oh my gosh! This is beautiful =)
Thank you very much @radek for sharing your kernel: very helpful. It’s great to see fastai-v2-dev in action!
1 Like
I implemented this paper which introduces a regularization term for RNNs. It proposes that the term introduced keeps the norms of the hidden state stable.
You can find a notebook with the experiments here
EDIT: here is a colab link so that anyone can directly run the experiments as well.
Any feedback is welcome! 
1 Like
ROCKET: a new SOTA in Time Series Classification, now with multivariate and GPU support
Last week, there was a major milestone in the area of Time Series Classification.
A new method, called ROCKET (RandOm Convolutional KErnel Transform) developed by Dempster et al. was released (ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels, paper) together with the code they used.
This new method not only beat the previous recognized state of the art (HIVE-COTE) on a TSC benchmark, but it does it in record time, many orders of magnitude faster than any other method.
I’ve been using it for a couple of days and the results are IMPRESSIVE!!
The release code however has 2 limitations:
- it can only handle univariate time series
- it doesn’t support GPU
I have developed ROCKET in Pytorch and you can now use it with univariate of multivariate time series, and with a GPU. I have shared a notebook that explains how you can use this new method.
If you are interested in this, you can find a more information here, in the time series/ sequential data study group thread.
17 Likes
Hi guys! I’ve finally deployed my superres model in a form of a telegram bot.
You can check it here: @PimpMyResBot or https://t.me/PimpMyResBot
You can either upscale the picture and run it through the model or run it without upscaling (sharpen) - it sometimes works for blurry images you’ve found on the internetz, that someone has tried to upscale before.
It’s based on https://github.com/jantic/DeOldify and the superres lessons from fastai, of course.
I’ve managed to deploy the model onto algorithmia, which is a serverless hosting, so I won’t run out of money unless someone starts to use the bot =) As for the bot, I’ve used my vps on digitalocean.
I can drop a quick tutorial on how to do that, if someone’s interested.
I’ve run into some RAM problems, as the fastai unet with self-attention takes 11gb ram for a 1500x1500 output image, so the input has to be somewhere around 700x700. I’ve managed to cap it so that the server won’t die every time, but the results for upscaling, say, 1200x1200 to 1500x1500 with an x2 model are overly sharpened and messy.
I’d appreciate any help on quantizing unet, or converting it to TF (I’ve heard it has better production deployment options/model optimization for production)
Any feedback is more than welcome!
3 Likes
Hi oguiza
Excellent work!
mrfabulous1 
In part 2 @jeremy covers implementing All you need is a Good init over here
In his lectures (as a part of Part II rules) he’s building the fastai library from scratch.
Here (colab) I have tried to implement a HookCallback which implements the paper.
So in part 1 in the first lesson, Jeremy implements a pet classifier that is available over here. I have experimented with that dataset.
All feedback is welcome!
Thank you for the wonderful course Jeremy. It’s really amazing how fastai really fasttracks everything. Makes everything so straighforward.
1 Like
Just sharing a dirty hack in notebook2script.py (@jeremy you are just a genius) to manually enter names of output py.
#!/usr/bin/env python
import json,fire,re
from pathlib import Path
def is_export(cell):
if cell['cell_type'] != 'code': return False
src = cell['source']
if len(src) == 0 or len(src[0]) < 7: return False
#import pdb; pdb.set_trace()
return re.match(r'^\s*#\s*export\s*$', src[0], re.IGNORECASE) is not None
def getSortedFiles(allFiles, upTo=None):
'''Returns all the notebok files sorted by name.
allFiles = True : returns all files
= '*_*.ipynb' : returns this pattern
upTo = None : no upper limit
= filter : returns all files up to 'filter' included
The sorting optioj is important to ensure that the notebok are executed in correct order.
'''
import glob
ret = []
if (allFiles==True): ret = glob.glob('*.ipynb') # Checks both that is bool type and that is True
if (isinstance(allFiles,str)): ret = glob.glob(allFiles)
if 0==len(ret):
print('WARNING: No files found')
return ret
if upTo is not None: ret = [f for f in ret if str(f)<=str(upTo)]
return sorted(ret)
def notebook2script(fname=None, allFiles=None, upTo=None, fnameout=None):
'''Finds cells starting with `#export` and puts them into a new module
+ allFiles: convert all files in the folder
+ upTo: convert files up to specified one included
ES:
notebook2script --allFiles=True # Parse all files
notebook2script --allFiles=nb* # Parse all files starting with nb*
notebook2script --upTo=10 # Parse all files with (name<='10')
notebook2script --allFiles=*_*.ipynb --upTo=10 # Parse all files with an '_' and (name<='10')
notebook2script --fnameout='test_25.py'
'''
# initial checks
if (allFiles is None) and (upTo is not None): allFiles=True # Enable allFiles if upTo is present
if (fname is None) and (not allFiles): print('Should provide a file name')
if not allFiles: notebook2scriptSingle(fname, fnameout)
else:
print('Begin...')
[notebook2scriptSingle(f, fnameout) for f in getSortedFiles(allFiles,upTo)]
print('...End')
def notebook2scriptSingle(fname, *fname_out):
"Finds cells starting with `#export` and puts them into a new module"
fname = Path(fname)
if (fname_out[0]==None):
fname_out = f'nb_{fname.stem.split("_")[0]}.py'
else: fname_out = fname_out[0]
#print(f"fname_out {fname_out}")
main_dic = json.load(open(fname,'r',encoding="utf-8"))
code_cells = [c for c in main_dic['cells'] if is_export(c)]
module = f'''
#################################################
### THIS FILE WAS AUTOGENERATED! DO NOT EDIT! ###
#################################################
# file to edit: {fname.name}
'''
for cell in code_cells: module += ''.join(cell['source'][1:]) + '\n\n'
# remove trailing spaces
module = re.sub(r' +$', '', module, flags=re.MULTILINE)
if not (fname.parent/'exp').exists(): (fname.parent/'exp').mkdir()
output_path = fname.parent/'exp'/fname_out
#print(f"output_path {output_path}")
open(output_path,'w').write(module[:-2])
print(f"Converted {fname} to {output_path}")
if __name__ == '__main__': fire.Fire(notebook2script)
Usage
!python notebook2script.py --fnameout="df_12_ZGFM_25625_1year.py" "12 - ZGFM 25625 - load data from ACCDB - save to DF.ipynb"
Converted 12 - ZGFM 25625 - load data from ACCDB - save to DF.ipynb to exp\df_12_ZGFM_25625_1year.py
I have seen that notebook2script.py doesn’t work great when extended characters are used (such as accents éàè) complaining about UTF-8. Has anyone fixed it?
Hello everyone,
Hope y’all are enjoying the course as much as I am. I am currently on lesson10 and I’ve written 3 articles so far. Just wanted to share them here. Happy learning.
Speeding up matrix multiplication
Initializing neural networks
The PyTorch training loop
5 Likes
Hey Guys! just started the course a few weeks ago.
This is my first deep learning model.
To recognize adidas, nike , puma sneakers inspired from lesson one.
deployed here:
https://sneakernet-v1.onrender.com/
1 Like
I wrote 2 articles on Python and one on Jupyter notebooks. All of them are based on things I have learnt from this course. Hope y’all find them useful.
-
How to be fancy with Python
https://towardsdatascience.com/how-to-be-fancy-with-python-8e4c53f47789?source=---------6------------------ -
How to be fancy with OOP in Python
https://towardsdatascience.com/how-to-be-fancy-with-python-part-2-70fab0a3e492 -
Some neat Jupyter tricks
https://medium.com/swlh/some-neat-jupyter-tricks-be0775c3f17
1 Like
Hi
I just published my work on New York City Taxi Fare Prediction (Kaggle competition).
I used pure PyTroch for building a Tabular Model.
Take a look and pm for questions!
1 Like
I was on and off but got excited when the MULTIFiT model was announced. I trained an Arabic MULTIFiT model based on Arabic Wikipedia and a bunch of books (to get words to 100m). Then, I fine-tuned hotel reviews sentiment classification. After some struggle (MultiFiT Inference and SentencePiece Hardcoded tmp path), I published the app: Arabic Sentiment Analyzer
1 Like
Sadly I don’t remember these experiments very well, but they were a bust. The spike happens because of the inherent shift in the the weights during backprop. The “expected” std changes at each batch, and therefore using the expected std, will eventually just cause your network to blow up. Changing it so that it is calculated at every batch just causes it to be “batch norm”-light.
Dividing by a fixed std,over time the fixed std will either be very much too large or very much too small, causing your weights to either explode(std<1) or disappear(std>1).
Was a great learning experience though. I think everyone should do things like this, because the experience of being excited about your work allows you to be super excited, and it is either going to work, or your going to find out where your understanding of deep learning is the weakest.
Since then I have worked on other projects, but never felt like sharing them, as they didn’t have results. I am currently working on a project that I am fairly happy about and will be sharing soon, after I fix one of my last headaches. I already have results from it that I want to share, I’m just in the “cleaning up” phase.
Hello, I just wanted to share a project I started a while back as part of a hiring pipeline: WindFarmSpotter.

For this project, I collected geospatial data related to U.S. land-based Wind Farms and regional wind speed classes in order to engineer an image data set for training a multi-label model using the EfficientNet b1 architecture.
The model infers Wind Farm capacity for existing wind farms and potential capacity for unoccupied plots of land.
Didn’t get the job but I learned a lot! It’s far from perfect, but was able to run small tests (e.g., EfficientNet v InceptionV3, Python vs Swift-Python hybrid on speed and memory performance), develop a grid search helper for selecting an optimal weight decay hp, and deployed the model to inference engines for both web and NVIDIA Jetson edge devices (a flask API and also a Kitura API).
When I have more time, I’m hoping to train a GAN to draw potential WFs and deploy the model to an additional endpoint in the API.
Here’s an intro post: https://medium.com/experimenting-with-deep-learning/spotting-potential-classifying-prime-areas-for-renewable-wind-energy-farms-with-computer-vision-3085018c821c
and the repo that includes notebooks in python and swift (API deployments can be found on different branches but have not been updated with the multilabel models yet): https://github.com/codeamt/WindFarmSpotter``
6 Likes
Hi all,
I wanted to share my web app Plants Parts Detector at http://detect.plantbook.io
I’m going to continue working in plant pictures detection and use knowledge and skills acquired at fast.ai in my project Plantbook.io
Huge thanks for such an amazing AI course and FastAI library.
Source code of the app: https://github.com/slaxor505/plants-parts-detector
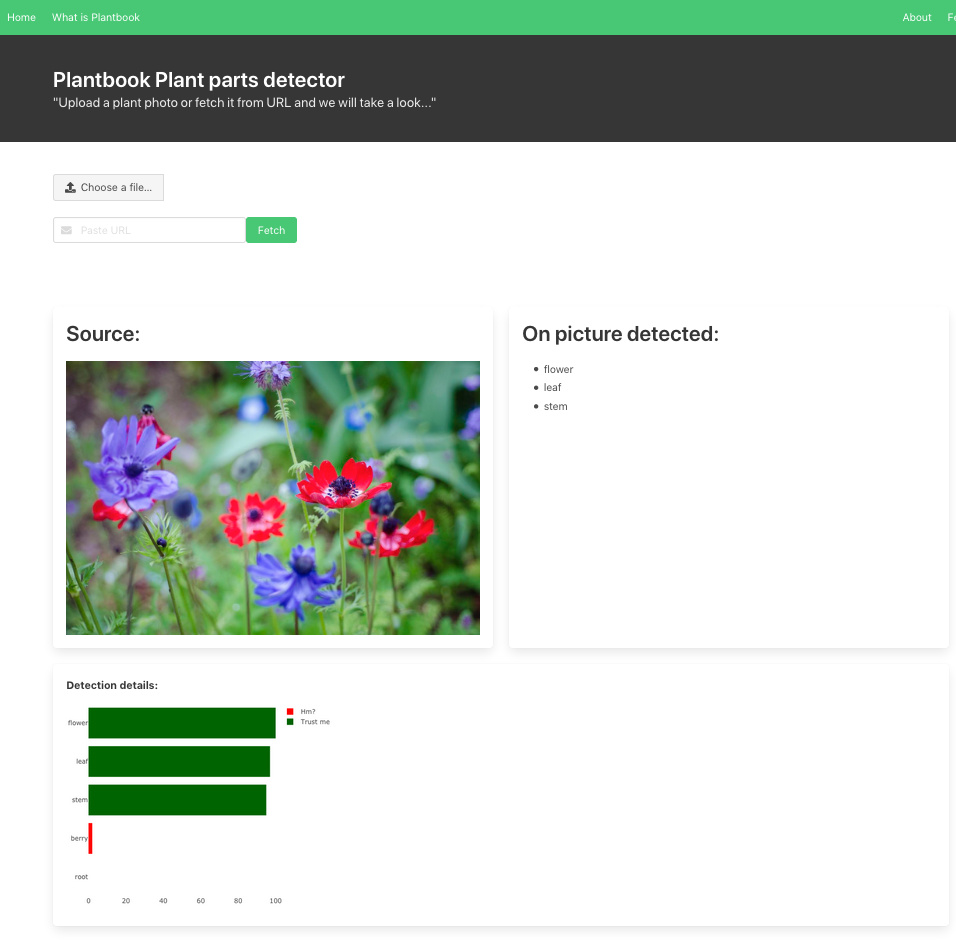
I used Guitar Detector https://guitars.cwerner.ai/ as a foundation from my app. https://github.com/cwerner/guitars-app
I used Bing Image API to get pictures as recommended in this post Tips for building large image datasets and then manually labeled images using Mac’s Finder with some tricks to quickly assign tags and then extracted these tags into CSV file suitable for fastai library.
3 Likes
Hi slaxor hope your having a beautiful day!
I visited your site it looks like an interesting project.
I noticed 2 possible grammar issues.
Plantbook - Where technology serve nature
Making plants growing hassle and stress free
Below are possible options.
Where technology serves nature
or
Where technologies serve nature
and
Making plant growing hassle and stress free
or
Making plants grow hassle and stress free
Hope this helps mrfabulous1
Thanks a lot!
I really appreciate that you found time to check this out and especially your recommendations.
Cheers,
Slava
1 Like
I wrote a blog post on “Label Smoothing”. This post digs into why Label Smoothing helps the model despite not maximising the likelihood of ground truth labels
Blog link - https://abhimanyu08.github.io/blog/deep-learning/2020/05/17/final.html
1 Like