Update:
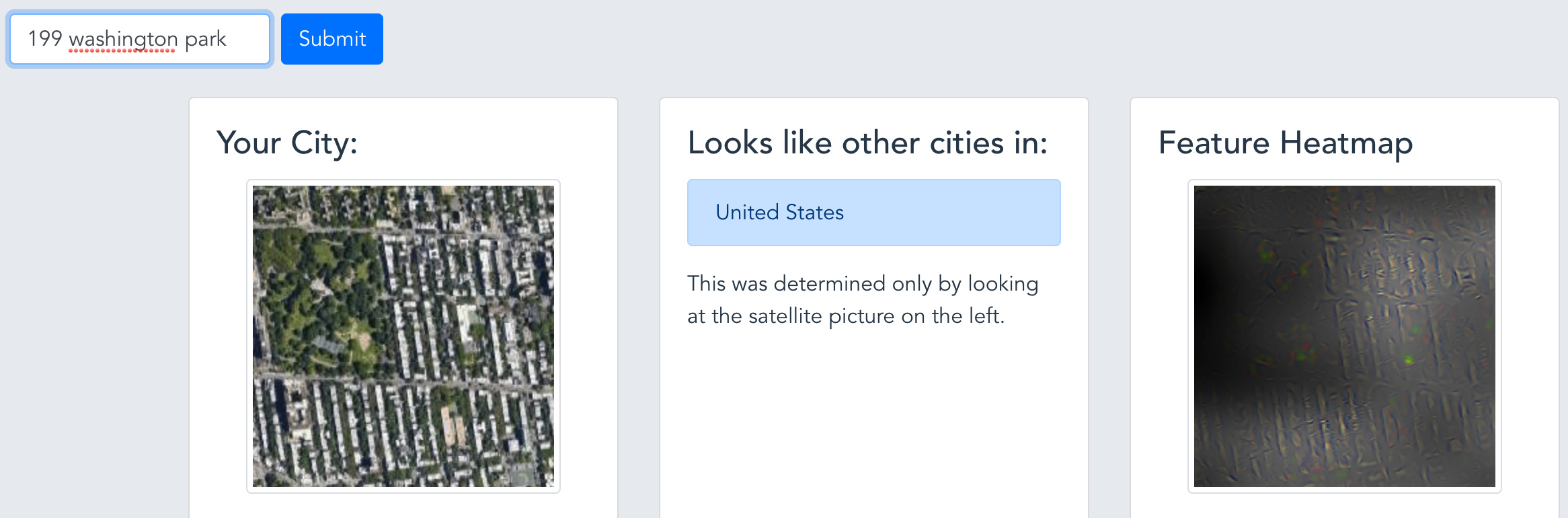
Lots of the feedback I had from the satellite app recognizing the city from the satellite image revolved around the same question: “what is it looking at in the image of my neighborhood that makes it look like it is from my country?”
I tried to implement a couple of interpretation methods I found linked on the forums (see further discussion in this thread).
The results are a little mixed, but I went ahead and added the feature to the app; let me know what you think:
yourcityfrom.space
Example output - you can see here that it avoids the parks and is very interested in the shape of the blocks: