Here you go. Also, what I meant by the randomness of the heat-maps is that I couldn’t find a similarity in the way these heat-maps shape up for different input images. Would like to know your findings. Cheers.
are you saying that when you used different dog pictures, the activations at each layer showed no similarity in the heat map? 
It does seem suspicious. Have you checked whether there is some marker in the text itself that shows whether it is ‘real’ or ‘fake’? Perhaps there is some data leakage going on
1 Like
Something like that. To be precise, what I meant was I couldn’t see any generalisation in the earlier layers. Heat-maps from the last layer almost always seem to be concentrated at some feature of the class I’m trying to maximise, so that’s fine.
Have a look here and see if you can figure out any common trait in the heat-maps from earlier layers (all except the last one or two).
2 Likes
Hey nice heatmaps. Yeah, I can’t see any intuitively recognisable pattern. I suppose the upside from the layers activating differently is just in case I need to “picasso” my selfie and “hook” one of them for some sort of perceptual loss.
Here’s the repo with an initial nb and the dataset: https://github.com/ricknta/fake-news
I’ve written the following short Medium post diving deeper into the Fastai library, doing some code review, and looking at the concepts we deepened into during Lesson 6.
I have focused mainly on the one_item() and one_batch() functions, what methods they call, and their internal logic.
2 Likes
Given Elon’s erratic Twitter behavior and trouble with the SEC, I thought it would be fun to build a “Musk-like” Tweet generator trained with over 6,000 of his tweets from 2010-2018:
It starts with the language model (WikiText-103) discussed in lesson 4 and is fine-tuned with Elon’s tweets. Thank you to @alvisanovari for the Zeit template as your Walt Whitman generator was a helpful starting point!
Head here to generate your own tweet or review the code (my first commits ever were today!). Thanks to @rachel and @jeremy for teaching a finance guy how to build an app in 8 weeks 
Below are some of my funnier tweets. Please follow me or tweet me your favorite tweets on Twitter (I have no followers yet haha). I’m still playing around with the “temperature” parameter to control the “randomness” factor.
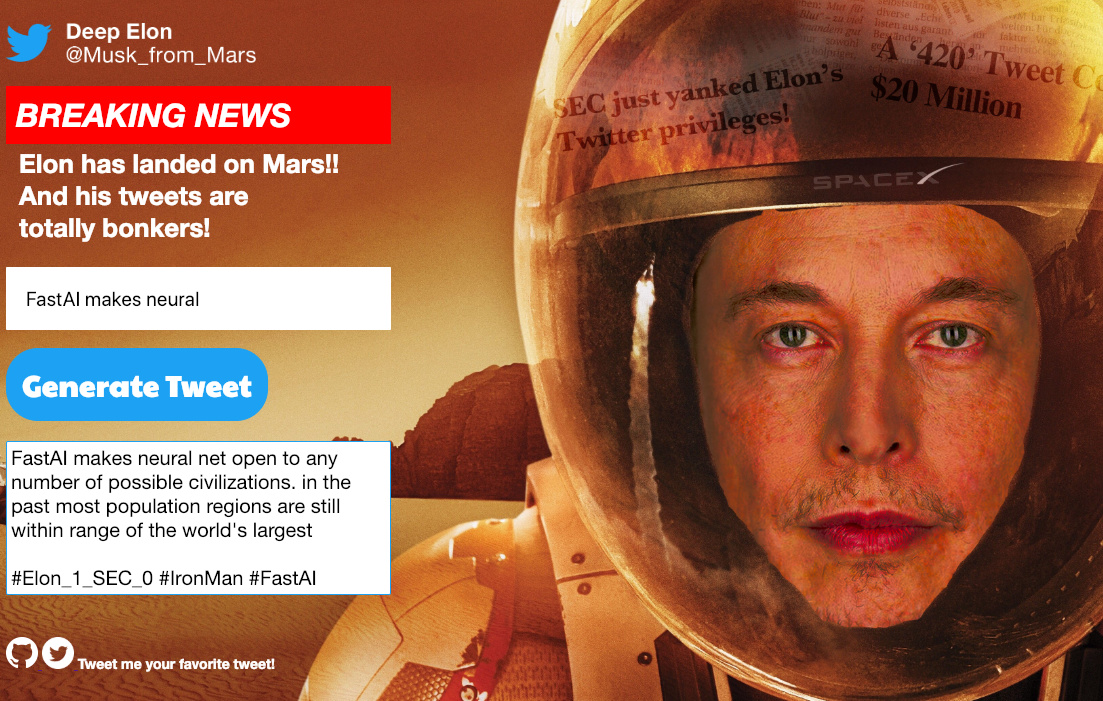
Other Tweets:
- “Humanity will also have an option to publish on its journey as an alien civilization. it will always like all human being.”
- “Mars is no longer possible. with the weather up to 60% it is now a place where most human water deaths are in winter.”
- “AI will definitely be the central intelligence agency. if it can contact all about the core but this is how we can improve the pace of fighting of humanity in the future”
Tweet take-aways:
-
FastAI makes neural nets open to all (TRUE)

-
Humanity is on a journey to an alien civilization

-
Mars is no longer possible


-
AI will definitely be the CIA


23 Likes
Awesome 
I saw today that v1 of the fastai library was available as Kaggle Kernels.
I think Kernels are a great learning platform–earlier this year I adapted the fast.ai Part 1 v2 notebooks to run in the Kernels environment: https://towardsdatascience.com/announcing-fast-ai-part-1-now-available-as-kaggle-kernels-8ef4ca3b9ce6.
I got the lesson1-pets notebook from v3 running as a Kernel, and you can find it here: https://www.kaggle.com/hortonhearsafoo/fast-ai-v3-lesson-1. Really the only “trick” that was required this time around was to set num_workers=0 for the Databunches, as there is an issue with Pytorch(?), seen in other platforms too, that breaks in multi-worker situations.
3 Likes
Great work! Congratulations!
I would like to ask you if the inference was done on mobile or in the cloud?
Thanks!
@chho6822 The inference is done on the cloud
We haven’t looked into running it on mobile.
Thanks. I guess I need to run more experiments 
1 Like
I created another starter pack This time it is for the Kaggle Humpback Whale Identification Competition. I like it way more than the previous one. Also, the competition is a lot of fun - many things could be attempted that can be a good learning experience and that can lead to a better score. The competition just launched and there are still over two months and a half to go!
Here are a couple of images from the training set:

21 Likes
Sorry for not being able to share an awesome project like everyone else.
Instead I want to share an interview: I had interviewed @rachel about her DL Journey and fast.ai, I totally forgot to share it with the community. Here is the link to the interview.
5 Likes
Based on the crap to no crap GAN of lesson 7, I tried the same approach to add colors to a crap black & white image. First I downloaded high quality images from EyeEm using this approach.
Training the Generator with simple MSE loss function, I got not exciting results (the only thing it learned is sky has to be BLUE  ):
):

Then after adding the Discriminator I and training in a ping-pong fashion, the Generator got better:

Now trying on some test images 
15 Likes
I replied on Kaggle, but wanted to reply here as well: Your methodology very closely followed the intuitions I’ve been working off of, and your code gave me a couple of "ah hah!"s from my own experiments so far. You can see my detailed response there.
Thanks for posting the useable map5 code also.
1 Like
@radek. Thank you for sharing the notebook. I am trying to run the notebook. I got the error
PicklingError: Can’t pickle <function crop_pad at 0x000001F3E7E5F1E0>: it’s not the same object as fastai.vision.transform.crop_pad
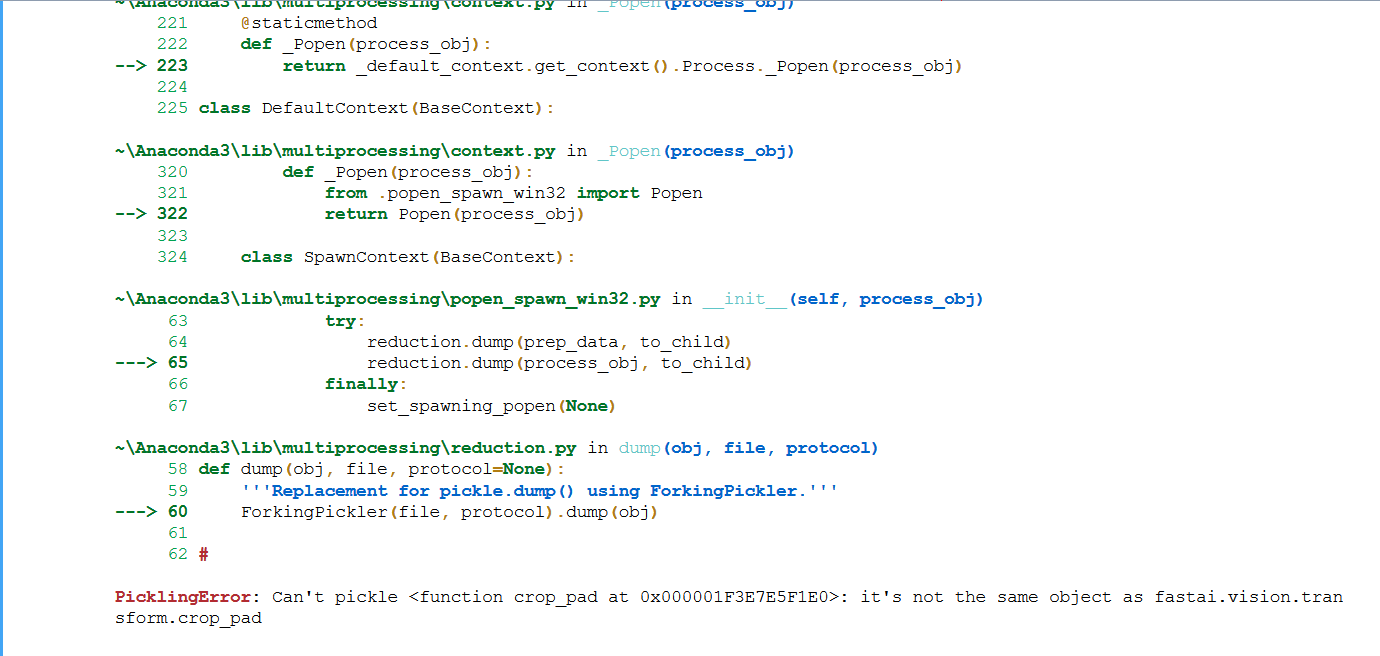
I am using FastAi library 1.0.36.post1 on windows 10.
Please suggest how to fix this error.
Thanks,
Ritika Agarwal
Chances are just restarting the kernel should fix this.
I answered here - for what works for me at least with Windows 10