This is my first post, so please let me know if I did anything wrong.
Here’s a quick summary of what I did:
After watching lesson 1, I put together a model to tell apart pictures of Australian Prime Ministers (they change very quickly these days, so it seemed like it could be useful).
My data set included 50-70 images each of the last six PMs. I used resnet34, and the model got to an error rate of 12.5% after 4 epochs. My code is available on github.
It was really cool to be able to do this after just one lesson! (especially since I have limited coding experience - I’m currently a management consultant so most of my technical skills are specific to Powerpoint)
Here’s some detailed information of what I did:
Getting the data:
- To download the images, I used a firefox add-on from a forum post.
- I downloaded ~60-80 pictures of each prime minister from Google, then went through them and manually deleted any that looked problematic (e.g. pictures of the wrong person, pictures with text in them)
Uploading the data into Crestle:
- I had a bit of trouble with this, since it wasn’t obvious to me how to get a large number of files onto my Crestle server, but I was able to find some help in a forum post.
- I ended up installing the unzip module for python, uploading a zip file onto my crestle server, and then writing some code to unzip it
Building, running, and fine-tuning the model:
- I used resnet34 for the model (I also tried resnet50, but was running into memory issues even with a small batch size)
- After four epochs, the model got to a 12.5% error rate
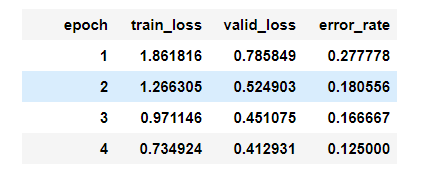
- I was pretty impressed with the error rate! Especially since a lot of the prime ministers look very similar (many of them are men with glasses and short white/grey hair). The combination the model had the most issues with was Kevin Rudd and Scott Morrison
- I also tried some unfreezing, but the results seemed pretty bad (error rate of >80%). I’m guessing that I’ll learn more about how to do this in the coming lessons
