excellent paper - thx
1 Like
Thank you.
Not so fast! The app says I’m 10 years younger.
1 Like
How did you joined android with FastAi any chance for GitHub ?
Cheers 
Thank you for taking the time to write this and share it! It has helped me better understand what goes on under the hood! Really useful!
1 Like
Hey people! I finished my duplicate detector and I wrote a short blogpost explaining my approach, you can find it here. It is included in the fastai library too so you can use it in your own datasets!

31 Likes
Great, thank you)))
1 Like
lol your email is going to get inundated
Really cool stuff! I wonder is it possible to search for semantically similar texts in this way? I mean, we have things like Jaro-Winkler or Levenshtein distance but probably making a comparison in embeddings space could get better results?
2 Likes
@FarisMBaker I quickly went through the paper but couldn’t understand how you were doing authentication! you were saying that the last hidden layer outputs are used as thermal image characterizations to construct the face classification but does not detail how!
Hello, not sure what you mean. We do plan to put the code on GitHub as soon as we clean it up and write out documentation. Is that what you mean?
1 Like
@bachir I am not sue I understood what did you mean, can you highlight the paragraph and send it to me please? Sometimes, the authentication data, means the testing data but one can be more accurate if it is a fresh data. My data was divided into %80 training (X_train, Y_train) and %20 testing (X_test, Y_test). Then I compared the Y_predict with Y_test, the accuracy was more than %99.
The non normalised confusion matrix was as follows:
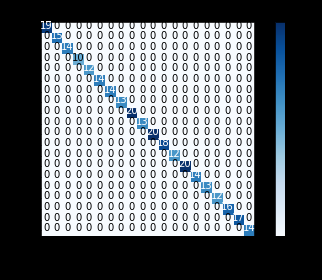
The normalised confusion matrix was as follows:
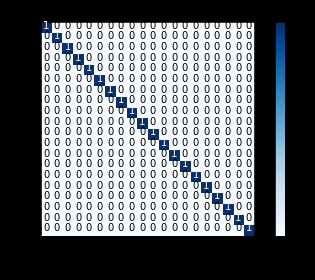
@FarisMBaker thanks for the quick reply. The thing is in the abstract you were talking about biometric authentication, this is why I was looking for how you did implement this (e.g. using a cosine similarity on the last layer).
@bachir Biometric authentication in this case is meant as face recognition/identification.
1 Like
This would be interesting. Specially with the new transformer-based architectures which encode batches of text before returning an output (so all the information in the sentence is in the model at once). However, I think this can be more easily established as the problem statement and let the network solve it directly (see STS-B in GLUE)
I’ve been testing with a Fake news dataset based on the Lesson 3 IMDB nb. I’m using the fake_or_real_news.csv file that was prepared by George McIntire in 2017 - see https://opendatascience.com/how-to-build-a-fake-news-classification-model/. The csv file was on GitHub just two weeks ago but now is gone - I don’t know why. I’ve reached out to George for feedback.
The dataset has about 6,000 items, consisting of the headline and text of a news article and the label, FAKE or REAL.
As with IMDB, I only got about 35% accuracy for the language model. But the classifier got to 99% in one epoch:
learn_c.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
Total time: 11:14
epoch train_loss valid_loss accuracy
1 0.241235 0.061616 0.991318
Just to see what would happen, I went ahead with unfreezing 2, 3 and then all layers, but the highest accuracy was still at 99%, although losses were quite a bit lower:
learn_c.unfreeze()
learn_c.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
Total time: 28:55
epoch train_loss valid_loss accuracy
1 0.120577 0.029395 0.990529
2 0.089659 0.045305 0.984215
I would appreciate some opinions on whether this is too good to be true! I haven’t done enough analysis yet to see if there’s something off here. Seems to be consistently underfitting but I don’t know if that’s a problem.
I tried a few predictions, starting with short samples (a sentence or two) but it turned out it was consistently classifying short samples as Fake. My “aha” moment came when I realized that makes sense - the model needs enough text to classify, from the language patterns alone, something that’s not at all obvious to an algorithm, even though it’s obvious to a human (like “hillary clinton accepted the democratic nomination for president thursday night”). It seems to work well with about 1,000 characters, but I haven’t analyzed that issue either - I’m eager to move on to a multi-class dataset.
I’ll post the nb on GitHub later.
3 Likes
Have you tried unfreezing slower like Jeremy does? Instead of learn_c.unfreeze(), use learn_c.freeze_to(-2) like near the bottom of this notebook: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-imdb.ipynb
Yes, that’s what I did, same as in the IMDB nb - that’s what I meant by unfreezing 2, 3, then all layers.
1 Like
The link to your notebook is broken. I’d like to take a look at it, though. Would you provide a new link?
Anyway, the heatmaps are not so random, actually. Note that the ones for the first layers tend to activate for edges and/or simple contours, as expected.
How did you deploy a fastai/pytorch model on Android?
Thanks.