( As one in Part 1 ) Sharing what we’ve created with what we learned in fast.ai!  It could be a blog post, a jupyter notebook, a picture, a github repo, a web app, or anything else.
It could be a blog post, a jupyter notebook, a picture, a github repo, a web app, or anything else.
4 Likes
Sharing a script similar to notebook2script.py which can clear the codes in jupyter-notebook (leaving all other stuffs unchanged). You can give it a try & share your thoughts.
clear_nbcode.py
#!/usr/bin/env python
import json,fire,re
from pathlib import Path
def is_codecell(cell:dict) -> bool:
'''
check whether a cell contains codes
'''
if cell['cell_type'] == 'code': return True
return False
def clear_nbcode(fname: str):
'''
clearing only the codes in code_cells (inplace) without changing any other parts
in the jupyter-notebook, sothat it's easier both to follow up fastai-nbs,
and to write everything from scratch as Jeremy advises.
'''
fname = Path(fname)
with open(fname,'r') as nb_json:
main_dic = json.load(nb_json)
code_cells = [c for c in main_dic['cells'] if is_codecell(c)]
# clearing the source in code cells
for cell in code_cells:
cell['source'] = ''
# import pdb; pdb.set_trace()
with open(fname,'w') as nb_json:
json.dump(main_dic, nb_json)
print(f'Cleared all the code_cells in "{fname}" (leaving other cells unchanged)')
if __name__ == '__main__': fire.Fire(clear_nbcode)
usuage:
from clear_nbcode import *
clear_nbcode('path_to_nb.ipynb')A blog post (with code and link to a working Collab notebook) on fine-tuning OpenAI’s GPT-2 on my Facebook Messenger data, although it doesn’t use the fastai library.
9 Likes
I wrote a blog entry on weight init:
I summarize:
- The empirical derivation we covered in the weight init notebook
- Xavier & Kaiming papers
- Why us, yes us, can be researchers, too.
Thanks for checking it out!
-James
12 Likes
I would like to share a post which it is not really related to the course material but I believe it still could be helpful because as I know many of course listeners would like to find jobs in Machine Learning and/or Data Science fields.
I had a bit unusual testing task setting during one of my interviews for a Machine Learning Engineer position. It was a part of the interviewing process and intended to reveal a candidate’s coding skills. The major trick here that the task is super simple, a console-based tic-tac-toe game, but also pretty limited in terms of allocated time (1 hour to finish). And, I’ve failed to complete this exercise!
I have very mixed feelings about such types of “stress-testing” that are not too relevant to the real Machine Learning development process. However, it was an interesting experience in how companies organize their screening process. So probably one should be ready for this when applying for jobs 
6 Likes
Yet another post on weight initialization: https://madaan.github.io/init/
It’s written to serve as an extension to the weight init notebook (completes the proofs, fills in the hand-wavings etc.)
Thanks!
2 Likes
Thanks for creating this thread. Some folks have already posted interesting stuff in other threads - if that’s you, please re-post it here so it’s all in one place!
4 Likes
Indeed, didn’t see this thread!
I wrote several blog posts that might interest folks here:
- Finally understanding decorators in Python
- How to initialize deep neural networks? Xavier and Kaiming initialization
- Understanding callbacks in fastai
I plan on writing at least one more each week of the course, I will add them on this post.
10 Likes
Probably going to write a blog post on this, but I have been playing with writing custom activation functions. My normReLU is RELU divided by the expected standard deviation to get xavier initalization training on a 8 linear layer deep neural net. Not particularly interesting, but regular xavier just seems to go to std 0. Issue seems to be that dividing by the standard deviation seems to hurt backprop on following epochs. (Still unsure on why this spike occured)
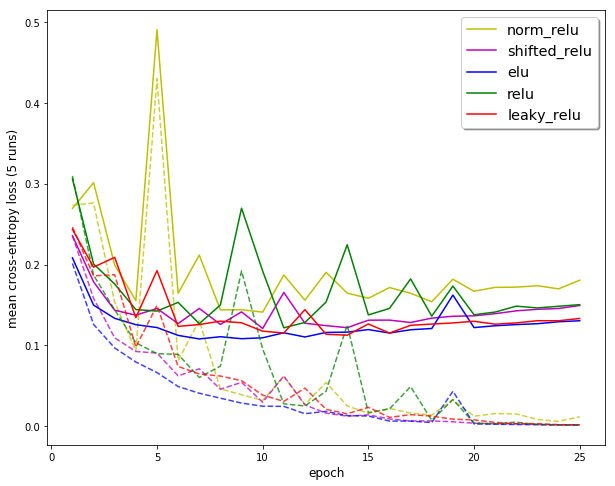
3 Likes
Here’s a blog post I wrote explaining how callbacks work and how to implement them in fast.ai. I’ll probably write a few more posts throughout the course.
2 Likes
Here are the blog posts on some of the initialization papers that we have been discussing so far:
- Instance Normalization: The Missing Ingredient for Fast Stylization paper
- Reducing BERT Pre-Training Time from 3 Days to 76
Minutes paper - Rethinking the Inception Architecture for Computer Vision paper
- Bag of Tricks for Image Classification with Convolutional Neural Networks paper
-
mixup: Beyond Empirical Risk Minimization paper
As the course progresses, I will continue writing posts on the research we are exposed to, each week.
3 Likes
Hello!
I have written a blog post about Text Generation on a home computer using fastai, and comparison to other approaches currently used, including GPT-2 (OpenAI’s).
I trained a TransformerXL on the Spanish Wikipedia and Published a Web App with both text generators in Spanish and English.
I appreciate your feedback!
6 Likes
Last weekend I created fastai_slack, a callback for getting Slack notifications while training FastAI models. Useful when you’re running training jobs for hours, and don’t want to keep staring at the screen.
You can check it out here:
- Jupyter notebook: https://jvn.io/aakashns/2e505d1a5e7b49e18e7849da3280b9da
- Github: https://github.com/swiftace-ai/fastai_slack
- Twitter: https://twitter.com/aakashns/status/1113069900396822529
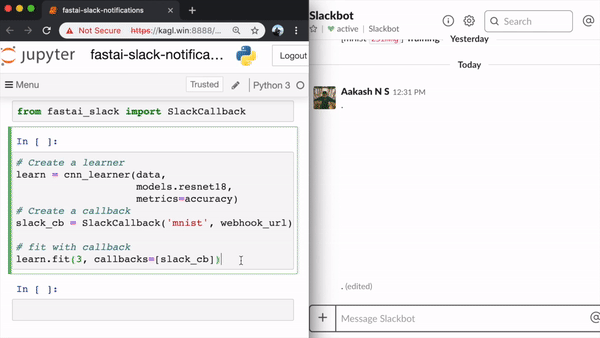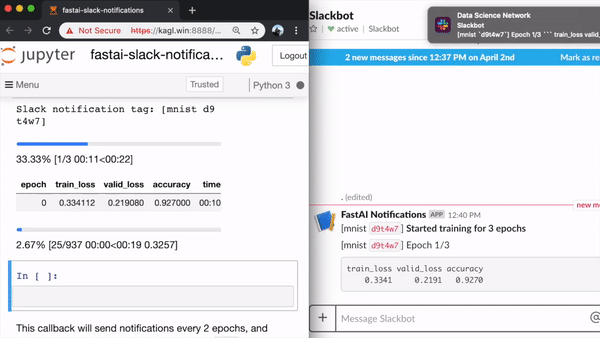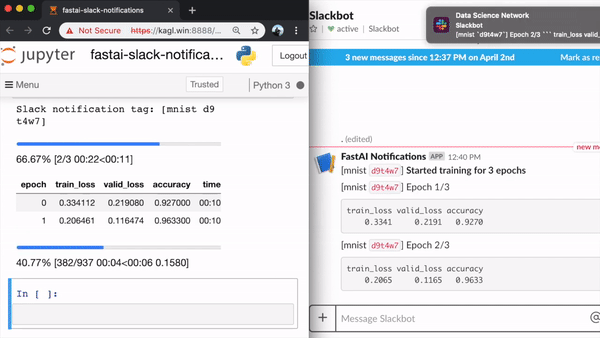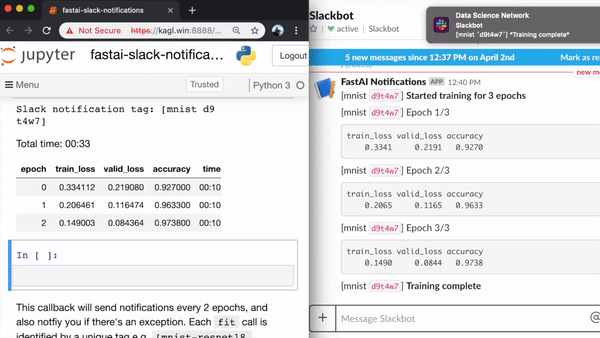
It sends notifications to your chosen Slack workspace & channel for the following events:
- Start of training
- Losses and metrics at the end of every epoch (or every few epochs)
- End of training
- Exceptions that occur during training (with stack trace)
It was actually a lot easier to implement than I imagined, thanks to FastAI’s excellent callback API. Around 80 lines of code (excluding docs).
26 Likes
I wrote about the new callback setup with the Runner class as explained in lesson 2:
The final callback code will look a bit different from what is presented in lesson 2, but this article still touches upon the core concepts. I’ll try to write mini updates that cover the changes in later lessons.
1 Like
Not directly related - but semi-related, I’ve written a blog post about setting up self-contained containers that have recreatable Python environments via Conda, along with VSCode and JupyterLab installed within the containers themselves.
With a fully working example here:
I’m a big fan of this approach since it lets me develop directly within the container environment, which makes it almost trivial to package up and deploy these containers in “production”. For every project I can easily jump into a fully specified environment, using VSCode and JupyerLab to develop as I would normally.
It should be pretty easy to modify to work with fastai - happy to write that up if anyone wants help/guidance with that.
5 Likes
Thnx to @alexli, @simonjhb, @ThomM, @zachcaceres
6 Likes
Ok… so I guess this would be in the unrelated category. Recently written a post on doing multivariate forecasting using random forest. Interestingly came across Jeremy’s work while researching on feature importance for RF (since being able to explain the model is a key objective in my task). Seems to be an under-appreciated topic imo.
I implemented Semantic Image Synthesis with Spatially-Adaptive Normalization (SPADE) by Nvidia which got state of the art results in Image to Image translation. It takes a segmentation mask and produces the colored image for that mask.
It is my first paper that I implemented completely from scratch and got promising results.
Link to repo
9 Likes
I’ve applied ULMFiT to several genomic datasets and shown improved performance over other published results. Currently working on a more long form writeup.
16 Likes
A guy in our study group recently wrote a Medium article on understanding 2d convolution based on CS231n and the paper by He et al 2015.
Felt that it could be of benefit to everyone, so I’m sharing it here with his permission.
An Illustrated Explanation of Performing 2D Convolutions Using Matrix Multiplications
2 Likes