Worked perfectly- thanks for sharing this!
1 Like
@radek I have restarted the kernel.Then also I am getting this error. I fixed this issue by putting NUM_WORKERS =0 and adding padding_mode=‘zeros’
But Now i am getting the below error while fitting the model. Pls suggest how to fix this error.
RuntimeError: Expected object of type torch.cuda.LongTensor but found type torch.cuda.IntTensor for argument #2 ‘target’
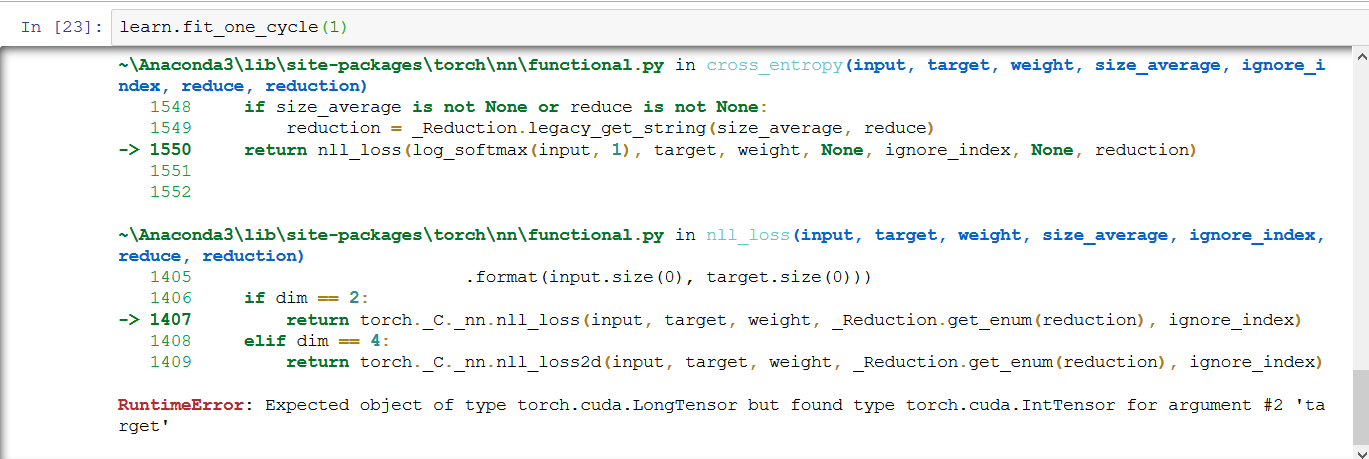
Thanks,
Riitka
Thanks @brismith. I have replicated the steps shared by you. Still I got this error.
I fixed this issue by adding NUM_WORKERS =0 and adding padding_mode=‘zeros’
Thanks,
Ritika
2 Likes
I played around with different loss functions for super resolution to see the impact on the generated images. Interesting to see that impacts quality. I’m also trying to figure out how to deploy a super resolution model on Zeit. If anyone knows how to make the app return an image, let me know.

7 Likes
That means your fastai version is not up to date.
I  a brief post on the Naive Bayes classifier (Introduced in the fastai Machine Learning Course, Lesson #10) on Towards Data Science. Hoping some folks might find it useful.
a brief post on the Naive Bayes classifier (Introduced in the fastai Machine Learning Course, Lesson #10) on Towards Data Science. Hoping some folks might find it useful.
Hi Jeremy,
I am using fastai version 1.0.36.post1 on windows 10. Do i need to update fastai package?
Thanks,
Ritika
One way to do this is export the .ipynb in Jupiter as a .py script.
Then you can browse (and jump to source) or execute the script in vscode.
Jeremy, thanks for the suggestion. I read that post on data leakage - interesting; I hadn’t even heard the term before - and it took a while to figure out what he means by “cross validation folds”! I do see where it would be a problem in the scenarios he focuses on (mostly k-fold cross-validation, if I’m reading it correctly) but I didn’t see much there that seems directly applicable to this case, except of course his solution of holding back a validation ds, which I take as gospel and I think is pretty well baked into fastai.
I’ve read a random sample of the dataset article texts (makes for some fascinating reading!) and don’t see anything that might be a marker showing whether it’s ‘real’ or ‘fake’, but maybe I don’t know what to look for? One obvious ‘marker’ might be the words ‘real’ or ‘fake’ in the text, and that definitely occurs, so to eliminate any chance of that causing leakage, I ran with a ‘clean’ df from which I had removed any records where ‘real’ was in the text and the label was REAL, or ‘fake’ was in the text and the label was FAKE. That took the dataset down to about 4800 records (from 6000). It still produced about 98% accuracy.
I previously had run a few more times with the full dataset, and saw a little variability in losses and accuracy, but generally around 98% accuracy, so it seems like removing the ‘real-REAL’ and ‘fake-FAKE’ records didn’t make much difference.
Interesting situation. Maybe fastai is just that good! Although I admit I’m still a little suspicious… Any other factors I should be looking at?
2 Likes
Interesting. I’ll try this. Though, I’ve now managed to get VS Code working with the Jupyter extension as well. Thanks!
Hi Nalini, can you please provide the steps you followed to get it working, I tried doing so but it was all in vain. Thanks!
I guess it depends how they were labeled. E.g., if there is a field that was what channel it appeared on, and every time it says “Fox News” the labeler marked it “fake”, then a simply rule looking for the string “Fox News” would get 100% accuracy.
1 Like
Wow that’s very nice! ![]() I’m not sure I can see any impact of attention - but the other 3 all seem to help. Is that what you’re seeing too? Do you see any other benefit of attention (e.g. faster training, higher LR)?
I’m not sure I can see any impact of attention - but the other 3 all seem to help. Is that what you’re seeing too? Do you see any other benefit of attention (e.g. faster training, higher LR)?
What have you tried for returning an image? You probably want something like this:
For the final update to our aircraft classifier project, I have added the Data Augmentation progressively resized the dataset. We are now at 99.5% accuracy. Also did a little write up on the heatmaps to better understand the lesson.
The following Medium post describes the details of the process.
The accompanying notebook can be found at this gist.
3 Likes
Nice application. Without seeing your image data, how many of the military planes are derivatives of commercial planes? For example, the commercial DC-4 was used to create the C-54 and C-47. The commercial Airbus A310 has a military derivative in the CC-150. Boeing’s 737 has been made into the P-8, and the 767 into a KC-46.
Anyways, I think I just gave myself a task to try and create an airplane classifier similar to yours over the work break next week.
I must admit that what you are proposing is an interesting approach, since my data only included 5 different types of fighter jets, and did not include military transportation aircraft.
I wanted it first to differentiate between manned and civilian aircraft, which is an easy task since there cannot be much confusion, but the uav’s I took are a little more trickier (except the Neuron), since their essential shape is more similar to the commercial liners.
I don’t see any real visual impact from attention. If you really stare into the dog’s eye, you see more distinctly red or distinctly blue pixels in the attention versions compared to versions without attention. However I don’t see this in other areas of the images, so I’m not sure if it’s a real feature of using attention.
I didn’t rigorously probe training differences with and without attention. Models with/with out attention converged to approximately the same validation loss in approximately the same time.
I noticed setting self_attention to True for a standard Dynamic Unet only adds a single self attention layer to one of the upsampling layers. Maybe there would be a stronger effect from adding self attention to other upsampling layers.
One thing I found interesting about all of this is how no single loss metric produces the best result - you get the highest quality images from combining metrics.
2 Likes
I started writing my takeaways from the course.
2 Likes
Hi Akshay, sorry for the late reply. I actually did a bunch of things that day, not sure which worked.  But one of them was to downgrade my python to 3.6 instead of 3.7 to get the VSCode python and jupyter extensions working. Can you try just this step and see if it works for you? All the best!
But one of them was to downgrade my python to 3.6 instead of 3.7 to get the VSCode python and jupyter extensions working. Can you try just this step and see if it works for you? All the best!
1 Like
Some initial results colorizing black and white images using perceptual loss: https://medium.com/@btahir/colorizing-pakistan-5697f7754b2a

2 Likes