This is very interesting! What happens if the background is not black - does joining different images confuse the model? What if there are classes that come out of the side of the image - then combining the images doesn’t make too much sense. How fast is it to combine the images into a collage and feed into a minibatch?
Obviously I don’t expect you to have all the answers but rather they’re just some questions to think about
Generating about 50,000 collages takes a few minutes, but I am sure my function to do this is not very efficient. Regarding the other questions, I really cannot tell because I only test this thoroughly on the Fashion MNIST dataset. I would love to try it in another dataset to find where the CDA approach fails. There could be certainly issues with images having characteristics as the ones you mention.
Language model trained on a data dump of Stack Overflow that mimics coding questions.
If you find a good one you can share it with the permalink (click the “Fresh Question” button to get a new one).
Interesting things I’ve noticed so far:
It does a remarkably good job of context switching between programming languages based on the semantics of the question! If the question is about SQL it often includes SQL in < code > tags. If it’s about JavaScript it will include JavaScript! The syntax isn’t perfect due to the tokenizer mangling some things but it’s pretty close!
The grammar isn’t perfect but it’s pretty good.
It doesn’t seem to lose closing track of closing tags and quotes.
It’s my first time posting in this forum, so I wanted to say many thanks to everyone who is making this course so great.
I wanted to share what I have been working on for week 2.
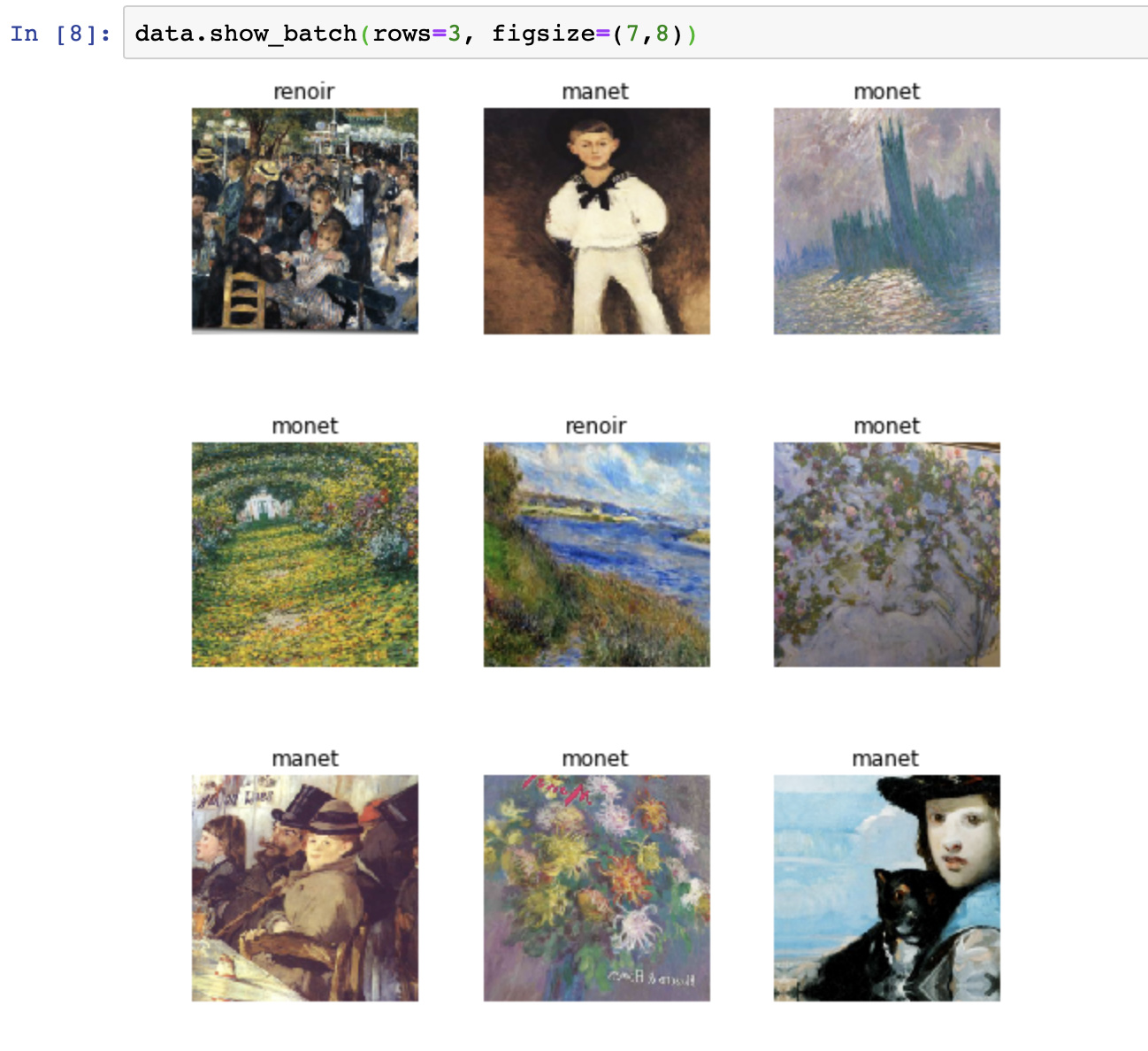
I wanted to see if I was able to create a classifier that could distinguish between paintings from Monet, Manet, and Renoir.
Since they are from the same art movement (impressionism), it can be quite challenging to see the different styles.
I can get up to a 0.80 accuracy, which is not very high, but I believe that with a better training set it could improve.
No unfortunately I ended up having to train on a subset (~1/16 of the available data) because the full amount wouldn’t fit in memory.
In retrospect I made a poor choice in choosing the first 1/16 of the data because now it doesn’t know about more recently invented programming topics. If the site gets popular I’ll be improving the model going forward though!
No manual data cleaning. I did have to convert it from XML to CSV so I stripped the new lines and replaced them with a new special XXNL token. And I filtered out “answers” which were in the same data dump to use at a later date.
Yes, me too. I’m not sure why the accuracy is so high but I suspect it’s because programming has lots of highly repeated things.
For example, if you’re in a code block and you see an open paren, there’s probably a close paren coming. And if you’re writing JS and see “var x” the next token is likely “=“.
This is an area I’d like to explore more. I’d love to get a dump of all public GitHub gists and see how well a language model could learn to generate code.
As I advance through the course, I’ve worked on my first NLP project. The objective was to measure the tonality/sentiment of a tweet. I started with the language model trained on WikiText-103, fine-tuned it using a sample of tweets from the Sentiment140 dataset.
From there, I was able to create my tweet classifier which remains basic, as it has difficulty detecting sarcasm.
Hey, I used your model on my dog (black goldendoodle) and got a really surprising result if I’m interpreting it correctly.
It was toy_poodle (9.34%), bouvier_des_flandres (8.27%), standard_poodle(5.75%). I’m assuming his breed isn’t in the list, but it really surprised me to see the top class have less than 10% probability. It must be really confused haha. Thanks for sharing
Pic in question. Actual breed: goldendoodle (AFAIK)
It’s my first time posting in this forum, and I want to say really thank you to fast.ai and Jeremy and everyone in the community.
I came across fast.ai only last summer with almost no coding or AI experience whatsoever and really learned a LOT from the community. (To be honest, I was too reluctant and timid to post on the forums up to this point … one of my biggest regrets) Through fast.ai I was able to learn
Coding basics and I mean everything!!! Through going through forums and posts from the awesome community, I was able to learn from bash to deploying containers with docker, (AWS, bash, ubuntu, tmux, vim, python frameworks such as Django and Flask, just to name a few!) fast.ai not only gave me the opportunity to practically learn artificial intelligence even as a novice, it really opened a whole new world of computing, programming, and data science to me and I am extremely grateful - cannot thank you guys enough.
Practical deep learning (as the name suggests) from a top-down approach (as Jeremy has often referred to). To be honest, I’ve tried Data Science and AI courses in Udemy before joining fast.ai when I was a complete beginner but was not able to get a good feel and grasp on it … Often it was too complicated and intimidating and was rather impractical that can be only applied to certain use cases. Also, it was hard to get help from others since it was a closed community. (Plus, it cost several dozen dollars!!)
Life lessons and philosophies. For example, the “top-down approach” notion that Jeremy mentioned in his class really struck and literally was a complete paradigm shift for me. Until then, I was going through fundamental python online classes but literally had no idea on where to apply and utilize it. However, through the “top-down” approach I was able to have a complete clear notion on where, what, and why to apply this knowledge; becoming able to learn remarkably faster - through derivatively looking up things I didn’t know on the forum, documentation, googling. Literally a game-changer in the dynamics of my life!!!
Again, thank you to fast.ai and Jeremy and everyone in the community. fast.ai has without a doubt, opened up whole new possibilities for me and forever has changed the course of my life.
I am a Chinese foodie who eat and cook a lot! So I’ve built a super ‘delicious’ model to identify some very similar Chinese food. And by ‘delicious’, I mean it really made me hungry when I looking over the datasets. Check this out!
I finally got a 79% accuracy which was not very outperforming but was beyond my expectation, because sometimes I can’t even tell the differences between them. However, I printed out the images that the model got the wrong answers on and I noticed some were noisy data that I haven’t cleaned out, also some were actually recognizable by human. So there still a large space for improvement.
To see how the model was doing on differentiating some similar food, I modified the original function most_confused() in fastai library and create a new function called most_confused_mutual() to return the model’s confusion between any of two classes. For example, one of the results were presented as: ('Braised_Pork', 'Dongpo_Pork', 4, 5, 9) which means the model incorrectly recognized Braised Pork as Dongpo Pork for 4 times and 5 times for the opposite case, and 9 times in total. This method can show us how similar some pairs of classes are, and help us to figure out whether it is a model problem or just the datasets are too difficult even for human.
Hi everyone,
This is my first post here to this thread. I did the 2018 course but without as much of my “own” work as I wanted to do. Doing the 2019 course, much more intensively. I have worked for a long time in financial markets and am very interested in economic history and bubbles. Thus, I am very into things like how gold has been used as a store of value for thousands of years. I’ve also followed the evolution of cryptocurrencies, especially the debate about whether they can be true stores of value, independent of fiat currencies. Anyway, for my first project, I decided to do an image classifier, to classify between gold, silver, and copper coins. I got about 97% accuracy which I was thrilled with. I created a webapp on Render, which I have to say was a lot easier than I thought it would be. I’ll post the code at a later date, but here is the webapp. https://classify-gold-silver-copper-coins.onrender.com/
I’m excited to write a longer post on Medium. Thanks to the entire fast.ai team for their life-changing work.
Wow, these are amazing results! How big is your dataset and what type of spectrogram do you use (i.e. sampling rate, window type, size, overlap, etc).?
My task is a bit different, I am identifying whether or not the file has a manatee call in it, and my results are not anywhere near what you’ve got!
I’m going over part 1 of the course, and for week 1 homework, I got ~79% accuracy doing classification on a subset of sounds from the BBC sound effect archive. I thought that figure was pretty ordinary until I just started week 2 when Jeremy points out the other student that got 80% which represents a new SoA! Also, I was trying to discern between sounds categorised as “Aircraft”, “Boat”, “Car” and “Train”, so 79% is certainly a lot better than I would do by ear… and the spectrographs certainly look the same to me!
It’s just a toy project for now, but it was fun! Here’s the notebook, here’s a medium post covering the overall project, and here’s another medium post with painful detail about the data acquisition & preparation.
No fancy tricks I’m afraid, most of my effort was in the data prep, otherwise I basically followed the week 1 notebook
After Lesson 7, I tried my hand at building a super resolution model that restores movie poster images (by improving image quality and removing defects). I trained it on a dataset of ~15,000 movie poster images, which I was able to find for free online.
The first step was to get some images of movie posters. I found a website which had a large database of images. They had an API which was quite easy to use, and it wasn’t too hard to build some code to automatically download 15,000 images
Next, I needed to create my lower-quality images. I created a “crappificate” function (inspired by Jeremy’s crappify function), that reduces image size, reduces image quality, and draws a random number of circles of random size and color on the image. The circles can be red, yellow, or brown. The idea is that it simulates someone spilling ketchup, mustard, or BBQ sauce on a movie poster
Creating the model after that was not too hard, as I was able to use a lot of Jeremy’s code from the lesson. There are a few parts of it I don’t understand yet (e.g. the gram matrix loss function, why we set pct_start to 0.9 when training, and the [5,15,2] layer weights values we pass into the loss function), but it sounds like we might cover this in Part 2
One other interesting thing was that I used rectangular images, rather than square images (I trained with sizes of 192x128 and 384x256). It seemed to work, but I remember Jeremy saying in an earlier lesson that using rectangles properly requires a fair bit of nuance, so I’m hoping we cover this in Part 2 as well
From the pictures it looks like you are using data augmentation for “normal” pictures.
I am not sure if this is of help for frequency spectrogram data as you make it harder for the network to associate a region with a specific frequency.
Did you tried it without the data augmentations that “mess up” this location frequency link, i.e., no rotation or flip?
I would expect that this should work better, but I never worked with similar data.
Maybe you find also interesting approaches in this thread by searching for them, as I remember other posts about spectrogram data.

 ,
,
 Check this out!
Check this out!


