Hi, everyone.
I have been playing around with audio classification, using bachir’s strategy of transforming the audio signal into an image represents its spectrogram, and then performing transfer learning on those images using the guidelines from the first three lessons. I tried this with the dataset from the tensorflow speech recognition challenge from Kaggle last year (https://www.kaggle.com/c/tensorflow-speech-recognition-challenge/) and I got an interesting result. The dataset comprises short utterances containing commands such as up, down, stop, go etc. In my first trial, I excluded the categories unknown and silence to facilitate training.

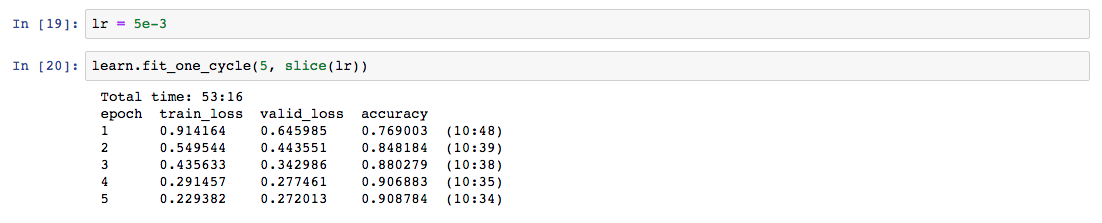

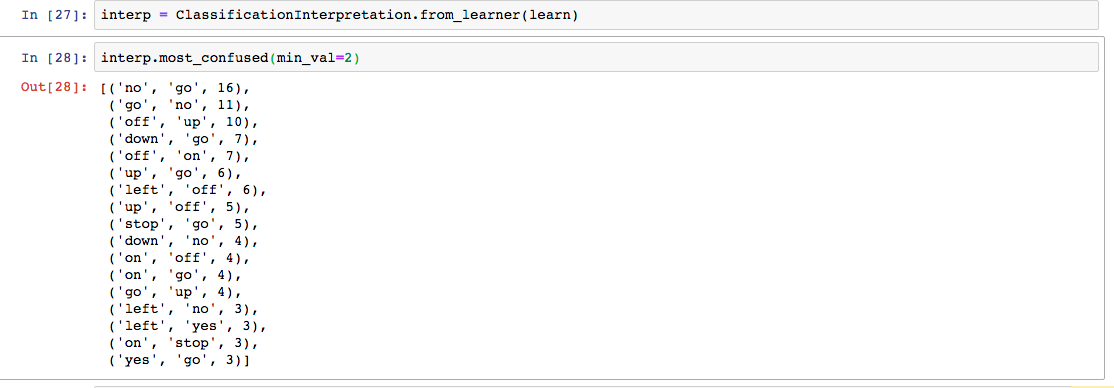
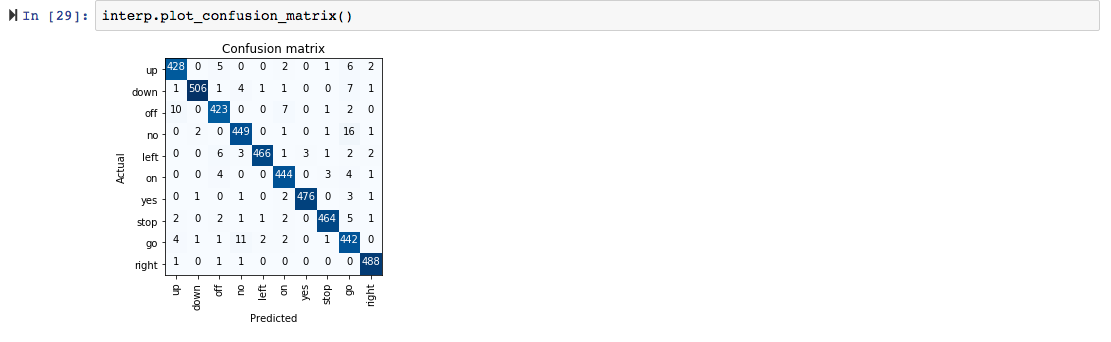
The best result was superior to the first place in the private leaderboard of Kaggle 10 months ago. However, I’d need to include the unknown and silence categories to perform a fair comparison.
I also applied this same approach to emotion recognition from speech using the IEMOCAP database (https://sail.usc.edu/iemocap/). This database contains speech signals uttered by actors and labeled in categories such as sadness, happiness, anger and so on. I started with two classes with a decent amount of data (one thousand samples each) and the first results are encouraging: I got about 93 % accuracy differentiating between anger and sadness. I’m curious to see the performance for the entire dataset.
Cheers