When I try to untar the data I get this error - ReadError: not a gzip file.
My code to untar the data is same as yours. Did you encounter that error?
I am very excited about the v3 course and the shared work here! A lot of creative approaches! 
I also played around with the STONEFLY9 Image Database consisting of 3826 images of 9 taxa of Stoneflies for training a ResNet34 and ResNet50.
This is how the data looks like:

I was able to get the accuracy up to 0.99+ and the single misclassified image is one where the insect is only shown incompletely:
ResNet34: 0.995037
ResNet50: 0.998677
These results also beat the older papers as far as I have found comparable values. 
You can find my notebook here: https://github.com/MicPie/fastai_course_v3/blob/master/L1-stonefly.ipynb
Questions, comments, and suggestions are highly appreciated!
I will now look deeper into results with the methods posted by others in this thread (PCA, activations, etc.).
Kind regards
Michael
Edit: Added a post about visualizing the activations including a notebook.
18 Likes
I always have to manually clean up my Whatsapp downloaded images folder because Memes and other images sit in same folder along with camera pics shared by my contatcs.
Hence i trained 34 model with 2000 images without unfreezing, 1000 manually classified images from my own Whatsapp and another 1000 sourced from google search.
I think google photos have similar model built in to remove clutter but it does not detect memes.
I am planning to have bigger dataset and testing set and see how it goes.
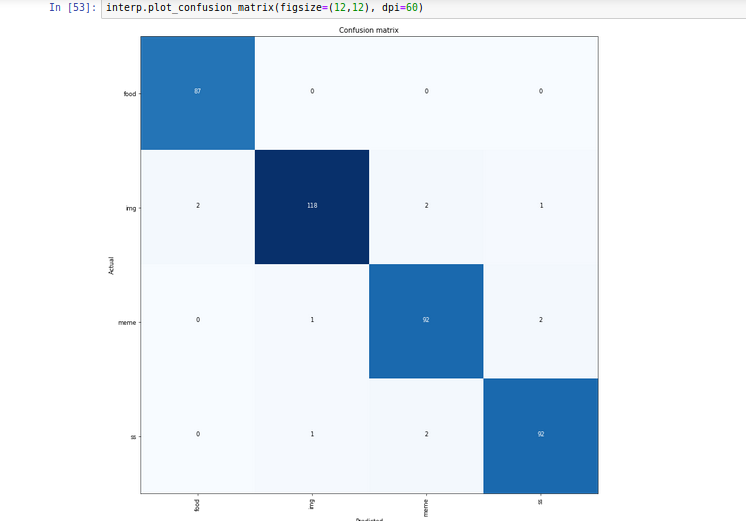
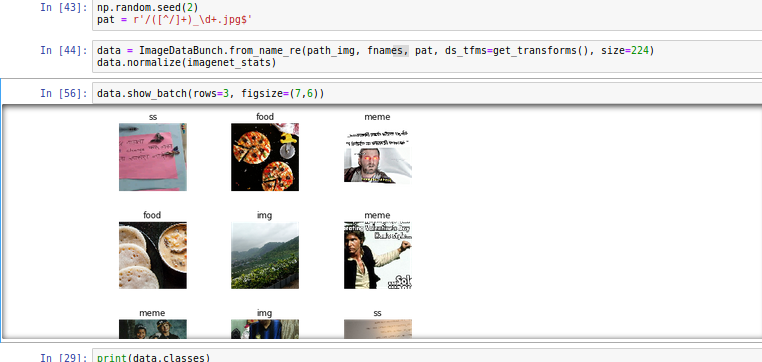
24 Likes
Playing with the Birds dataset from Caltech. It seems going to be challenging, there is 200 bird classes each a dozen pictures. With the simple 4 cycles training of ResNet-34, I got very bad results:
Total time: 12:08
epoch train_loss valid_loss error_rate
1 3.650673 2.174252 0.521866 (03:07)
2 1.836933 1.261172 0.349438 (03:08)
3 1.250030 1.025832 0.284881 (02:55)
4 0.989510 0.987043 0.269888 (02:57)
Here is the top losses:

The confusion matrix is not even readable with all the 200 categories:
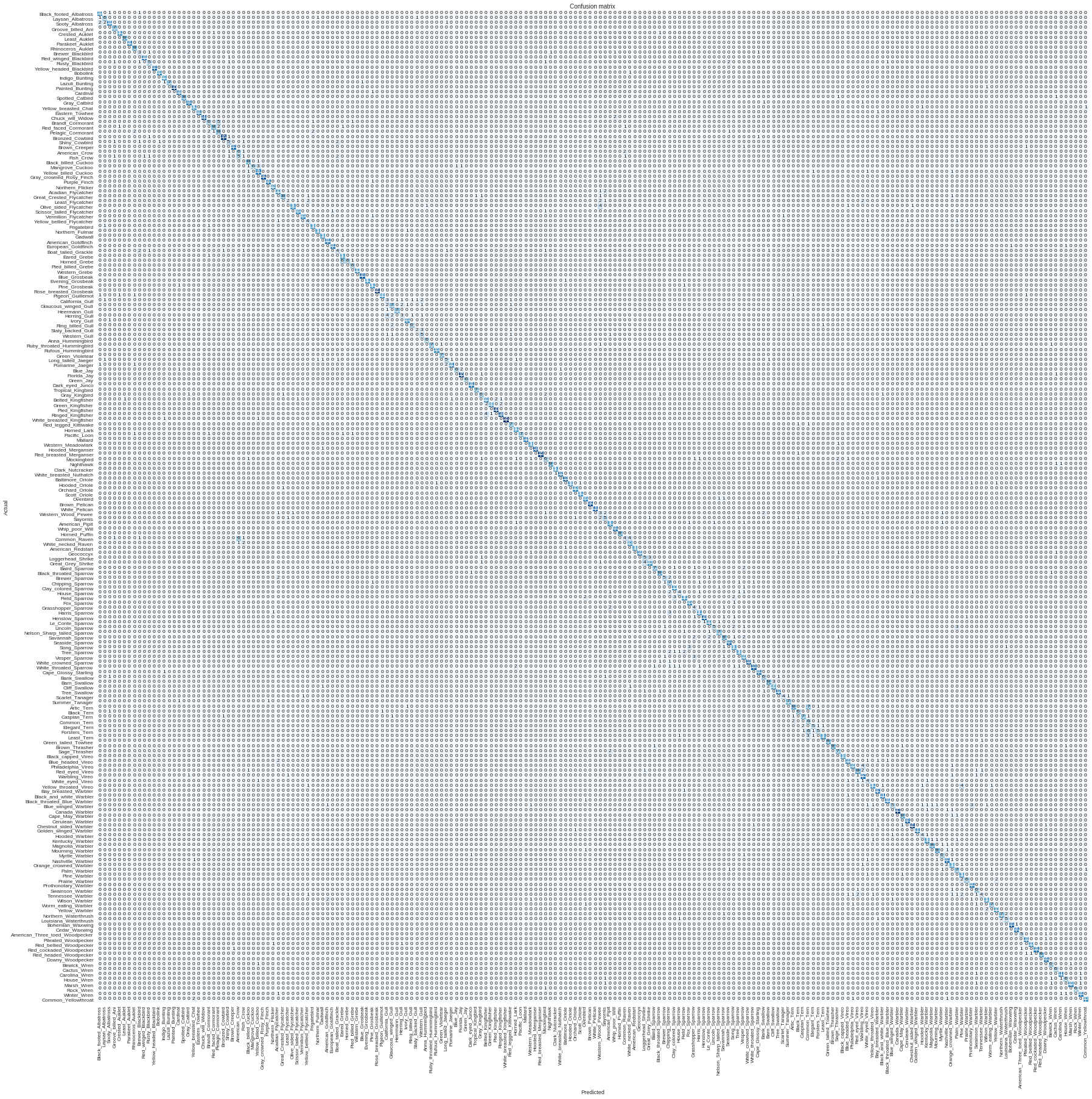
This is going to be challenging but love it, thanks so much @jeremy for this wonderful journey!
10 Likes
Dear @bachir,
be careful with the CUB dataset, as it says on their website:
Warning: Images in this dataset overlap with images in ImageNet. Exercise caution when using networks pretrained with ImageNet (or any network pretrained with images from Flickr) as the test set of CUB may overlap with the training set of the original network.
Potentially you are using images for your valid/test set which were previously in the ImageNet train dataset used for training the weights of the pretrained ResNet.
Nevertheless, I was also playing around with this dataset before and got similar results to the one posted by you.
I guess in this case it would be best(practice) to remove the ImageNet images from the birds dataset or pretrain with other images (and not ImageNet)?
Hey everyone! I played around with Kaggle’s Facial Expression Recognition dataset to create a emotion classifier.
This is what the data looks like:
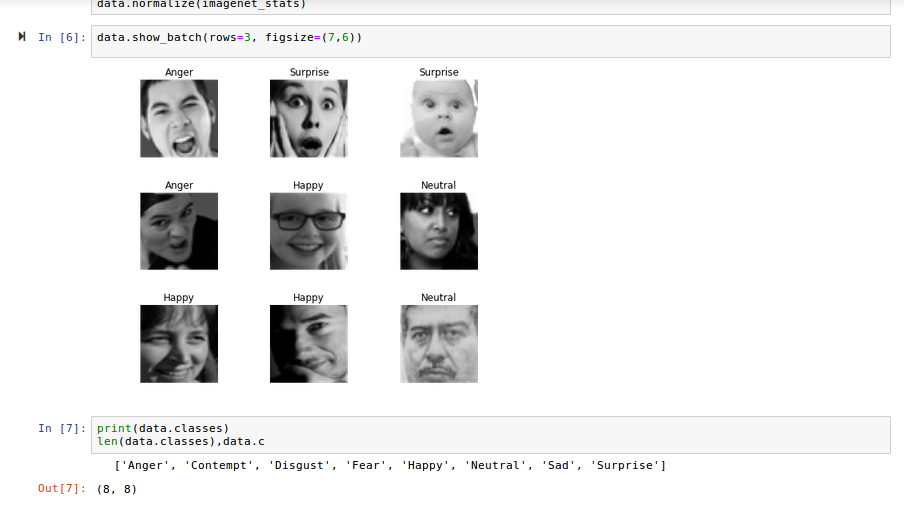
And the top losses:

The classifier gets an accuracy of 84%! Surprising since even I was confused (a lot) while manually inspecting the images.
P.S - Since all the images in this dataset are 48x48 does anyone know what happens when we use size=224 or size=299 while creating ImageDataBunch?
7 Likes
@MicPie I didn’t fully understand the warning when looking at the training cycles results I see big losses. Isn’t this strange? should be almost perfect results if the same pictures were used to train the model.
The thing if we train without ImageNet pretrained NN it will take a long time, but will give it a try.
It just means it will run unnecessarily slowly. Use size=48 instead.
4 Likes
I have been currently working on this Happy whale dataset. I have used resnet34 model for classifying more than 3000+ whale species. The classifier that I build didn’t perform very well with only 10% accuracy. From this dataset I understand that there might be some more to it to increase it’s accuracy like applying certain specific transformation, choosing different etc. Since this is the problem of multi-class predictions I hope this will be taught later in this course on how to build multi-class prediction model in fastai which is so much easier as compared to building this notebook completely from scratch using pytorch. Below is my gist for happy whale dataset classification:
Model predictions from Human Perspective
This what my model predicts separated by actual labels. These predictions seem pretty reasonable to me. Even I would have predicted the same. Not sure what to expect from model in terms of scope of improvement. Funny 
3 Likes
We created an Italian food classifier.
Buon Appetito! A fast.ai spin on Italian food by Francesco Gianferrari Pini https://link.medium.com/NAM4XPwumR
3 Likes
Does this mean if we set size = 224 it will add extra zero padding or do reflection along the edges so as to match ? When the original image size is 48 x 48
1 Like
I’m having a hard time training on the Flower Dataset (it has 102 class)!
I trained a ResNet-34 and I got the following bad performance:
Total time: 21:00
epoch train_loss valid_loss error_rate
1 2.709790 5.458967 0.984719 (02:40)
2 2.661998 5.569498 0.984108 (02:38)
3 2.546748 5.700339 0.983496 (02:37)
4 2.363964 5.859702 0.982274 (02:37)
5 2.127904 6.052469 0.982274 (02:36)
6 1.910503 6.106037 0.983496 (02:37)
7 1.760798 6.104397 0.982274 (02:38)
8 1.696391 6.164757 0.982274 (02:35)
Then same thing with a ResNet-50
Total time: 30:58
epoch train_loss valid_loss error_rate
1 5.143882 4.833019 0.985330 (03:08)
2 4.918839 4.791797 0.980440 (03:06)
3 4.749866 4.747269 0.976773 (03:01)
4 4.577477 4.718012 0.975550 (03:06)
5 4.449985 4.724235 0.971883 (03:04)
6 4.291201 4.759896 0.979218 (03:06)
7 4.113739 4.790433 0.975550 (03:08)
8 3.995913 4.814462 0.972494 (03:01)
9 3.880915 4.824159 0.976773 (03:05)
10 3.836075 4.842245 0.981051 (03:09)
Looking at the confusion matrix I see an interesting pattern, it basically classifies everything to the first 8 classes (look at the wide dark blues squares)

Any ideas how I could improve the performance of the classifier?
Here is the jupyter notebook - link.
1 Like
(Cross posting here from kaggle discussions)
I’m trying the former and will share if I find out anything interesting although most likely I won’t.
I used your starter code, bumped up the data to 5% then decided to go ahead and train it on the complete dataset.
Fair warning: If anyone else wants to try this approach: it did take me about 2days to extract the images and will take a lot more to train the complete data. But I did make the mistake of joining a competition that’s running (Against @radek’s advice to join a fresh comp) so my money is on this idea.
2 Likes
Have you tried increasing the number of epochs? Your validation loss is still going down so it may be that you need more training time.
That’s interesting. I did the following and ended up with the same pattern:
read further
I created my own chicken dataset using google_images_download
I trained the dataset without unfreezing; looking quite promising - only the difference between male and female for each chicken type is difficult (also due to a lot of noise in the dataset I think).
Then I unfreezed and trained all layers (with ‘learn.fit_one_cycle(2, max_lr=slice(1e-3,1e-1))’)
And ended up with the following pattern (as if one chicken type is quite generic):
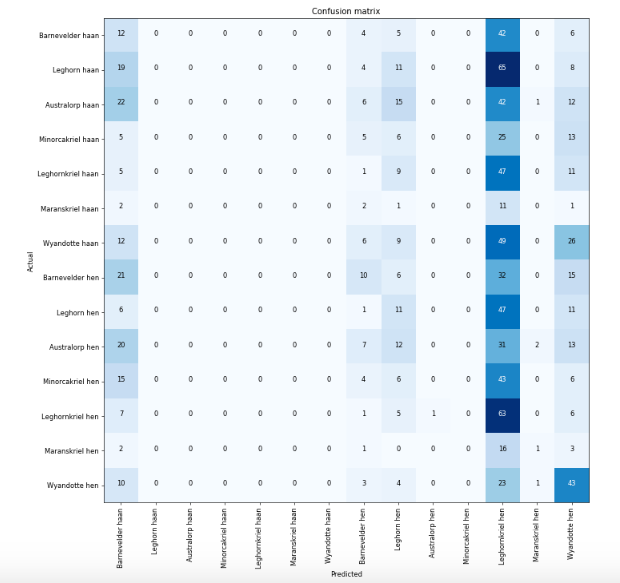
WIth ‘max_lr=slice(1e-6,1e-3))’ instead, it does improve. So 1e-3 seems too high in this case. So can we state that too high learning rate will create a too generalised model? And your learning rate is probably too high?
The learning rate plotted looks like:
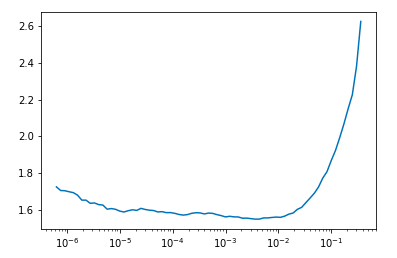
Hey @bachir - not sure about this but I’m looking through your notebook, and it seems to me like your “labels” list and your “fnames” list aren’t in the same order.
Saying that because the first 250 labels are ‘77’ while the first flower images from your fname list are definitely not the same flower. You might be training with random labels.
’
1 Like
Hey everyone. I made an image classifier model that could tell the difference between 2 types of buses used in Panama city. The classic type also called Diablo Rojo that is being phased out. And the modern ones called Metrobus. The accuracy of the model on a validation set was 98.2%. As you can see it’s pretty easy to tell the difference.

Using an algorithm to download the images was a real pain. It took longer than anything else. I’m glad that’s over with. Here is the model.
6 Likes
Hi @Mauro
Nice busses ;-). To help with the cumbersome image download I wrote a small package…
You just specify your search terms and it’ll pull the images from multiple search engines…
Details are here if you are interested:
https://forums.fast.ai/t/small-tool-to-build-image-dataset-fastclass/28281/2
6 Likes
Hi,
I trained a model with street pictures from SF, NYC, Tokyo, and Paris. The error rate is pretty high (32%) but looking at what it gets correct and wrong is pretty interesting – it thinks SF’s Chinatown is Tokyo and it seems to associate Paris with beige.
Top loss:

Top correct:

Notebook here.
Any suggestions to improve welcome!!
5 Likes