Hi all,
I wanted to share my web app Plants Parts Detector at http://detect.plantbook.io
I’m going to continue working in plant pictures detection and use knowledge and skills acquired at fast.ai in my project Plantbook.io
Huge thanks for such an amazing AI course and FastAI library.
Source code of the app: https://github.com/slaxor505/plants-parts-detector
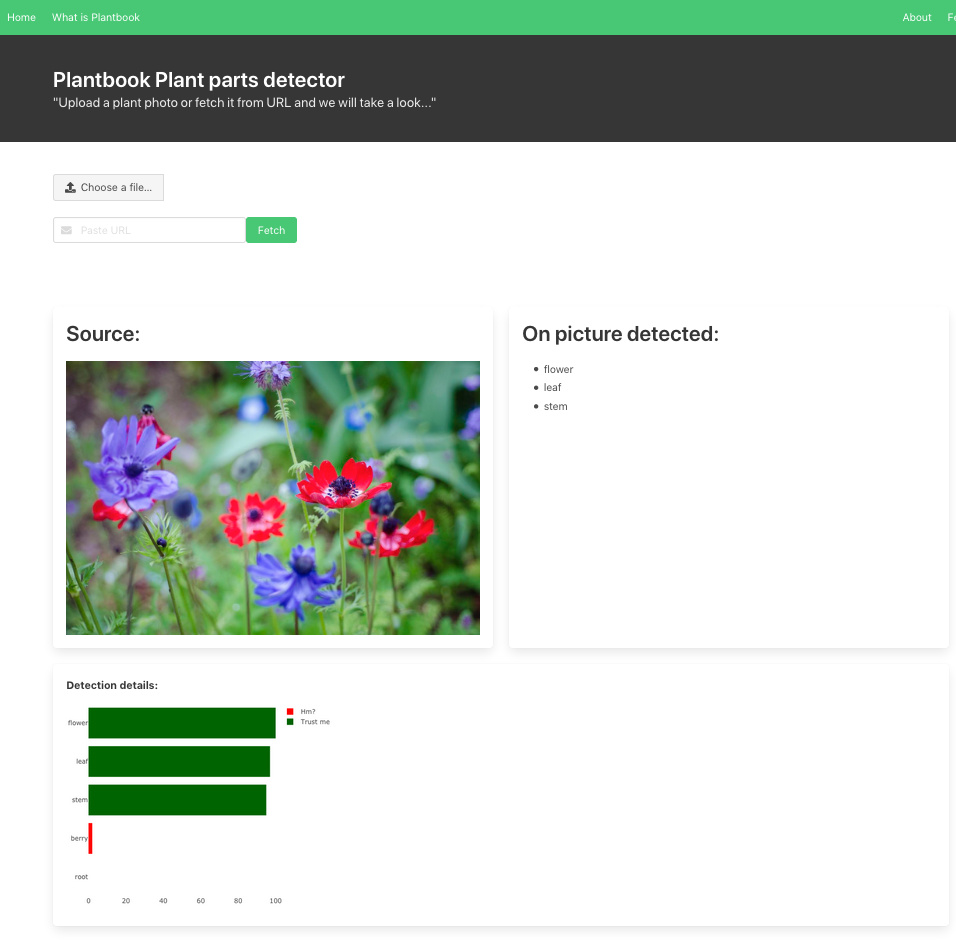
I used Guitar Detector https://guitars.cwerner.ai/ as a foundation from my app. https://github.com/cwerner/guitars-app
I used Bing Image API to get pictures as recommended in this post Tips for building large image datasets and then manually labeled images using Mac’s Finder with some tricks to quickly assign tags and then extracted these tags into CSV file suitable for fastai library.