I am a Chinese foodie who eat and cook a lot! So I’ve built a super ‘delicious’ model to identify some very similar Chinese food. And by ‘delicious’, I mean it really made me hungry when I looking over the datasets. Check this out!
I finally got a 79% accuracy which was not very outperforming but was beyond my expectation, because sometimes I can’t even tell the differences between them. However, I printed out the images that the model got the wrong answers on and I noticed some were noisy data that I haven’t cleaned out, also some were actually recognizable by human. So there still a large space for improvement.
To see how the model was doing on differentiating some similar food, I modified the original function most_confused() in fastai library and create a new function called most_confused_mutual() to return the model’s confusion between any of two classes. For example, one of the results were presented as: ('Braised_Pork', 'Dongpo_Pork', 4, 5, 9) which means the model incorrectly recognized Braised Pork as Dongpo Pork for 4 times and 5 times for the opposite case, and 9 times in total. This method can show us how similar some pairs of classes are, and help us to figure out whether it is a model problem or just the datasets are too difficult even for human.
Hi everyone,
This is my first post here to this thread. I did the 2018 course but without as much of my “own” work as I wanted to do. Doing the 2019 course, much more intensively. I have worked for a long time in financial markets and am very interested in economic history and bubbles. Thus, I am very into things like how gold has been used as a store of value for thousands of years. I’ve also followed the evolution of cryptocurrencies, especially the debate about whether they can be true stores of value, independent of fiat currencies. Anyway, for my first project, I decided to do an image classifier, to classify between gold, silver, and copper coins. I got about 97% accuracy which I was thrilled with. I created a webapp on Render, which I have to say was a lot easier than I thought it would be. I’ll post the code at a later date, but here is the webapp. https://classify-gold-silver-copper-coins.onrender.com/
I’m excited to write a longer post on Medium. Thanks to the entire fast.ai team for their life-changing work.
Wow, these are amazing results! How big is your dataset and what type of spectrogram do you use (i.e. sampling rate, window type, size, overlap, etc).?
My task is a bit different, I am identifying whether or not the file has a manatee call in it, and my results are not anywhere near what you’ve got!
I’m going over part 1 of the course, and for week 1 homework, I got ~79% accuracy doing classification on a subset of sounds from the BBC sound effect archive. I thought that figure was pretty ordinary until I just started week 2 when Jeremy points out the other student that got 80% which represents a new SoA! Also, I was trying to discern between sounds categorised as “Aircraft”, “Boat”, “Car” and “Train”, so 79% is certainly a lot better than I would do by ear… and the spectrographs certainly look the same to me!
It’s just a toy project for now, but it was fun! Here’s the notebook, here’s a medium post covering the overall project, and here’s another medium post with painful detail about the data acquisition & preparation.
No fancy tricks I’m afraid, most of my effort was in the data prep, otherwise I basically followed the week 1 notebook
After Lesson 7, I tried my hand at building a super resolution model that restores movie poster images (by improving image quality and removing defects). I trained it on a dataset of ~15,000 movie poster images, which I was able to find for free online.
The first step was to get some images of movie posters. I found a website which had a large database of images. They had an API which was quite easy to use, and it wasn’t too hard to build some code to automatically download 15,000 images
Next, I needed to create my lower-quality images. I created a “crappificate” function (inspired by Jeremy’s crappify function), that reduces image size, reduces image quality, and draws a random number of circles of random size and color on the image. The circles can be red, yellow, or brown. The idea is that it simulates someone spilling ketchup, mustard, or BBQ sauce on a movie poster
Creating the model after that was not too hard, as I was able to use a lot of Jeremy’s code from the lesson. There are a few parts of it I don’t understand yet (e.g. the gram matrix loss function, why we set pct_start to 0.9 when training, and the [5,15,2] layer weights values we pass into the loss function), but it sounds like we might cover this in Part 2
One other interesting thing was that I used rectangular images, rather than square images (I trained with sizes of 192x128 and 384x256). It seemed to work, but I remember Jeremy saying in an earlier lesson that using rectangles properly requires a fair bit of nuance, so I’m hoping we cover this in Part 2 as well
From the pictures it looks like you are using data augmentation for “normal” pictures.
I am not sure if this is of help for frequency spectrogram data as you make it harder for the network to associate a region with a specific frequency.
Did you tried it without the data augmentations that “mess up” this location frequency link, i.e., no rotation or flip?
I would expect that this should work better, but I never worked with similar data.
Maybe you find also interesting approaches in this thread by searching for them, as I remember other posts about spectrogram data.
Actually, thinking about this a step further after reading the docs. I’m not sure it will help. In theory, a car noise played (seen) backwards is still going to sound (look) different to a plane noise backwards. It’s more about adding some extra pixel values to the dataset to encourage better generalisation. But that said, none of the images in the validation set - or real life - will ever be transformed; it’s not like a photo where you’re going to get a slightly different angle of a bear. The input data is always going to be a certain orientation.
I don’t know. I’ll try, and see.
Update - Thanks @MicPie, that suggestion did improve things! I changed the ImageDataBunch parameters to include ds_tfms=get_transforms(do_flip=False, max_rotate=0.), resize_method=ResizeMethod.SQUISH. Training on resnet50 with 8 epochs and a chosen learning rate resulted in a final error rate of 0.169173, better than the previous ~0.21. So that’s around 83% accuracy, even better than the other SoA sound classification result from @astronomy88.
I’d love to know why this made a difference. Hopefully it will come up in the remaining weeks. Now I’ve watched week 2 - time to serve this model up in a web app…
As to the Data set , it was about 12 Spectograms per whale , so it was as u can see not that big , the reason for that , is , on the internet , u do not get whales sounds of about 3 minutes long or something like that , and even if u do , it is just the same 10 first seconds that keeps repeating , so it was quite difficult , and that’s the reason why i’ve been able to make spectograms for only 8 types of whales & not more ( i have to admit that i’m a bit frustrated by that).
by the way i’ll publish the Notebook soon , if u have any questions feel free to ask , i’ll be delighted to help.
I just started with Deep Learning using your FastAI course and am two lessons down.
Found an interesting dataset on Kaggle on different art forms.
This is my first project here.
It predicts the type of art, whether it is a drawing or a painting or something when fed with an image. I achieved an accuracy of 94% while using FastAI.
Thanks Jeremy. Faced some difficulties while using Kaggle and FastAI together, but managed all those and am proud of this notebook, with many more to come
Hey, @MicPie is right, data augmentations are not helpful for spectrograms, neither is pretraining with imagenet.
Try this and see if you can improve even more.
set pretrained=False when creating your cnn_learner (this will turn off transfer learning from imagenet which isn’t helpful since imagenet doesn’t have spectrograms)
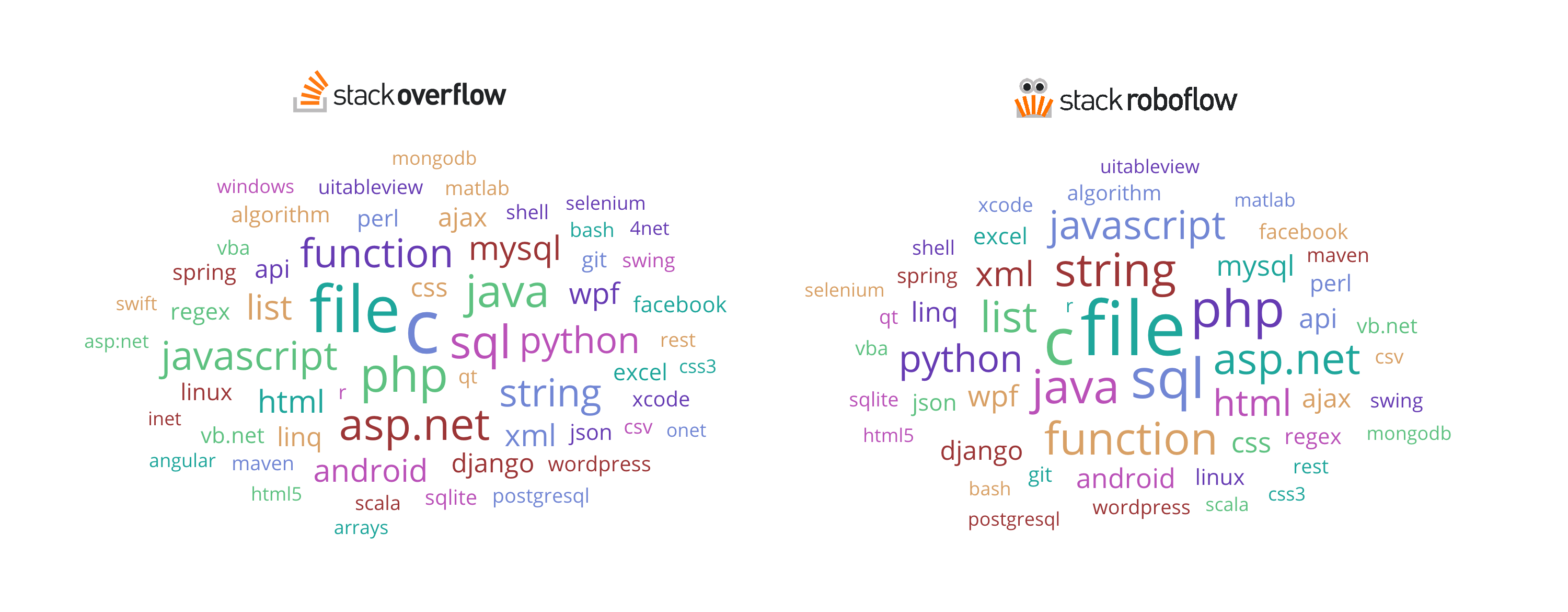
I spent my weekend working on improving Stack Roboflow. I updated the display of the generated code so it looks more natural (removed a bunch of whitespace noise that was a result of the tokenizer).
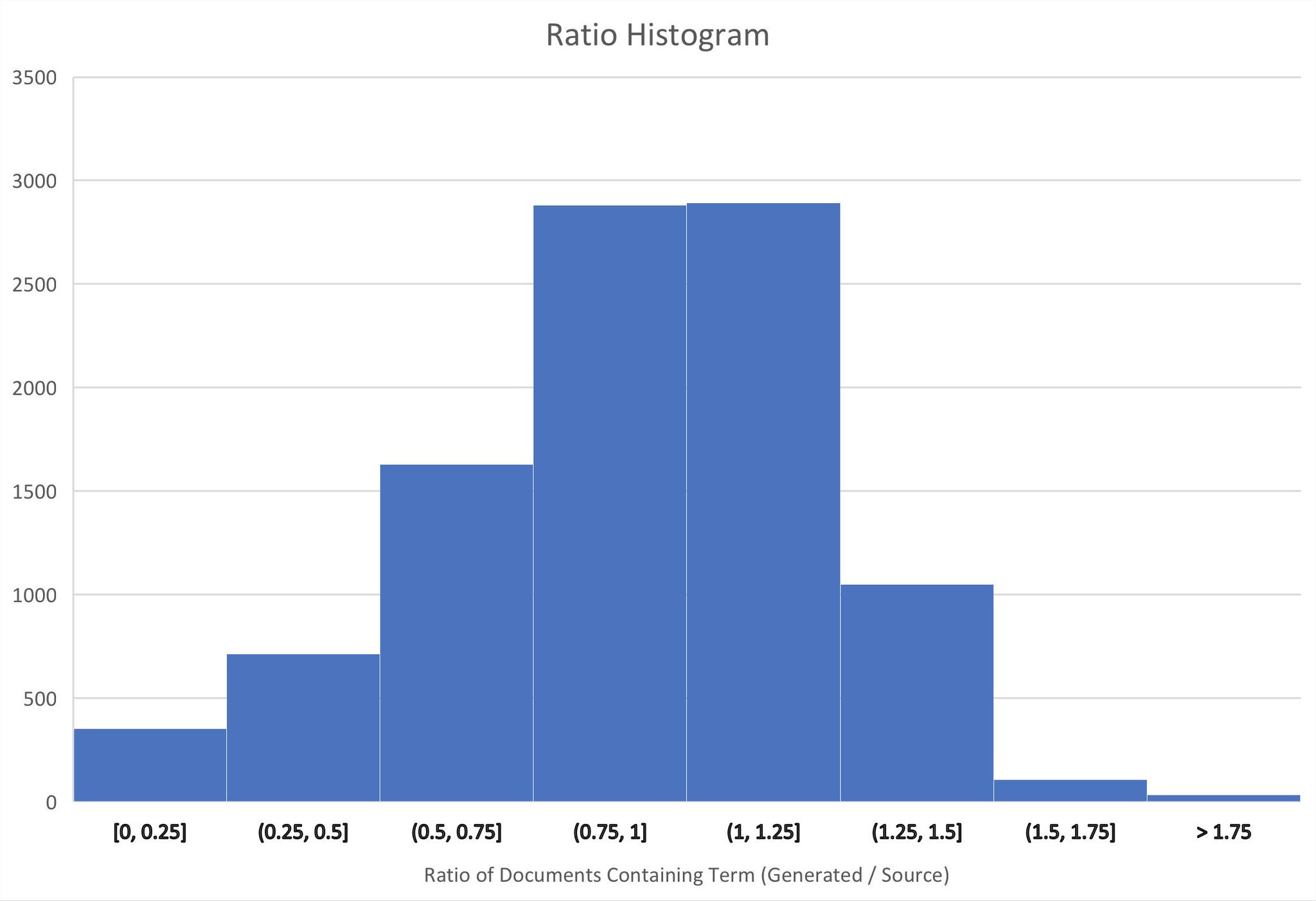
I also linked it up with Elasticsearch (search engine is live here for data exploration!) so I could start understanding what it’s outputting. One of the most interesting things I found was that certain terms from the training data are over-represented and others are under-represented in the language model’s output.
After digging in a little bit it seems that terms which are common in both the wikitext dataset and my own training set tend to be over-sampled. And ones that are primarily present in my dataset are under-sampled. My hypothesis is that this has to do with transfer-learning.
For example, most oversampled (weighted by frequency of occurrence are:
file-get-contents
do-loops
dos
do-while
2-way-object-databinding
windows-server-2008-r2
windows-server-2008
get-request
http-get
get
gets
get-childitem
apt-get
windows-server-* (6x)
post-redirect-get
@devforfu I checked out the link to the notebook for complete implementation of the Training Loop and it seems empty.Could you please look into that and once again ThankYou for helping me Understand the FastAI Library Better.I am also Interested in implementing a lot of fastai stuff from scratch in Pytorch for better Understanding it and would like to contribute in case you are interested
@at98 Oh, thank you for letting me know! That’s awkward, I didn’t even remember how that happened but you’re right, the most recent commit in the master contains an empty notebook. Here is a link to the commit with the notebook before it was (accidentally, I believe) deleted:
And, here is the repository:
Sure, I would be glad to get any contribution to this little project It is mostly an educational thing, of course, and super-simple. I am going to continue work on it during Part 2, especially because now we’re going to dig deeper and start work on “low-level” details.
@devforfu I would be happy to contribute in whatever way I can.I am not an expert in Pytorch but I will work to construct some of the stuff from scratch.Did you find any difference in speed while training CIFAR10 using the Pytorch Scheduler that u mentioned vs the fastai method.One thing that i think lacks in fastai is accepting more than 3 channel Input.IN many Competitions I have seen That Input could be upto 20 Channel(DSTL Satellite Image Segmentation).Maybe we can come up with some method to add that.
@ThomM, I believe that I have had success in the past using “ds_tfms=None” when working with spectrograms. Though, it looks like you may have been approaching that with so many kwargs!
 Check this out!
Check this out!





 , Glad U liked It , i’ll Soon share the Function That I used , it might be usefull to U as well.
, Glad U liked It , i’ll Soon share the Function That I used , it might be usefull to U as well. )
)