I just finished the first two lectures and wanted to try using convolutional networks on my own datasets. Full writeup on my blog.
In particular I wanted to find out what convolutional neural networks are good at and what they struggle with. I created three datasets of increasing difficulty:
- Impressionist Paintings vs. Modernist paintings (Easy; Very different features in each class)
- Cats vs. Kittens (Medium; Cats and Kittens share many features)
- Counting identical objects (Hard; All objects have identical features)
I found the third experiment proved interesting, so I’ll share a little bit about it here.
Counting Objects
Full notebook on GitHub.
For my last task I wanted to see whether or not we could train a ResNet to “count” identical objects. So far we have seen that these networks excel at distinguishing between different objects, but can these networks also identify multiple occurrences of something?
Counting 1-5 Objects
I started by generating 2,500 images using matplotlib with 1 to 5 objects in each and labelling them accordingly.
path = 'data/counting'
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,8))
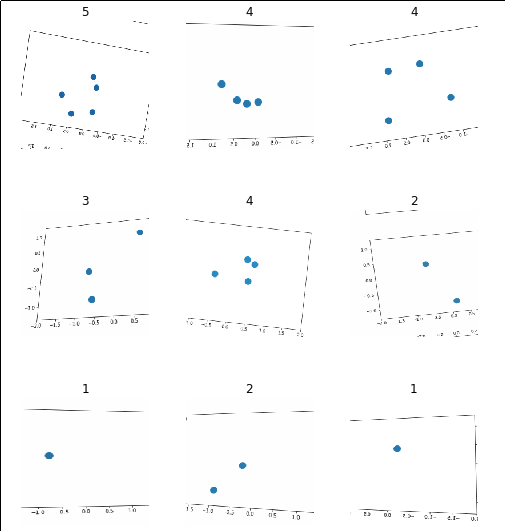
After running a vanilla learner for a few cycles I got an accuracy of 87%! After fine-tuning with a better learning rate I was seeing accuracies of 99%!
What’s going on here? I specifically chose this class to try and trigger a failure case for convolutional networks.
What I would guess is happening here is that there are certain visual patterns that can only occur for a given number of circles (for example, one circle can never create a line) and that our network uses these features to uniquely identify each class. I’m not sure how to prove this but I have an idea of how we might break it. Maybe we can put so many circles on the screen that the unique patterns will become very hard to find. For example, instead of trying 1-5 circles, let’s try counting images that have 45-50 circles.
Counting 45-50 objects
After regenerating a new dataset, we can take a look at it:
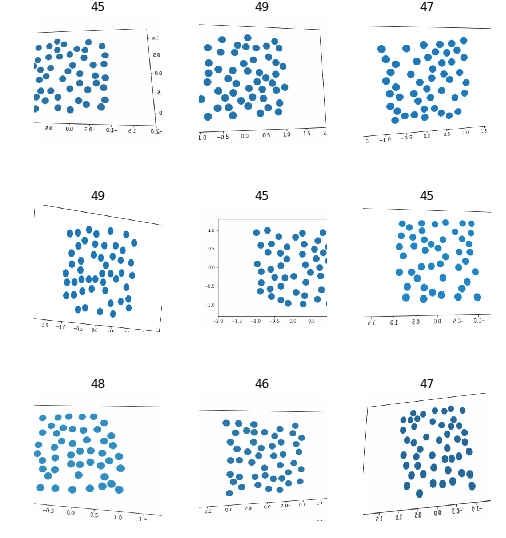
Try finding a visual pattern in this noise! After re-running a learner and trying to fine-tune it I was only able to achieve an accuracy of about 27% which is slightly better than chance.
I should note that although this system cannot accurately distinguish between images that contain 45-50 objects, it might still be successful at counting more generally. When I ran experiments with 1-20 objects, I noticed that its predictions were frequently only off by a little bit (eg. guessing 19 elements when there are really 20). It might be tolerable for some applications to have an “approximate estimate” of the number of objects in a given scene.
Reflections
I found this experiment really interesting and it taught me more about these kind of networks. This task is technically trivial to solve (Just count the blue pixels in each image) but our neural network struggles to make progress when there are no obvious differences between the classes of images.
It was also interesting and surprising to see how it managed to succeed when counting small numbers of objects. Even though these generated images come from a completely different distribution than ImageNet (generated plots vs photos of the natural world) it still managed to use the features it had learned to make sense of plots of a small number of objects.
Edit 1
It turns out that I was a bit hasty here. After receiving suggestions from other fastai forum members I re-ran my experiments with a larger dataset and more sensible image transformations (no zoom, no crop, no warp) and achieved 100% accuracy. The network also succeeded with 100% accuracy when the objects were of different sizes.
The next step will be to re-formulate this problem as a regression problem as opposed to a classification problem. I am interested to see how it does on counts it has never seen before.