I’ll go on details about the new modules of fastai_v1 tomorrow but before this, I wanted to spend a bit of time on a data augmentation technique called Mixup. It’s extremely efficient at regularizing models in computer vision, from what I’ve seen, allowing us to get our time to train CIFAR10 to 94% on one GPU to 6 minutes. The notebook is here, and we’ll be releasing a full conda environment to reproduce the results on a p3 instance soon (basically: you need libjpeg-turbo and pillow-simd).
What is mixup?
As the name kind of suggests, the authors of the mixup article propose to train the model on a mix of the pictures of the training set. Let’s say we’re on CIFAR10 for instance, then instead of feeding the model the raw images, we take two (which could be in the same class or not) and do a linear combination of them: in terms of tensor it’s
new_image = t * image1 + (1-t) * image2
where t is a float between 0 and 1. Then the target we assign to that image is the same combination of the original targets:
new_target = t * target1 + (1-t) * target2
assuming your targets are one-hot encoded (which isn’t the case in pytorch usually). And that’s as simple as this.

Dog or cat? The right answer here is 70% dog and 30% cat 
As the picture above shows, it’s a bit hard for a human eye to comprehend the pictures obtained (although we do see the shapes of a dog and a cat) but somehow, it makes a lot of sense to the model which trains more efficiently. One difference I’ve noticed is that the final loss (training or validation) will be higher than when training without mixup even if the accuracy is far better, which means that a model trained like this will make predictions that are a bit less confident.
Implementation
In the original article, the authors suggested three things:
- Create two separate dataloaders and draw a batch from each at every iteration to mix them up
- Draw a t value following a beta distribution with a parameter alpha (0.4 is suggested in their article)
- Mix up the two batches with the same value t.
- Use one-hot encoded targets
Why the beta distribution with the same parameters alpha? Well it looks like this:
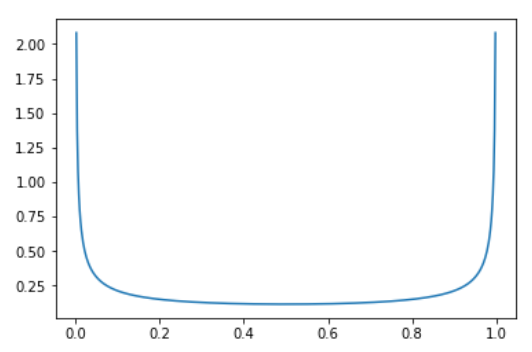
so it means there is a very high probability of picking values close to 0 or 1 (in which case the image is almost from 1 category) and then a somewhat constant probability of picking something in the middle (0.33 as likely as 0.5 for instance).
While this works very well, it’s not the fastest way we can do this. The main point that slows down this process is wanting two different batches at every iteration (which means loading twice the amount of images and applying to them the other data augmentation function). To avoid this slow down, we can be a little smarter and mixup a batch with a shuffled version of itself (this way the images mixed up are still different).
Then pytorch was very careful to avoid one-hot encoding targets when it could, so it seems a bit of a drag to undo this. Fortunately for us, if the loss is a classic cross-entropy, we have
loss(output, new_target) = t * loss(output, target1) + (1-t) * loss(output, target2)
so we won’t one-hot encode anything and just compute those two losses then do the linear combination.
Using the same parameter t for the whole batch also seemed a bit unefficient. In our experiments, we noticed that the model can train faster if we draw a different t for every image in the batch (both options get to the same result in terms of accuracy, it’s just that one arrives there more slowly).
The last trick we have to apply with this is that there can be some duplicates with this strategy: let’s say or shuffle say to mix image0 with image1 then image1 with image0, and that we draw t=0.1 for the first, and t=0.9 for the second. Then
image0 * 0.1 + shuffle0 * (1-0.1) = image0 * 0.1 + image1 * 0.9
image1 * 0.9 + shuffle1 * (1-0.9) = image1 * 0.9 + image0 * 0.1
will be the sames. Of course we have to be a bit unlucky but in practice, we saw there was a drop in accuracy by using this without removing those duplicates. To avoid them, the tricks is to replace the vector of parameters t we drew by
t = max(t, 1-t)
The beta distribution with the two parameters equal is symmetric in any case, and this way we insure that the biggest coefficient is always near the first image (the non-shuffled batch).
All of this can be found in the mixup module, coded as a callback. The bit that mixes the batch is in MixUpCallback, and the bit that takes care of the loss is in MixUpLoss (that will wrap a usual loss function like F.cross_entropy if needed). The final mixup function is in the train module, to deploy this in one line of code when needed.
