I’ve adapted 2 new data augmentation techniques to be used with fastai (ricap and cutmix). Both of them have shown performance improvements resulting in SOTA in multiple datasets. Please, feel free to use them as you wish. You’ll be able to find here a notebook explaining how they can be used.
Some brief initial tests that I’ve run look promising.
If you are interested in this type of data augmentation, there’s some more info in this thread.
Data augmentation: dynamic blend
I’ve created a new notebook in my fastai_extensions repo to show how you can easily apply many different types of data transformation dynamically to your image datasets. I call this approach dynamic blend.
I’ve been lucky Jeremy’s (thanks!) seen it and came up with a much better definition that mine on Twitter:
This is a powerful abstraction for image data augmentation that generalizes MixUp, Cutout, CutMix, RICAP, and more, and allows annealing of the amount of augmentation during training (to support curriculum learning) - Jeremy Howard
If you are interested, you can start using it an ‘invent’ your own transformation. There’s more info in this thread.
Very interesting project and writeup, thanks! Just one remark: In your notebook you used random splitting into train/val sets, whereas the original paper used stratified splitting (same percentage of all classes). This may make quite a difference, so the comparison of the results may be off a little.
This competition seems like it might be fun to participate in. Also, regardless of the level of experience, I think anyone will find there an interesting problem to tackle. Just starting out? Which of the pretrained architectures performs best? How do you ensure your model is fully trained? A little bit more advanced topic would be how to combine predictions from multiple architectures. Here is a very good post on this subject.
A more advanced question would be how do you process the inputs to make them contain more information for your model to work with? I am quite sure there will be some posts on that on kaggle forums on this so it might be a good idea to keep an eye on them!
Thanks so much for making this starter pack! I am often overwhelmed by the amount of amount of extra knowledge one needs to learn just to get started on a competition. Like how to process the data files, make a fastai DataBunch, and create a submission. Your work definitely lowered the barrier to my getting started. Much appreciated!
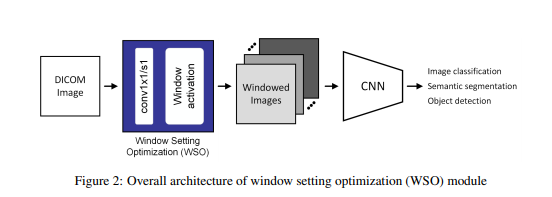
I had a question and comment on your 01_start_here notebook. (And maybe we should start a separate thread for discussing this competition.) As I understand it from the linked articles, the purpose of window center and width is to map the raw image data into 256 gray values that a human radiologist’s eye can distinguish. Different settings for center and width are used on the raw image in order to highlight various tissue types.
Therefore it does not make sense to impose a particular window on the raw image before the network sees it. The machine, unlike humans vision, is not limited to 256 contrast steps. Information outside the window will be thrown away by clipping, and including this information would likely help classification accuracy.
Of course, you would still want to normalize contrast and brightness somehow to meet the expectations of pre-trained resnet.
Let me know if this comment makes sense and let’s discuss.
should there be a separate thread for the RSNA intracranial challenge radek spoke about above?
here is my very much WIP repo using fastai v2 - i’m up to the point where i’ve built a multi-category databunch and now i need to train a model
it’s not well documented yet sorry. i built some descriptive csv files because they helped me do exploratory work on the metadata in the dicom files (the pixel metadata - not the patient metadata).
The data_prep notebook shows how to build them - the training notebook depends on them - i’m also not normalizing the image data the conventional way everyone else is - so i wouldn’t copy that part of my code - refer to the contest forum.
i think this is more of an example of creating a custom datatype for dicom files derived from PILImage and shows how some of the new api looks. I’m probably not following best practices - i’m still getting familiar w/ v2.
notebook assumes a symlink named “fai2” pointing to fastai_dev/dev/local in the repo folder
Hey Malcolm! Happy to hear you are finding the code helpful!
There are many interesting things that can be done with the input, I agree Do we even need to save the data to png files? Maybe it could be read directly from from the dicom files or alternatively the pixel_array could be saved to disk as a numpy array. Would this make doing some of the things you describe easier? Would exploring various options here add value at all? Does it make sense to start with pretrained models then or would models trained from scratch do better? Is there enough data for that? Would pretraining on a different dataset of dicom files make sense?
Many avenues to explore But I don’t want anyone to get intimidated - I think if one follows the starer pack, trains a couple of models maybe doing progressive resizing to whatever size their hardware permits and ensembles them in some straightforward fashion they might do really well in this competition. That is unless the stage 2 test set throws us a curve ball (who knows what they put in there). We have to rely on the organizers being reasonable (so far they seem to have done a great job on curating the dataset) - in my experience whenever the organizers think they are super tricky with the test set, it usually takes away a lot from the competition for the participants.
Either way - many of angles to explore, that is my point Probably many of things to blog about here as well or to add to one’s portfolio. May I say again how much I completely hate the idea of promoting myself, but this awesome post by Rachel puts a more positive light on the whole experience and shows how to go about it! I feel this competition can possible provide a lot of material to write about.
Anyhow - I have rambled for long enough One word of warning - I think Kaggle rules prohibit sharing code in private if you are not part of a team and probably some too indepth discussions might also go against the spirit of the competition. If anyone wants to discuss the competition in details, I would suggest doing so on Kaggle forums! Additionally, some of the folks there could probably provide great input into the discussion as well.
after doing the great Part 2, I made use of a lot of the teachings about Callbacks and other parts of the first 5 lessons, and I incorporated it all into my loss landscape project; over the months, the combination of fast.ai code applied to the Imagenette dataset, together with a workflow that included 3D visualization and post work, produced results which I´m beginning to rollout at the new web:
which is now in the rollout stage,
thank you fast.ai for the fabulous Part 2 and for inspiring us always