Well, that’s just pretty awesome.
I am impressed by 1 cycle policy and superconvergence methods do automatic so I write a blog on it and it’s is my first blog can fastai community give me feedbacks about blogs or am I getting the concepts correctly to relate superconvergence and regularization.
I just published SuperConvergence with inbuilt regularization -
https://link.medium.com/gLmCDpt7BR
Thank you for that post, that was very useful - here is what happened:
-
following Rachel’s post, I split my training and test set more rigorously (the key here was to have all the images of the same city either in the train set or the test set, and not in both). For anyone running into the same issue, split your sets yourself, then use
ImageDataBunch.from_csvorImageDataBunch.from_df. -
Unfortunately the result of this was a much lower test accuracy - around 60%; and no fiddling with the training seemed to improve the result. So I went and got more data

-
I downloaded data from the largest 25,000 cities in the world; around 100,000 labeled images in the dataset. Interestingly, resnet34 (which was better on the small dataset) turned out to be much worse than resnet50 on the large dataset. Resnet34 got to about 75% accuracy while resnet50 easily got to 80% Finetuning also helped a lot with this larger dataset, almost 5 points improvement.
Conclusion: with this new model, accuracy is now back to 85% (using rigorously split train and test sets).
The result is extremely pleasing, and the webapp is now almost creepy to try out; it seems to get almost everything right: yourcityfrom.space
11 Likes
I wanted to check how fast.ai initialized weights in CNNs and was surprised to see that it changed from last year!
So I wrote a blog post on “He Initialization” 
Weight initialization for CNNs: A Deep Dive into He Initialization
https://medium.com/@tylernisonoff/weight-initialization-for-cnns-a-deep-dive-into-he-initialization-50b03f37f53d
2 Likes
Nice job! Do you have any interpretation on how it’s classifing?
1 Like
IMO, for local installations it is always better to use docker wherever possible, to avoid messing up your installed packages. You don’t want to end up with incompatible versions. Cheers.
For a project like this I don´t see the need for a docker, I use multiple conda environments and it works just fine 
2 Likes
I think data augmentation will help in this situation.
1 Like
Yes, we have much trouble and I would say pain, getting the model converted to ONNX binary protobuf file which contains both the network structure and parameters of the model we exported. We are able to go from:
fast.ai + PyTorch ![]() ONNX
ONNX ![]() Caffe2
Caffe2 ![]() Android devices.
Android devices.
The SqueezeNet model in plain PyTorch from torchvision runs fine on Android devices. Exporting fast.ai ResNet-family of models (we have tested ResNet18, a smaller model with lesser parameters and reasonable GFLOPS on mobile ARM processor/GPU(DSP)) through the ONNX exporter with Caffe2 backend proceed successfully (no error). However, when we put the 2 pb files on the Android app, it runs and crashed on Android devices. Our initial investigation found the crash could be due to discrepancies all over the ONNX specifications and around the tooling that follows ONNX.
The bottleneck is in this step: “Export the model to run on mobile devices”, where ONNX-Caffe2 backend rewrite ONNX graph to Caffe2 NetDef.
Currently, in our project, we are mostly doing detective work on the ONNX and Caffe2 sides. In this project, we learned and discovered a big revelation on how “production-readiness of PyTorch” after the PyTorch 1.0 release announcement, about 2 months ago. We are trying to demystify that announcement.
Please bear with us. Our response might be delay as we are super busy now:
- to get the iOS part done
- make it easier and more pleasant to ship and test your neural network model in PyTorch on mobile devices
- ironing out all the kinks that slow down the shipping process
19 Likes
Supercovergence refers to a consequence of the one cycle policy: as the policy involves partly training with a high learning rate, a regularisation effect (overfitting prevention) and shorter training time with stable prediction performance are achieved.
More in-depth explanation by @sgugger: https://sgugger.github.io/the-1cycle-policy.html#the-1cycle-policy
and the original paper:
https://arxiv.org/abs/1708.07120
Actually Docker on Windows 10 can run Linux container images as well.
3 Likes
Just made a classifier which can recognize the language from the script.
I have chosen 4 Indian languages. ( Bengali, Gujarati, Hindi and Telugu )
Architecture: ResNet 34
Accuracy: 95 %
The model was trained on electronic scripts. The test images were having newspaper, posters, textbooks etc. i.e. the test images distribution was much larger than training.
Even then the classifier worked with a very good accuracy.
2 Likes
I’ve used a model trained on the KDEF dataset to analyze Jeremy’s facial expressions in the lesson videos: https://gist.github.com/jerbly/695df9598eeb64788cb16075cf8a3d4a

39 Likes
Time series classification: General Transfer Learning with Convolutional Neural Networks
I have performed some time series classification (TSC) experiments applying the standard transfer learning approach we have learned in this course with the idea that it wouldn’t be very useful when applied to time series.
However, the results are great: 93.3% accuracy (very close to the state of the art which is 96.7%).
I think this demonstrates that the fastai transfer learning approach is pretty powerful, and may be applied to lots of different domains, beyond the type of images included in Imagenet.
The goal of the experiment is to identify the country of origin of 30 samples of olive oil based on spectrographs (univariate time series).
The experiment combines 2 approaches that have not been widely used in the TSC domain yet:
- Time series encoding as images. I have tested several approaches, and the one that works better is one where time series are mapped to an image by means of a polar coordinate transformation called the Gramian Angular Field (GAF). This creates a rich graphical representation of a univariate time series. If you are interested you can read this paper (Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks). Based on this the univariate time series on the left is transformed into the image on the right.
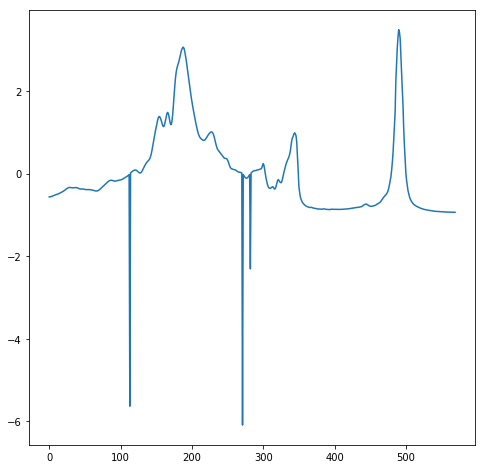
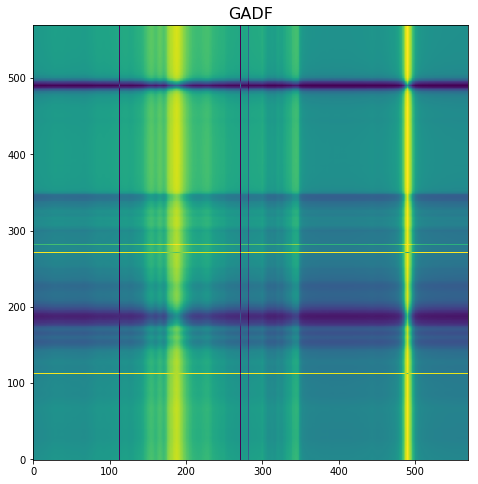
- Transfer learning with resnet 50. This is a difficult test as the model has not been previously trained on time series images.
I have used a small UCR time series dataset (Olive oil, with 30 train and 30 test samples) to confirm really test transfer learning.
No transformations have been used.
If you are interested, I have created a gist.
I now plan to apply this same approach to other difficult time series classification problems to get more insight into this technique. Also to modify the standard approach using some transformations which might be useful.
Feedback on the experiment is very welcome.
Edit: if you are interested in time series applications, I encourage you to participate in the Time series/ sequential data study group thread where you’ll be able to share your experience, ask questions, etc.
73 Likes
State of the Art Bangla Handwritten alphabet+character classifier for 84 claases at 94.6% accuracy
I never thought it would be this easy to beat the state of the art classifier of handwritten bangla characters (the paper had 80 characters, I have 84 characters) sampled from 7-24 aged male and female population from all over Bangladesh. The research paper stated this result:
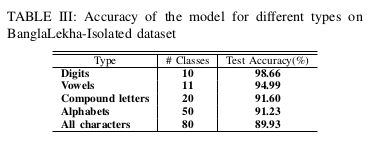
They used a 3 layer vanilla CNN for this, but I am really surprised how proper choice of model : Resnet-50, and optimizer + scheduler : AdamW (??) + 1cycle ; can give a state of the art model in few simple steps — fine-tune, unfreeze, find learning rate, train and predict.
I am just blown away. I though have to disclose that initially it was intimidating on why my model was underfitting; but repeated rewatch of the videos and rereads of the course notes did actually gave back this sweet result! And the best part I made all this in Colab, for free, without shelling a dime.
Here are some top_losses:
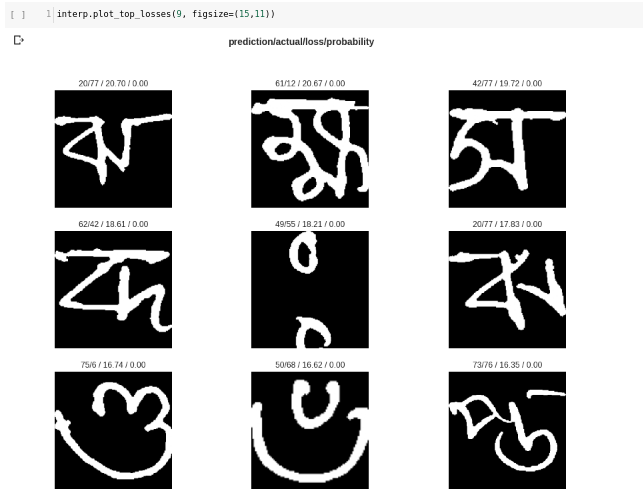
I’ll upload the notebook soon, it’s really really messy (and Jeremy said his notebook cells are not in order,  I wish he saw mine), and I’ll write a blog-post on how I ended up to this result.
I wish he saw mine), and I’ll write a blog-post on how I ended up to this result.
A big shoutout @suvash whose results inspired me to try my own.
4 Likes
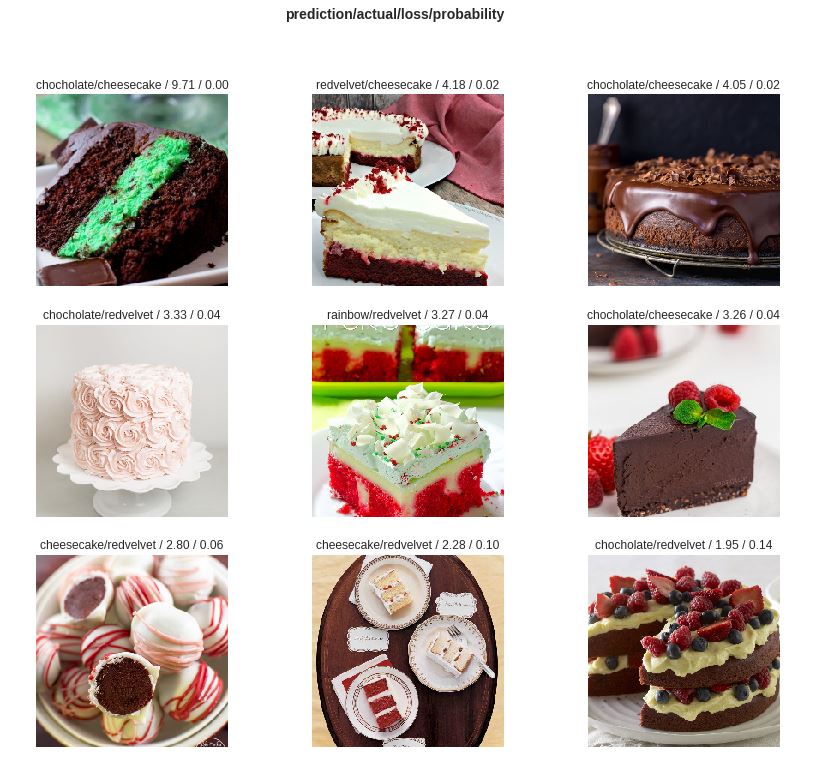
I tried to build a cake classifier with 4 classes: cheesecake’, ‘chocolate’, ‘rainbow’ and ‘redvelvet’ with 1000 images. Here are some top losses after first cleaning up the data.
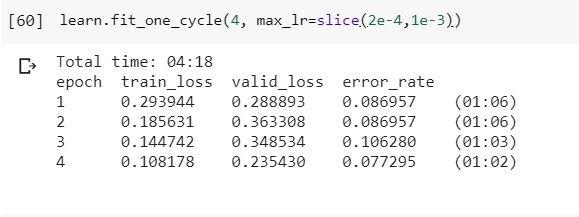
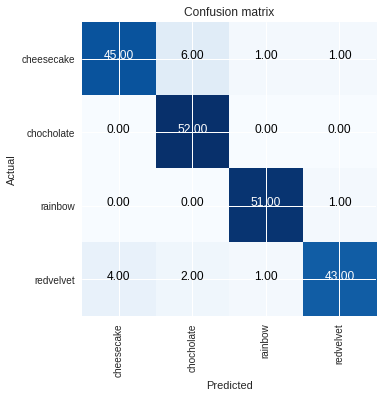
And here are the error rate and confusion matrix. I doubt if the change of error rate that it increased and decreased again is the sign of overfitting ?
6 Likes
Can you share your notebook. I also created the same classifier for languages.
Hi Jerbly,
how you got ground truth labels?
Hi Neeraj,
Just saw your post. It seems we trained same classifier. I used ResNet 34.
I shall be providing github link shortly
Perhaps my titles in the plots are confusing. It’s class / winner / timecode:
class - the class I’m searching for the max probability in the entire video
winner - for that frame the actual class that was maximum
timecode - the time-code for that frame in the video
So in the example below from lesson2 the fourth picture had the highest sad probability but in fact neutral was argmax on that row.

5 Likes