Yes in my early learning it was always said you don’t need feature engineering with neural networks because the engineering is a function of the network architecture. It turns out I am constantly reminded that statement does not hold true.
2 Likes
NB this isn’t part 2 related but thought I’d let you know my approach to the kaggle vsb partial discharge competition.
Nice heat maps by the way.
Writeup is here (I wish I know how to just post text link instead of these giant banners as below- I cant work out how people do this on a mobile)
2 Likes
Great work! I will look back through it!
Hi! I wrote a blogpost on All You Need is a Good Init. I was curious to why it worked mathematically so I dived into the math and hope I made the journey easier for someone. Feedback is appreciated!
EDIT: I also wrote blogposts summarizing Bag of Tricks for Image Classification with Convolutional Neural Networks and the paper on Kaiming/He initialization (with a small divergence into Xavier initialization). Check them out!
10 Likes
Hi Everyone, I have been working on classifying clinically actionable genetic mutations in cancer using lessons learned from Lesson 12 - ULMFit. The data is part of past Kaggle competition, hence it was interesting to benchmark the performance. Thanks!
Alena
2 Likes
This is excellent paper on tricks on DNN. I have implemented this on resent for tiny imagenet dataset and could able to reach 55% accuracy in 15 epoch…Before this with resnet was giving me only 27% accuracy in 50 epochs
Thanks for sharing the results of your exploration and experiment @maral 
While the std of layer outputs definitely expands as layers get deeper, I do wonder to what extent an “unlucky” initialization would impact model loss/metrics. In my experience, when training the same model from scratch successive times (with randomly chosen layer inits each time), while final validation loss is a bit stochastic and varies from one training to the next, I find that this variance is virtually always within acceptable constraints.
That said, if you’ve had a chance to code up a model that uses a voting scheme for inference, I’d be super excited to see how you went about designing the algorithm. It’d also be neat to see how its performance compares to a model that doesn’t use a voting scheme. And if the performance is indeed better, to what extent, if any, is there a trade-off of longer/more-expensive training.
1 Like
I guess it depends on the goal. If you want to minimise test loss the evidence suggests training the same model multiple times will improve generalisation which will improve test accuracy.
I did try the theory out and it worked for my case. I used Kaggle digits competition specifically for the reason there is a test set which is unknown to the network. I trained the same model 10 times for 40 epochs. I took the model with the lowest validation loss and this yield 99.442% accuracy on the test set. I then used all 400 models (I saved a model for each epoch), run the test set through each and averaged the probabilities. I tried a few different averaging methods (weighted based on validation loss, accuracy, etc). The unweighted average yield 99.528% accuracy. That is an 8.6% improvement. Something I did differently is not throw away the knowledge acquired from each epoch. This idea needs more experimentation. But, anecdotally it suggests every epoch helps.
My conclusion is not withstanding acquiring more data, data augmentation, trialing different network architectures and tuning hyper-parameters (all of which I avoided) predictive performance can benefit from two sources of randomness. The initialisation parameters and the shuffling of samples in each mini-batch. It would be interesting to test each independently.
So if you want to get a boost in predictive performance just train your model multiple times and average the probabilities across all epochs. However, I would only suggest this as the last step after implementing all the other tricks first 
I will post a colab notebook. I just need to clean it up.
Hey, I wrote this Medium post summarizing the section 4 of the Bag of Tricks for Image Classification with Convolutional Neural Networks paper, which basically describes the tweaks we can add to ResNets to get more accuracy without adding too much extra computational costs.
2 Likes
Hi, I wrote yet another blog about Kaiming weight initialization here. Discussed why it’s mandatory for convergence of your neural model and lots of math from the Kaiming paper. @PierreO and @jamesd blogs were extremely useful. This is my first blog and first paper which I read thoroughly. Any feedback is much appreciated.
6 Likes
Wrote a transfer learner that generates deep philosophical thoughts.
Currently building a twitter bot that tweets the thought of the day
1 Like
So, I tried doing the “A Swift Tour” lesson for Swift beginners, but… it suggested XCode? I couldn’t live with that, so I converted the xcode playgrounds to jupyter notebooks. To make it the most impractical I did the conversion itself in Swift (as I hadn’t written Swift before).
Anyways, you can find the notebooks here: https://github.com/mboyanov/aswifttour . Hope they help someone out
4 Likes
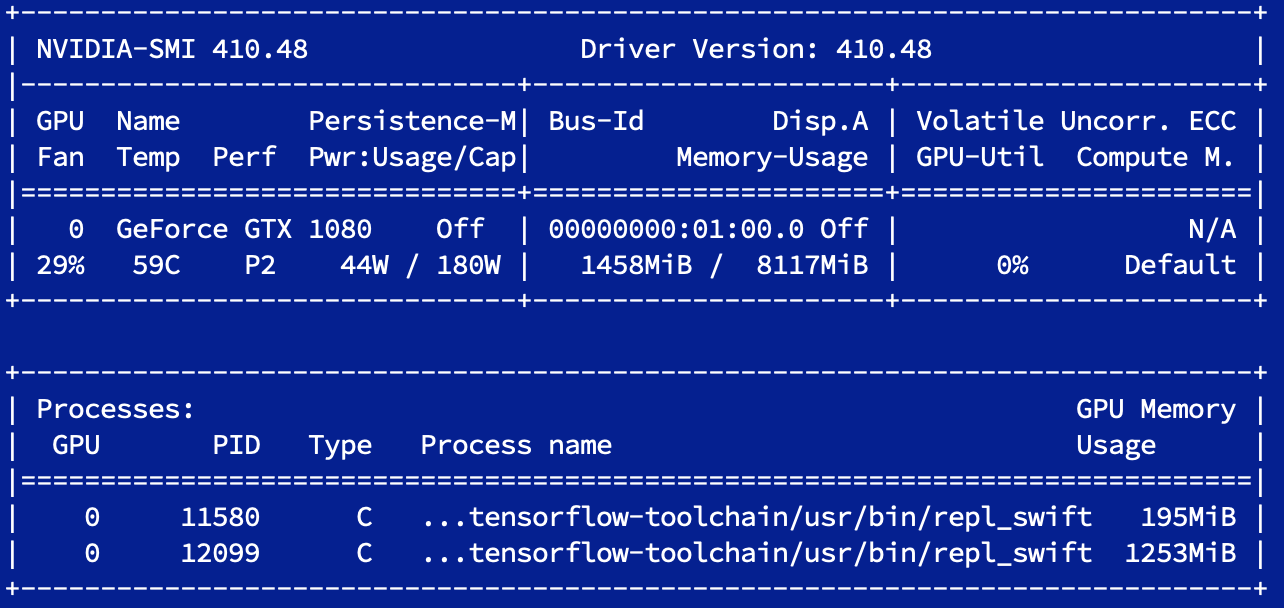
Swift fot Tensorflow using GPU on docker

The guide contains:
- Installation guide
- Custom startup script to use gpu on docker
- A script to ssh into your container
- nvidia-smi support
2 Likes
Great job! ![]()
Hey everyone. I wanted a project to strengthen my python. So me and some friends made Gradio.
It’s a python library that let’s ML developers share their model with collaborators and domain experts to be able to use it (and give them feedback!) without writing any code You can create an interface in three lines of code and it will generate a url. (model still running on your hardware!) This is what the url would show:

We added cool features like letting the domain expert crop his input, occlude some parts, or rotate it. And we just added saliency this morning.
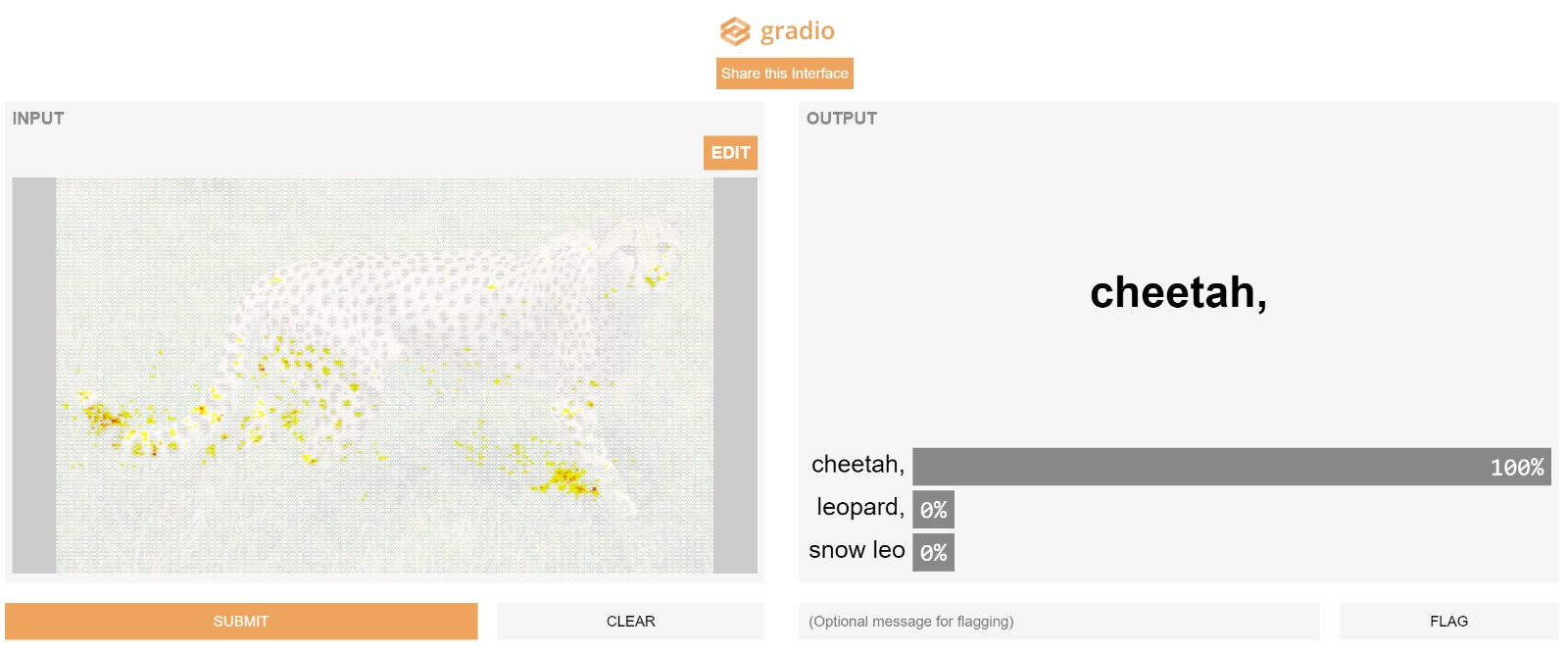
We also support text, image to image, audio, and sketchpad interfaces. Of course, the key feature is flagging.
We would love to hear some feedback.
Check out this example colab notebook
Check out documentation here
Check out our github
(if this belongs somewhere else, please let me know)
8 Likes
Maybe more of a Part 1 based project, but this is a project I’ve been working on for some of my graduate work. It is a segmentation network that proceeds through a whole CT dicom and highlights the four chambers of the heart.
The base segmentation is just Fastai’s unet implementation. This winds up working pretty well, but you can see sometimes it gets some stuff “wrong”.
The second row is an axial view of a cardiac scan. This is super informative and so it get’s things pretty much right, but things that are difficult to see in one axis are easy to see in another axis. So the first thing you have to do is resize everything to be consistent voxel sizes. Different DICOM scans usually have very different resolutions, especially in the z-axis (head to foot). The next thing I do is just average the outputs of the model evaluating on each plane in each axis.
Ground Truth / Predicted
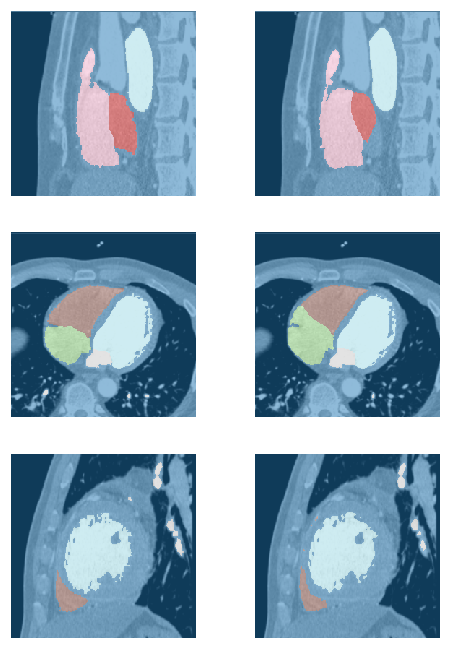
In the end you can make really cool 3D models of heart anatomy which I have gone ahead and 3D printed in one case.

From the inside of the heart, you can even see which parts are smoother or trabeculated. Pretty fun stuff! I hope you like it. Code is kind of bad and works on some restricted datasets, but I’m hoping to get this working on a public dataset and sharing everything I’ve written for it. If you have any recommendations let me know!
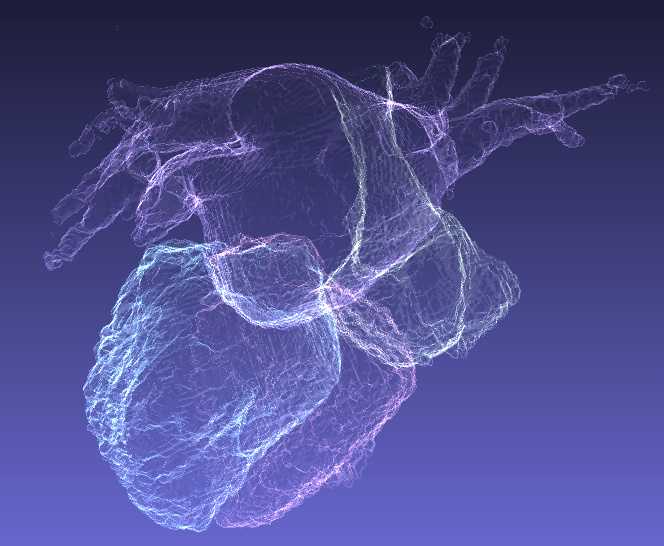
18 Likes
Looks very interesting! You have a labeled medical dataset with these regions highlighted, right? Are you allowed to share some properties about the data and the model, like images resolution, the number of channels, approximate size of the model, etc.? I wonder how long it could take to train this kind of model and which hardware resources one would need.
1 Like
Is the 3D image reconstructed from the predictions of the model on a bunch of 2D images of the same heart? (complete medical noob here)
Looks great, very nice job!
1 Like
I wrote a post explaining how LAMB works all the way from SGD, including an implementation and some toy dataset explorations.
Edit: Reddit post was deleted, use this instead:
1 Like