Hi everyone!
I continued working on something I shared above, a combinatorial data augmentation (CDA) technique. Now adapted to the multi-class case, and tested it again on the Fashion MNIST dataset (10 classes). I used its 60,000 image dataset for testing (instead of training), and its 10,000 images dataset for training, since the goal of the technique is to be used precisely when the number of images is low.
As an example, we may want to build a classifier when we have 8 images per class for training, and 2 images per class for validation (a total of 100 images since there are 10 classes). The benchmark is to do transfer learning with resnet34, based on the 80 training images, and save the best model based on error rate on the 20 validation images.
The CDA technique would instead grab the 80 training images, such as:
and generate more than 100,000 collages such as:
These collages are generated by picking 2 random classes, and then 9 random images within the selected 2 classes, and placing the images in a 3x3 array. The label of the collage is the class that appears the most among the 9 images that make up the collage.
The total number of possible collages is 45*16^9>10^{12}, so one can really have a large number of collages if desired, even with only 8 training images per class.
With the generate collages one can do transfer learning on resnet34 (a few epochs, tuning more than just the last layer, until error rate on a validation set with 20% of the collages is low e.g., 1%). And follow this with another transfer learning now with the original 80 training images (just as in the benchmark, but starting from the network trained on the collages rather than on resnet34).
The error rate with CDA on the 60K images used for testing is significantly lower than the benchmark. The following shows these error for different number of images per class on the training set (starting at 8 images per class, as exemplified above).
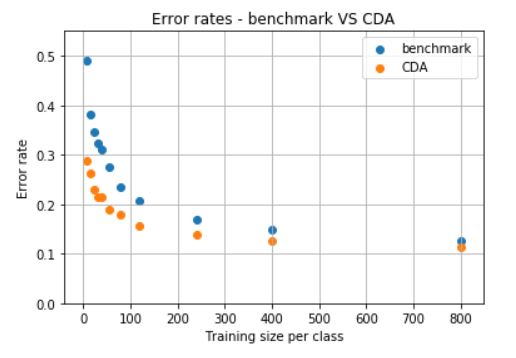
And their ratios are:
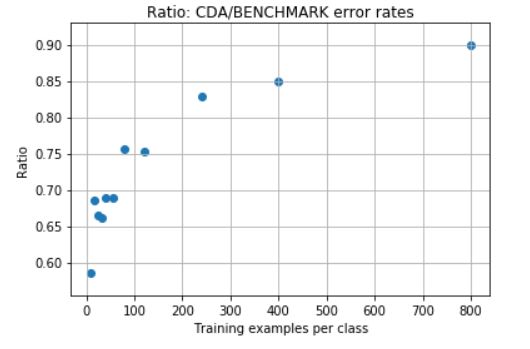
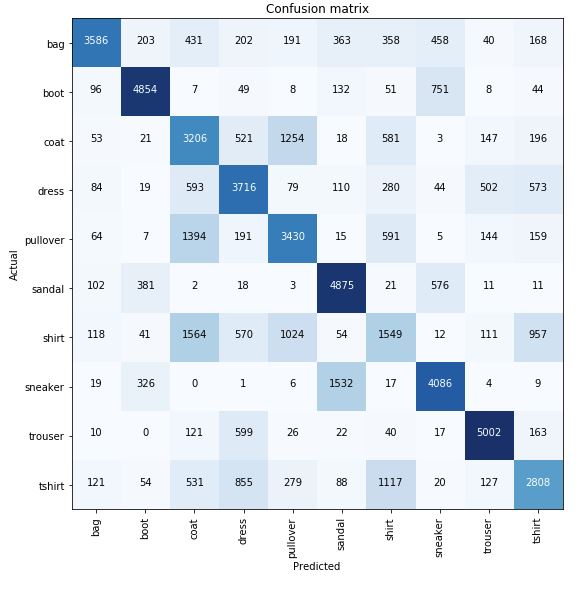
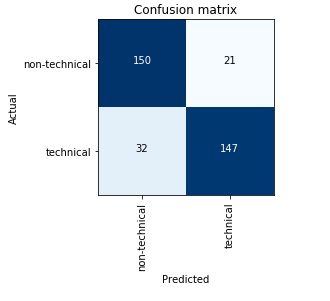
We can also see in the confusion matrices (benchmark vs CDA), how the performance improves with CDA.
Benchmark:
CDA:
Notebooks and readme: https://github.com/martin-merener/deep_learning/tree/master/combinatorial_data_augmentation


 Actually, PyTorch scheduler is nothing more than a kind of callback with some specific methods. Therefore, I don’t think there should be any different from the implementation of
Actually, PyTorch scheduler is nothing more than a kind of callback with some specific methods. Therefore, I don’t think there should be any different from the implementation of