Paul, I tried to setup VSCode on my local machine (mac) to browse the fastai code, but the ipynb files only load as raw JSONs… how did you work around that? I already installed the Microsoft python extension as well as 2 jupyter extensions inside VS code. Can you guide me please? Thanks.
The source code of the fastai library is in the *.py files.
In VS Code you can add the fastai subfolder to easily search it.
Maybe there are also options to view Jupyter notebooks properly (but I am not aware of them). Maybe somebody knows how to view/run them in VS Code?
Thanks Michael… I was looking at the course repo earlier. You’re right, I’m able to view the fastai library python code just fine. But my goal is to be able to start at the course notebook and go back n forth into the modules and function calls from there.
Also, within VScode, would you know how to build tags so I can jump in and out of functions? Do folks usually clone the pytorch library as well to see all the way through?
Thanks!
I’ve written the following short Medium post diving deeper into the Pytorch library, doing some code review, and looking at the concepts we deepened into during Lesson 5.
By @jeremy 's recommendation, I have focused mainly on the torch.nn.modules.linear class.
Nalini: I’ve installed the extension in the picture and it’s quite usable:
I’m an emacs user by habbit, and typically do my development in emacs; for the notebooks I sometimes use “ein” in emacs, but often I just use any browser that’s available (safari/firefox/chrome). I’ve played with VSCode on the mac and linux, and I like it, but I’m not an expert.
4 Likes
I did some research on this for another multi class problem, and I think that the multi label soft margin loss can be unstable. Using BCEWithLogitsLoss is a good default with pytorch.
Running some experiments on tabular data using fastai on the PUBG kaggle competition(kernels only - didn’t notice this at first but now stuck with it).
Using MLP
Downloaded the data and tried building an nn model directly. But the MAE is not coming below 0.33. Tried different variations adding one more fully connected layer, removing dropout(as im not worried about overfitting initially) and with different learning rates. But nothing seems to help
Notebook using Random forest
But a simple RF with 100 trees(no feature engineering) is giving 0.05 MAE. Can anyone suggest wht needs to be done to get similar results with a MLP model using fasti?
Thanks @shankarj67 -
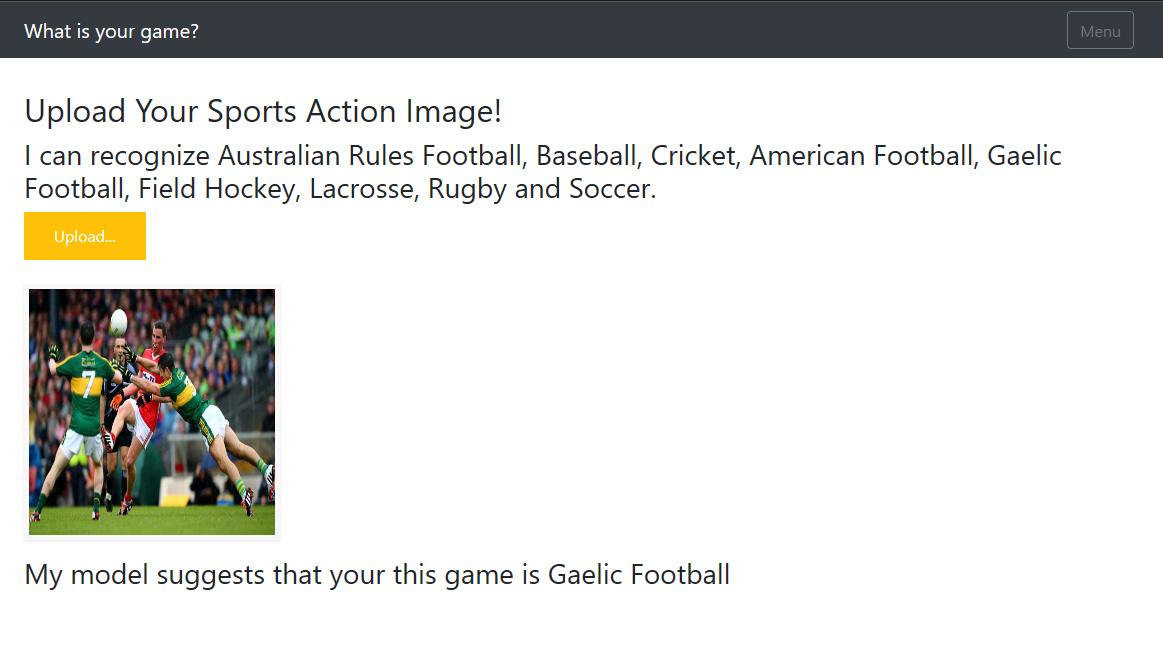
I adapted this for my sports classifier and using an Azure Python Web App for deployment. I did need to cast the return from model_predict as a string as it didn’t like the Category object for some reason
def model_predict(img_path):
img = open_image(img_path)
pred_class,pred_idx,outputs = learn.predict(img)
return str(pred_class)
I needed to use a P1V2 Azure WebApp due to my model size so will not leaving it running for long - but try it out at https://sportsidentifier.azurewebsites.net/
I might try again with a cheaper WebApp now that I have it running. I was particularly pleased with this prediction - maybe the gloves gave it away? It might look like soccer to the casual eye.
Good to hear that my app worked for you 
I have checked a few examples with your app and It’s working great.
If you are looking to deploy your app for free, you can check out my GitHub repo, I have written a detailed guide on how to deploy on Heroku. Let me know if you face any problem.
1 Like
@nbharatula alternatively you case a separate app for visualizing the notebook like https://github.com/jupyter/nbviewer. I’m using https://github.com/tuxu/nbviewer-app
Nice article!
I also decided I would create my own wikipedia dataset (on Finnish) and then found gensim.
My was trial with the WikiCorpus class resulted in text with no punctuation and I guess it had “lemmatized” my dataset by modifying some words somehow since I had the “pattern” library installed. I wasn’t completely sure what was happening inside the WikiCorpus class. And then I found this:
I guess it does pretty achieves mostly same result as your script with just one python command. It automatically uses multiple cores (I’m not sure about your example) so the ~650MB bzip dump was parsed in less than ten minutes on my gcloud instance.
I was thinking to filter only Featured/Good articles as in wiki 103 but I guess that needs a few extra python lines somewhere.
1 Like
thanks @jonppe for pointing out to this alternative. I think WikiCorpus is also supposed to be parallel and use available cores, I was running this on colab, may be this is why it was too slow??
Can you elaborate on how/why would you filter only Featured/Good articles? isn’t supposed the language model to learn from as much text available as possible?
I think the original dataset filters out everything else make sure the language in the dataset is good. But on the other hand, maybe it doesn’t make sense for many languages in wikipedia having much smaller sizes anyway.
1 Like
Thanks Shankar,
I have used Heroku before and tried your steps but I think my model was too big. I also work for Microsoft, so I do have a bit of Azure credit I can use :). Thanks for trying my predictor!
1 Like
That’s the same extension I have. I installed this, the python extension, then installed jupyter as the instructions say. But I still see JSON when I load a jupyter notebook.  Hmm… not sure what I’m missing.
Hmm… not sure what I’m missing.
3 Likes
Food Classifier: Mobile App
Here is a 2-minute video demonstration of our food classifier app on mobile, developed by @npatta01 and I.
We are working on a blog with instructions. We were able to deploy it on Android without any cost.
Right now, it is only available on Android to try out, but not yet published in the store.
- To try out this app, visit https://expo.io/@npatta01/food-app
- Download Expo on your Android phone
- Open Expo app and scan our app barcode, and give it a try!

24 Likes
Custom Training Loop Implementation
Last few weeks I had a rough time trying to fight with memory leakage when training the model on a large dataset. As a side effect, I’ve written a simple training loop using pytorch and torchvision.
This custom loop didn’t help me too much because the leakage was still here. (Probably this issue is already solved in the most recent version of PyTorch). However, it was a quite interesting experience of implementing deep learning model’s training process. Much more simple and less interesting compared to what we have in the fastai library, of course 
Probably it would be interesting for someone who wants to learn more about pytorch and Python. So I’ve created a few little projects.
1) Medium post briefly describing the code.
2) A notebook that entirely contains the code discussed and a bit more information about the solution.
3) Almost the same as in the notebook but as Python scripts.
Essentially, all these links are about the same thing but from different perspectives. I believe there could be some bugs in these implementations. They were written in several days so definitely not a something you would like to use in a production environment It boils down to the following snippet and a bunch of callbacks.
Any advice or remark about written text or implementation is much appreciated. I’ve tried to proof-read the article but the notebook contains some typos I guess. I’ll try to make it better within a few days.
10 Likes
Hello, I’m just want to add a small contribution, is a web app that I prepared to classify peruvian food (10 classes) also includes a guide how to deploy the app on Heroku
1 Like
Dear All,
I have co-authored a paper attached below just published on 10 December 2018 in the Journal of Computer Science with a friend and would like to share it with you and show my gratitude and acknowledgement to Jeremy Howard.
2018 - Thermal Face Authentication with Convolutional Neural Netwrok.pdf (501.1 KB)
Thank you all,
Faris Baker
13 Likes