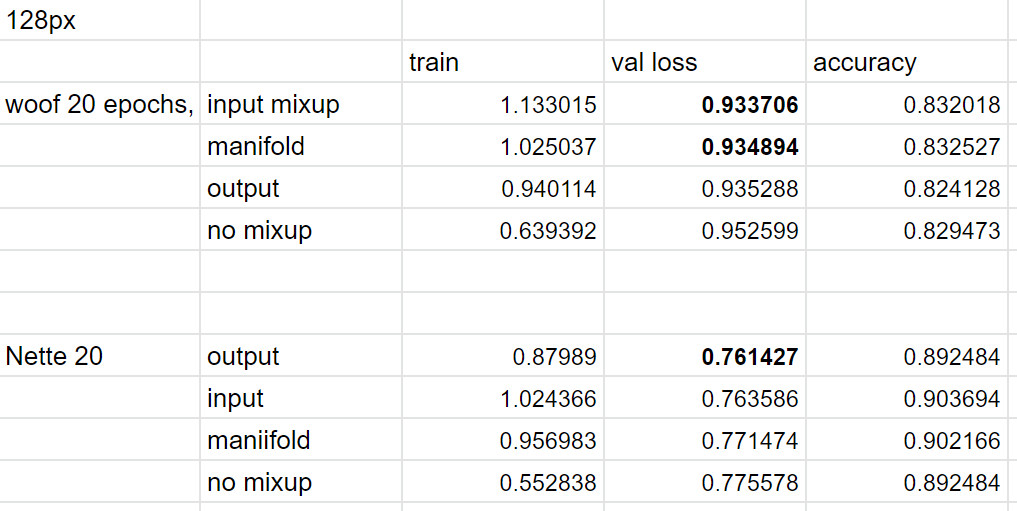
Here’s the standard benchmarking results (effect was not as big here as I only used flip + mixup versions, but in each case had the best results):
The internal manifold mixup consistently was the worst btw so I’d say no need to support that going forward.
For my own dataset I am using B4 and B5 efficientnets. It was hooking the last swish layer so I just wanted to confirm that is expected (I was thinking last conv layer and got the error about repeated forward pass) but as noted, it clearly did work.
If you are able to update it for FAi v2 I think it would be a very worthwhile addition!
internal is just letting manifold mixup draw a layer at random ? (as opposed to you forcing a single internal layer for all the run)
In which case great ! It correlates with what I observed while implementing mixup (that manifold mixup was more effective when, by luck, it sampled from the latest layers) which pushed me to add output_mixup.
I will try to implement it in V2 this weekend (the UI will probably be a bit simplified : using the lattest non-loss / non-softmax layer unless the user explicitely pass a target module).
Great decision @nestorDemeure - it’s working super well for my own dataset and proved out on the benchmark woof/nette.
If you have a chance to write this up for FastAI2 this weekend I would greatly appreciate it as I can put it to use right away for testing on woof/nette and private work dataset.
Thanks for your development work on making this!
It is a logical incremental improvement so I am quite sure that there is already a paper somewhere implementing it (plus I found a blogpost proposing the same idea).
The authors of manifold mixup explained that injecting mixup within a resblock can cause problems and make the method fail. Thus they instrumented only the input of the network and the output of resblocks.
This might explain the disappointing results we get. I will update the code in about 10 hours(done!) to:
use a module list if the user provide one
otherwise use only ManifoldMixupModule if there are some in the network
otherwise use only Resblocks if there are some in the network
otherwise use all non recurrent layers
The sad thing is that it make the automatic application of manifold mixup to network that contain no ResBlocks potentially complicated (here output_mixup is clearly advantageous).
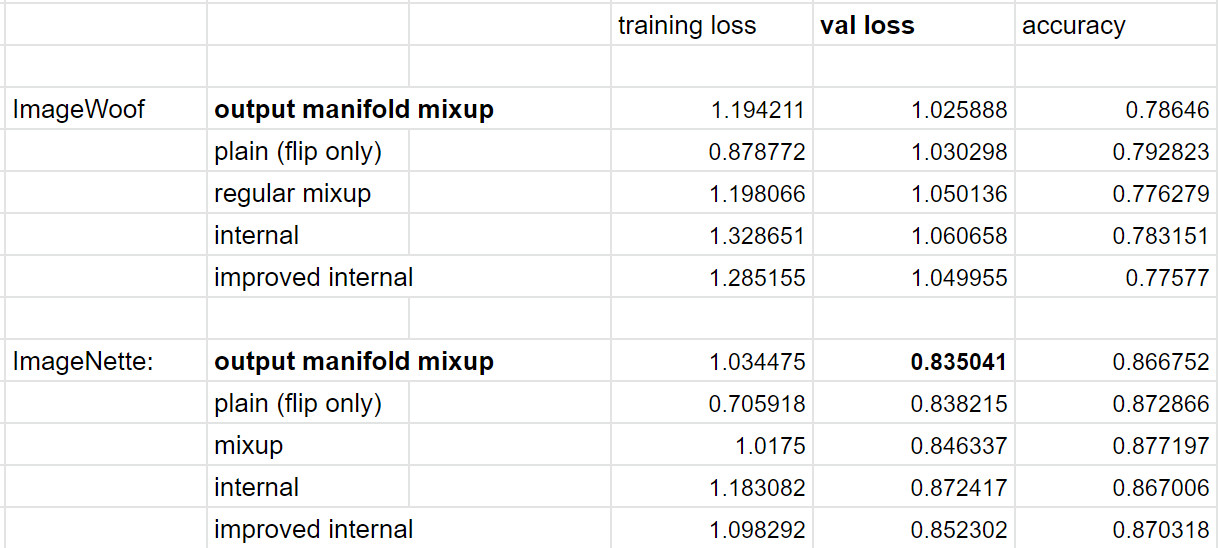
The code has been updated. @LessW2020, have you the time to rerun a bench on manifold_mixup to see if things improved ? (no need to retest output_mixup as it was not modified)
Thanks @nestorDemeure! Yes I can benchmark again. My only request is please instrument for EfficientNet automatically
For my work EffNet’s are performing far better than ResNets so that’s all I’m working in now on a daily basis.
Anyway let me redo the benchmarking with XResNets for this and will update!
also I really like the printout you added regarding blocks detected at the start of training…
that kind of preview info is really helpful to make sure things are working up front instead of finding out the hard way later.
Great for the benchmark! I believe we have now a proper reproduction of what they did in the paper (I even added some refinements, found in the literature, for U-Net)
Do you think I should focus on output_mixup for V2 or keep both versions ?
I would definitely focus on output_mixup for v2 first and get that working as that’s the clear winner on all fronts.
If you then have time, I do think keeping internal mixup is worthwhile as it’s now outperforming standard ‘input mixup’. And input mixup is a mainstay so beating that means it clearly has merit and may perform better than output for some cases (segmentation?)
@LessW2020, another thing you might want to try is an alpha of 1 (instead of 0.4, the default value) as it is the value used for the paper (while 0.4 is the value used in fastai’s implementation of input mixup).
I did no proper benchmark I as have no V2 code so, @LessW2020, I am counting on you to confirm that things work properly
(by the way, any help to get the demo notebook closer to the V1 one is welcome, the V2 equivalent to simple_cnn seem to not like single channel, black and white, pictures)
I’ve tested Woof 128 and now about to test Nette 128 - however I thought I’d also test with alpha=1 but it’s blowing up when I set the alpha with:
~/fastai2/fastai2/learner.py in call(self, event_name)
23 _run = (event_name not in _inner_loop or (self.run_train and getattr(self, ‘training’, True)) or
24 (self.run_valid and not getattr(self, ‘training’, False)))
—> 25 if self.run and _run: getattr(self, event_name, noop)()
26
27 @property
~/fastai2/nbs/manifold_mixup.py in after_batch(self)
164 def after_batch(self):
165 “Removes hook if needed”
–> 166 if self._is_input_mixup: return
167 self._mixup_hook.remove()
168
~/anaconda3/lib/python3.7/site-packages/fastcore/foundation.py in getattr(self, k)
221 attr = getattr(self,self._default,None)
222 if attr is not None: return getattr(attr, k)
–> 223 raise AttributeError(k)
224 def dir(self): return custom_dir(self, self._dir() if self._xtra is None else self._dir())
225 # def getstate(self): return self.dict
Here’s the results with v2:
a little more mixed though in all cases mixup better than just regular augmentation (default was flip and randomresizecrop).

 (I even added some refinements, found in the literature, for U-Net)
(I even added some refinements, found in the literature, for U-Net)