Time series classification: General Transfer Learning with Convolutional Neural Networks
I have performed some time series classification (TSC) experiments applying the standard transfer learning approach we have learned in this course with the idea that it wouldn’t be very useful when applied to time series.
However, the results are great: 93.3% accuracy (very close to the state of the art which is 96.7%).
I think this demonstrates that the fastai transfer learning approach is pretty powerful, and may be applied to lots of different domains, beyond the type of images included in Imagenet.
The goal of the experiment is to identify the country of origin of 30 samples of olive oil based on spectrographs (univariate time series).
The experiment combines 2 approaches that have not been widely used in the TSC domain yet:
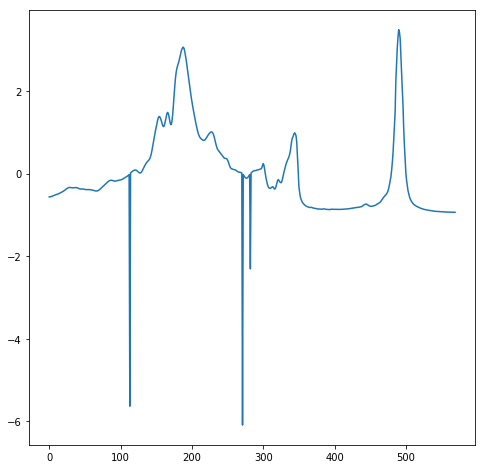
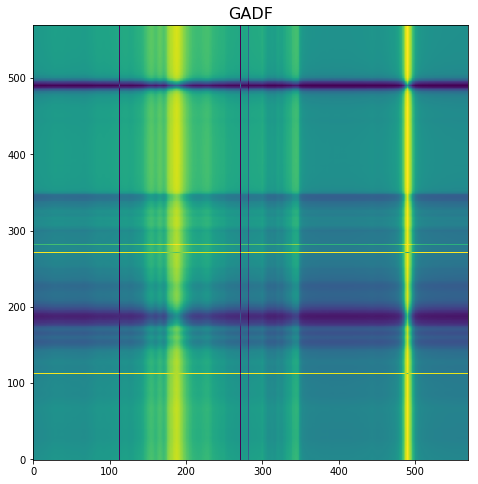
- Time series encoding as images. I have tested several approaches, and the one that works better is one where time series are mapped to an image by means of a polar coordinate transformation called the Gramian Angular Field (GAF). This creates a rich graphical representation of a univariate time series. If you are interested you can read this paper (Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks). Based on this the univariate time series on the left is transformed into the image on the right.
- Transfer learning with resnet 50. This is a difficult test as the model has not been previously trained on time series images.
I have used a small UCR time series dataset (Olive oil, with 30 train and 30 test samples) to confirm really test transfer learning.
No transformations have been used.
If you are interested, I have created a gist.
I now plan to apply this same approach to other difficult time series classification problems to get more insight into this technique. Also to modify the standard approach using some transformations which might be useful.
Feedback on the experiment is very welcome.
Edit: if you are interested in time series applications, I encourage you to participate in the Time series/ sequential data study group thread where you’ll be able to share your experience, ask questions, etc.